 支撑移动端高性能AI的幕后力量!谷歌提出全新高性能MobileNet V3
支撑移动端高性能AI的幕后力量!谷歌提出全新高性能MobileNet V3
支撑移动端高性能AI的幕后力量!谷歌提出全新高性能MobileNet V3,网络模型搜索与精巧设计的完美结合造就新一代移动端网络架构。
在刚刚过去的谷歌I/O上小伙伴对新发布的技术一定过足了瘾。支撑谷歌整合全球信息的AI被提到了至关重要的位置,从云到端,从安卓系统到移动设备无处不在的AI都显示出向善的力量。移动端作为与用户交流最为密切的设备,支撑它的AI技术正在飞速发展。为了实现更准确、更迅速更节能的移动端模型,在I/O大会召开的同日谷歌发表文章推出了最新一代移动端网络架构MobileNet V3,也许这就是为Pixels提供优异表现背后的力量。在最新的论文里,研究人员结合了网络架构搜索技术和新颖的架构设计实现了新一代的MobileNetV3,更适合移动端CPUs运行。新的模型在精度和延迟上进行了很好的平衡,并在图像分类、检测和分割上取得了超过V2版本15%~30%的速度提升。

V3两个版本的模型与先前模型在精度-速度上表现的对比(TFLite在单核CPU上测试)。
同时在相同的模型大小下取得了更好的精度。

V3模型在模型大小、操作与精度上表现与先前模型的对比。
随着AI的发展和落地,高效的神经网络逐渐成为了移动设备和app的标配。一个高效的模型实现不仅能带来顺滑的体验,更因为无需上传用户数据就能训练模型而增强了对于用户隐私的保护。除了带来低延时的使用体验,高效模型还为持久续行的移动设备节省了更多电能开销。(I/O大会上对于隐私的强调和长续航的Pixels手机也许就有这个mobileNetV3的贡献呢。)
在最新的论文中,研究人员提出了包含两个子版本的MobileNetV3(Large/Small)为移动端高精度高效率的计算机任务提供AI动力。新模型不仅拓展了移动端网络的能力边界,更在实现过程中将模型自动搜索方法和新颖架构设计有机结合起来,创造出高效准确的模型架构。为了构建高效的网络模型权衡精度和效率,研究人员设计了各设各样精妙的模型,同时也利用了自动化的大规模架构搜索来不断探索能力更强、效率更高的模型。这些精妙的设计不断提高了移动端模型的效率和精度。SqueezeNet开始模型的参数量就不断下降,为了进一步减少模型的实际操作数(MAdds),MobileNetV1利用了深度可分离卷积提高了计算效率,而v2则加入了线性bottlenecks和反转残差模块构成了高效的基本模块。随后的ShuffleNet充分利用了组卷积和通道shuffle进一步提高模型效率。CondenseNet则学习保留有效的dense连接在保持精度的同时降低,ShiftNet则利用shift操作和逐点卷积代替了昂贵的空间卷积。除了各种精巧的设计,研究人员们还请来的算法帮忙自动化设计和搜索网络模型。强化学习最先被引入这个领域,早期的工作主要集中在cell级别的结构搜索并复用所有层中,而最近的工作则拓展到了块级别的架构,模型探索不同的层结构和不同分辨率的块结构来构建网络。此外网络模型的剪枝和量化也是提高效率的重要途径。在这些技术的加持下,Google的研究人员开始着手构建更强大的v3模型。在充分研究了v1版本的深度可分离模块、v2版本的线性瓶颈和反转残差、MnasNet中的序列激活结构后,综合了三种结构的优点设计出了高效的v3模块,并利用了改进后的swish作为激活函数,使得后续的量化和效率提升更为有效。在构建v3版本模块的过程中研究人员主要进行了网络搜索和模型改进两个部分,自动和手动的协同工作得到了更为先进的模型架构。
网络搜索
对于模型结构的探索和优化来说,网络搜索是强大的工具。研究人员首先使用了神经网络搜索功能来构建全局的网络结构,随后利用了NetAdapt算法来对每层的核数量进行优化。对于全局的网络结构搜索,研究人员使用了与Mnasnet中相同的,基于RNN的控制器和分级的搜索空间,并针对特定的硬件平台进行精度-延时平衡优化,在目标延时(~80ms)范围内进行搜索。随后利用NetAdapt方法来对每一层按照序列的方式进行调优。在尽量优化模型延时的同时保持精度,减小扩充层和每一层中瓶颈的大小。
网络改进
在机器搜索得到网络架构的基础上,研究人员引入了诸多新型的结构来提升模型的最终效果。不仅重新设计了网络头和尾的计算密集层,同时还引入了新的非线性激活h-swish,提升计算和量化能力。mobileNetV2模型中反转残差结构和变量利用了1*1卷积来构建最后层,以便于拓展到高维的特征空间,虽然对于提取丰富特征进行预测十分重要,但却引入了二外的计算开销与延时。为了在保留高维特征的前提下减小延时,将均值池化前的层移除并用1*1卷积来计算特征图。特征生成层被移除后,先前用于瓶颈映射的层也不再需要了,这将为减少10ms的开销,在提速15%的同时减小了30m的操作数。

同时在模型的前端,32个3*3的卷积通过h-swish非线性在保持精度的情况下压缩到了16个卷积核,又减小了10m操作和3ms的开销。

对于非线性激活函数,swish虽然很有效但在移动端运行开销很大,研究人员从两个方面着手解决这一问题。一方面利用了hard(硬)版本的激活函数:
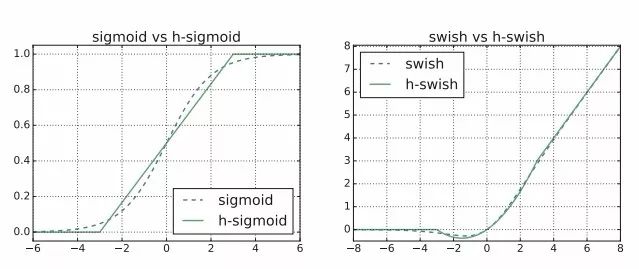
这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。这一非线性改变将模型的延时增加了15%。但它带来的网络效应对于精度和延时具有正向促进,剩下的开销可以通过融合非线性与先前层来消除。另一方面,研究发现非线性使用带来的开销会随着网络深度的加深而减小,所以研究人员将在后半部分较深的层中使用以减小开销。研究人员提出了一大一小两个模型,分别针对不同级别计算资源的硬件平台。下表展示了两种不同模型的架构。可以看到先前提到的h-wish集中在后半部分。
分类、检测、分割验证模型能力提升
为了验证新模型的精度与效率,研究人员分别在图像分类、目标检测和实例分割任务上进行了测试,指标全面提升。首先来看ImageNet上的分类结果:

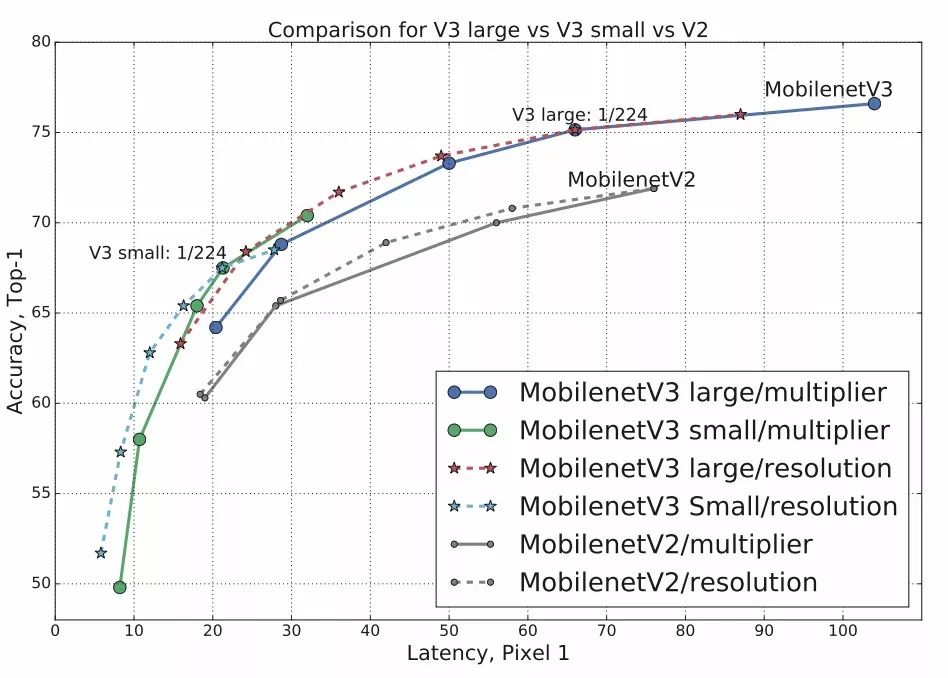
可以看到large版本的模型在精度、操作数上都得到了提升,特别是延时缩短了很多。研究人员还研究了网络中的乘数因子与分辨率对精度和延时造成的影响:
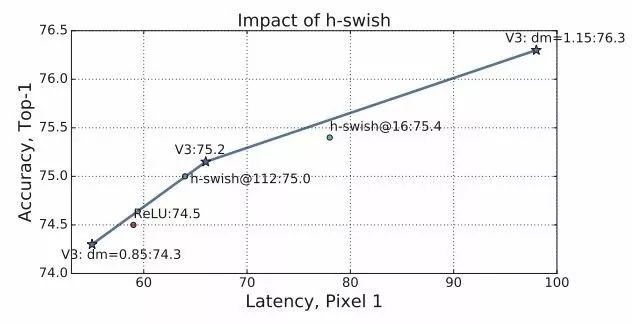
此外还进行了消融性测试,分别分析了h-swish和各个部件对于模型精度延时的影响:

随后在COCO数据集上基于V3实现的SSDLite进行了目标检测任务的评测,可以看到map提升或者延时大幅下降了,100ms左右即可完成目标检测:

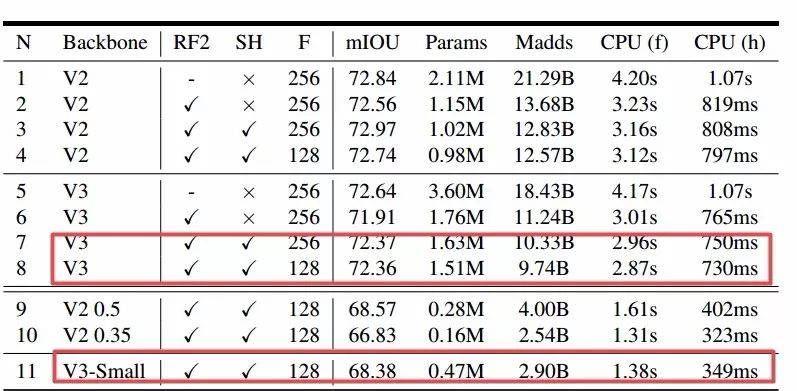
最后还在Cityscape实例分割任务上进行了测试。研究人员还提出了新的轻型R-ASPP (reduced design of the Atrous Spatial Pyramid Pooling)模块用于分割头的架构。一个分支用了很大的池化核和大步长节省计算量,另一个分支只用了1*1卷积抽取稠密特征,并加入了底层特征来捕捉更多的细节信息。下图显示了减半输出滤波器数量、改变分割头、改变输出步长情况下的实例分割结果,可以看到通过各种性能提升,可以在CPUs上实现400ms左右的分割。

目前github已经能搜到两个v3版基于PyTorch代码实现:
https://github.com/AnjieZheng/MobileNetV3-PyTorchhttps://github.com/leaderj1001/MobileNetV3-Pytorch
其中模型定义在model.py/mobilenet_v3.py中,感兴趣的小伙伴可以尝试下新版本的MobileNet香不香?配合论文学习,理论联系实际学得快记得牢!
-
谷歌
+关注
关注
27文章
6161浏览量
105295 -
强化学习
+关注
关注
4文章
266浏览量
11245 -
ai技术
+关注
关注
1文章
1266浏览量
24284
原文标题:首发 | 精度、速度、效率、性能全面提升!揭秘谷歌最新一代移动端网络架构MobileNet V3
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐







Firefly支持AI引擎Tengine,性能提升,轻松搭建AI计算框架
基于ZU3EG的低功耗高性能嵌入式AI高性能计算模组
AutoKernel高性能算子自动优化工具
全新高性价比STM32H5让性能和安全触手可及
德州仪器推出全新高性能DSP
全新高性能 Sitara™︎ AM263 MCU 如何发挥电气化设计的全部潜能






 工商网监
工商网监
评论