 训练一个机器学习模型,实现了根据基于文本分析预测葡萄酒质量
训练一个机器学习模型,实现了根据基于文本分析预测葡萄酒质量
爱酒人士应该都知道,选红酒是个需要大量知识储备的技术活——产地、年份、包装、饮用场合,每个元素的变化都会对口感产生一定的影响。
TowardsDataScience上一位作者(同时也是轻度葡萄酒饮用者)用一组Kaggle的数据集撰写了一个可以帮忙在网上选红酒的AI小程序。
该数据中包含对葡萄酒的评论,葡萄酒评级(以分数衡量),以及从WineEnthusiasts网站提取的其他相关信息。他通过训练一个机器学习模型,实现了根据基于文本分析预测葡萄酒质量。
数据集按照日期被划分为两组数据文件。一组作为训练集,把一组作为测试集。
以下是整个训练过程,一起看看。
目标:训练一个机器学习模型,实现基于文本分析的葡萄酒质量预测
WineEnthusiast的用户会对葡萄酒评分,1表示最差,100表示最好。不幸的是,传到网站上的都是正面评论,所以数据集里分数值只分布在80-100之间。
这意味着我们所用的这套数据并不能很好反应我们在探索的问题。因此,基于这套数据所建立的模型只适用于评论较好的酒。在进行分析之前,我们还是得先预习一些圈内基本知识。通过从阅读葡萄酒网站及一些相关资源,我找到一种自认为不错的分级方案,按照评分进行分级。如下所示。

对于一个最终用户(白话说就是买葡萄酒的),评分就是他们想要传达的信息。如果我们按照上述划分形式,我们就能既减少了葡萄酒信息维度又能保留住质量相关信息。
重要决定:我把这个问题定义为一个倾向性分析问题,基于用户评价判断葡萄酒属于Classic(典藏酒)、Superb(豪华酒)、Excellent(酒中上品)、Very Good(优质酒)、Good(好酒)及Acceptable(凑合吧)中的哪个等级。
实现:探索式分析
在这步中,我们会一点点深入理解数据。数据探索能够给我们带来更多解决问题的灵感。数据集中除了评论和评分,还有其他信息,如葡萄酒价格、品类(葡萄品种)及产地等。
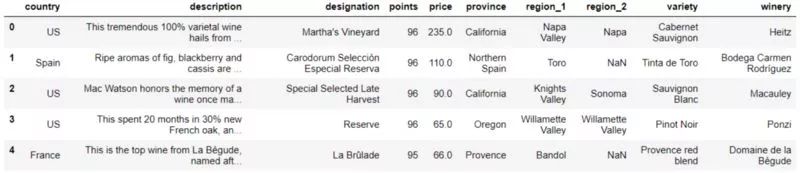
数据预览
我们可以把上述的其他信息也引入作为特征参数,这样就能构建出一个更全面的模型来预测葡萄酒质量。为了将文字描述与其他特征结合起来进行预测,我们可以创建一个集成学模型(文本分类器就是集成在内的一部分);也可以创建一个层级模型,在层级模型中,分类器的输出会作为一个预测变量。
出于此目的,我们仅研究一下评论与葡萄酒评分之间的关系。
全面地查看数据完整性
评分和评论描述这两列数据是完整的。前文提到过,葡萄酒的评分相对都比较高。所以,以我的经验看来,价格也会比较高。
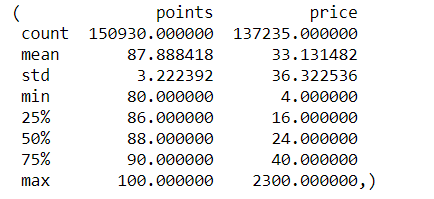
data.describe()的输出结果
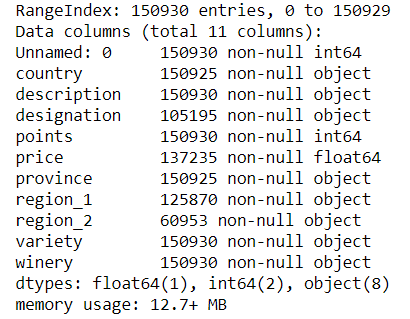
data.info()的输出结果
查看文本数据
评论的内容看似来都很清晰。没有出现任何语法和拼写错误,而且评论的言语都比较简洁。请看示例:
这款由纯葡萄酿制的精品干红来自奥克维尔酒庄,并在木桶中足足陈酿3年。当如红樱桃汁般的果味遇上浓烈的焦糖味,再在精致柔和的单宁的作用下,并散发着微微薄荷香,真是令人垂涎。综合从酿造开始至今的各项数据,它还值得再存放几年使其越陈越香,推荐品尝时间2022年-2030年。
还是得有一定的葡萄酒知识才能完全读懂一些评论。上述示例中,“单宁”是一种能使得葡萄酒口感很干的一种成分。
下图中我能看到这些常用术语的出现频率。
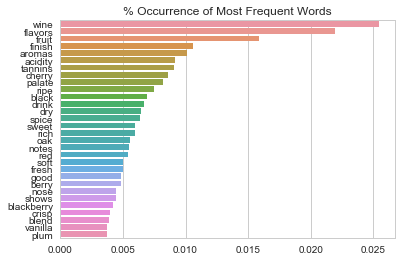
最常出现的词就是“Wine”,出现频率超过了0.025%
分类前的准备工作
所以,我们可以通过评分,将评论和我们所分的等级关联起来。但不巧的是,我们的数据并不是很平衡。
没有落在第4级内的评论,大部分评论都落在第1-3级中。数据分布不均虽然是个问题,但还是可以通过细分类别或者设置类别权重来处理。可是,某个类别完全没数据,这可得好好想想办法了。
重要决定:我把第5级和第4级合成一级,这里评分在94-100中的评论就都在这个级别里了。
有必要清洗文本数据吗?
我们可以考虑一下要不要对葡萄酒的评论信息进行清洗或者标准化。做不做这事主要取决于我们所使用的学习算法。如果我们想把每条评论转化成一个向量并作为一对一分类器的输入,那就得花大量的时间进行文本的标准化处理。另一种方式,如果以多向量的形式顺序处理文本内容,就用不着过多的标准化了。
顺序处理文本(通常每个单词都有对应的向量,且对应关系都很明确)有利于词义消歧(一个单词有多种含义)和识别同义词。因为评论都是关于葡萄酒的,其中所提到的专业术语语境基本一致,所以我不太在意词义消歧和识别同义词的问题。但是由于评论的内容都比较正面,我当心一对一分类器很难区分出相邻两个类别之间的微妙差异。
重要决定:我要使用递归神经网络模型,把每条评论转化为向量序列传到模型中进行预测。这样我也就保留了文本的原始形式。
相较于使用TF-IDF等方式将文本转为词向量传到一对一分类器中,我所选的就会一定更优吗?这并不好说。不过,这可以留到以后试试再作比较。
文本向量化
基于神经网络的单词向量化通常可以使用word2vec、GloVe和fastText。对此,我们可以选择使用自己定义的词向量映射模型或是预先训练好的模型。由于我们要处理的文本没有异常语意,所以我们直接使用训练好的词向量模型来理解文字即可。
重要决定:使用预先训练好的词向量模型。
但是该使用哪种词向量映射模型?首先排除掉fastText方案,因为它是通过对单词的n-gram等级求和来构建词向量的。而我们处理的文本中不太可能包含标准单词表以外的词汇(没有拼写错误、俚语、缩写),所以fastText这种方案没什么优势。
重要决定:使用训练好的GloVe词向量。
我们可以下载一些已经训练好的词向量。我选用已经标记好的Common Crawl数据集,它包含大量词汇且区分大小写,名为300d的词向量包含300个维度。
在加载预先训练好的嵌入之前,我们应该定义一些固定的参数,另外还需下载一些必备的库文件以及将类别进行one-hot化编码。
分割训练集和验证集
即使我们已经有了指定的测试集,我们也最好把训练数据分为训练集和验证集,因为这有助于调参。
我将使用Keras库中的text_to_sequences函数来保留文本中的单词序列。同时,每个单词会根据预先训练好的词向量模型映射为词向量。不足100(max_len)个单词的序列会填充到100个,超过100(max_len)个单词的序列只截取100个,这样学习算法的输入向量长度就一致了。
如果文本中出现了生僻的单词(没在训练好的词向量模型中),它们会被设定为0向量。
注:如果有大量单词不在模型的词库中,那我们得找个更智能的方式来初始化这些单词。
训练分类器
由于文本的内容通常比较短,我将选择使用GRU网络,而不用LSTM。这样,文本内容越短,我们对内存的开销就越少,而且GRU还能使学习算法效率更高。
我还会使用到早停法,这种方式可以通过验证集的准确率来判断是否要继续训练网络。当验证集的准确率在几次训练后呈现为持续下降,早停法就会生效以停止训练。该方法还会将最有权重保存为“checkpoint”(就是本例中的model.h5),当准确度提升后还会更新权重。使用早停法,我们大可对网络进行多次训练,而不必担心出现过拟合。
patience这个参数可以理解为一个阈值,用来判断是否要提前结束训练。patience=3,意味着如果对全样本进行3次训练后仍没有减少损失函数,则执行早停。
递归神经网络的结构比较简单。其结构里依次包含着有50个神经元的双向GRU层、池化层、全连接层、dropout层。双向则意味着网络能按照单词出现的正序和逆序都进行学习。
分类器还需优化一下对准确率这个指标的定义。因为准确率无法辨别出人类两种误判中的差别。对于人的判断而言,把0级酒预测为4级酒可能比把0级酒预测为1级酒要糟糕得多。对神经网络的判断而言,却看不出差别。在未来的实践中,可以设计一个指标来反映两者的关系。
是时候评估模型了——祭出我们的测试集
准确率高达64%!
请看下图中的混淆矩阵。从矩阵中,数值以百分比的形式反映出我们样本数据中的数据不平衡。
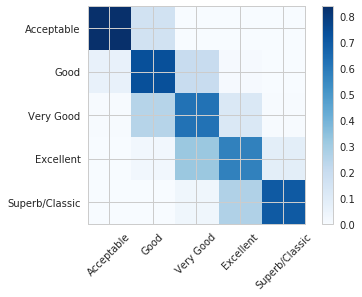
必须记住的是,由于数据样本中关于葡萄酒的评论都比较正面,所以这个分类器仅适用于评价较好的葡萄酒。如果未来能拿到一些不一样数据来尝试,结果想必也会很有意思。
- 模型
+关注
关注
1文章
2998浏览量
48210 - 机器学习
+关注
关注
66文章
8293浏览量
131648 - 数据集
+关注
关注
4文章
1197浏览量
24510
原文标题:如何在网上选到一瓶心仪的红酒?通过文本分析预测葡萄酒的质量
文章出处:【微信号:BigDataDigest,微信公众号:大数据文摘】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
50多种适合机器学习和预测应用的API,你的选择是?(2018年版本)
改进粒子群优化神经网络的葡萄酒质量识别
基于深度神经网络的文本分类分析

融合文本分类和摘要的多任务学习摘要模型

基于不同神经网络的文本分类方法研究对比
基于LSTM的表示学习-文本分类模型
NLP中的迁移学习:利用预训练模型进行文本分类
如何基于深度学习模型训练实现圆检测与圆心位置预测

如何基于深度学习模型训练实现工件切割点位置预测






 工商网监
工商网监
评论