 如何有效处理大规模用户数据进行广告推荐?
如何有效处理大规模用户数据进行广告推荐?
如何有效处理大规模用户数据进行广告推荐?对于互联网企业的发展和进步至关重要。这也是为何快手成立西雅图实验室并实现新一代GPU广告模型训练平台的原因之一。快手新创建的“Persia”GPU广告模型训练平台比起传统CPU训练平台,单机训练速度提升可达几百倍,在约一小时内即可训练百T级别数据量,并能通过设计算法得到相对于传统训练平台精度更高的模型,对企业收入、计算资源的节约和新模型开发效率产生直观的提升。
大模型GPU分布式运算存储
近年来,GPU训练已在图像识别、文字处理等应用上取得巨大成功。GPU训练以其在卷积等数学运算上的独特效率优势,极大地提升了训练机器学习模型,尤其是深度神经网络的速度。然而,在广告模型中,由于大量的稀疏样本存在(比如用户id),每个id在模型中都会有对应的Embedding向量,因此广告模型常常体积十分巨大,以至于单GPU无法存下模型。目前往往将模型存在内存中,由CPU进行这部分巨大的Embedding层的运算操作。这既限制了训练的速度,又导致实际生产中无法使用比较复杂的模型——因为使用复杂模型会导致对给定输入CPU计算时间过长,无法及时响应请求。
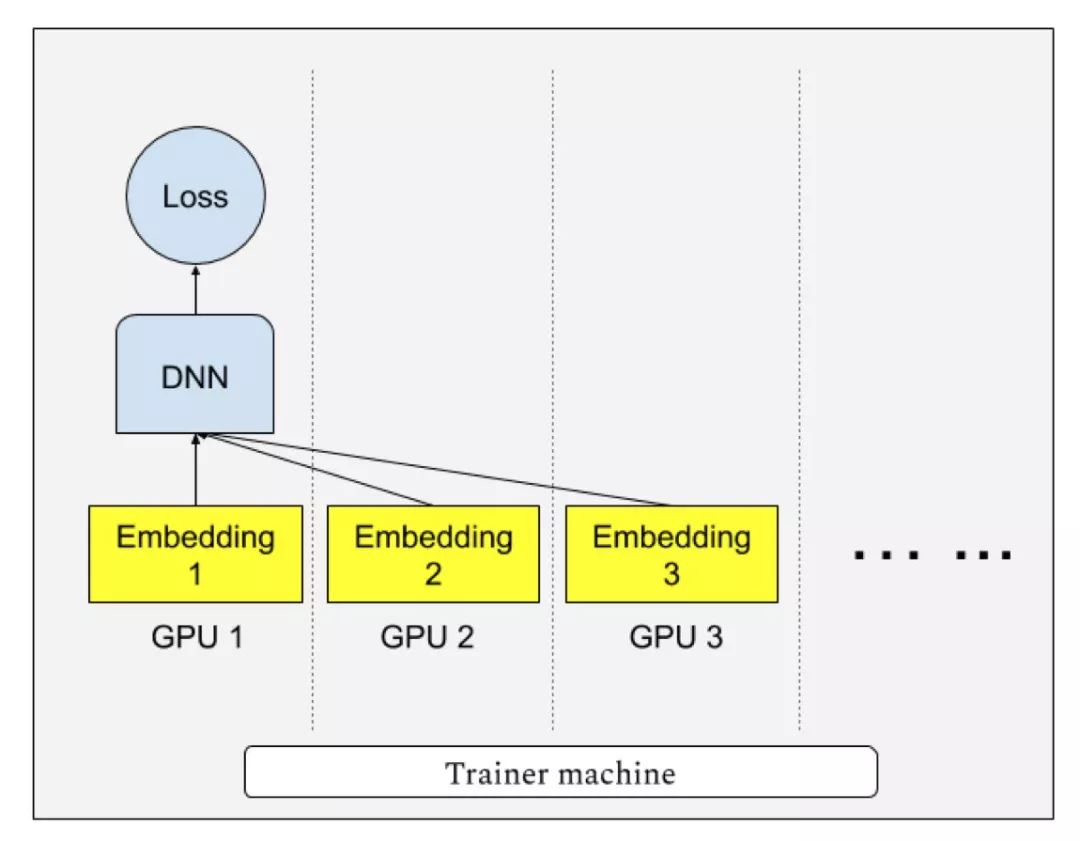
“Persia”系统实现了多GPU分散存储模型,每个GPU只存储模型一部分,并进行多卡协作查找Embedding向量训练模型的模式。这既解决了CPU运算速度过慢的问题,又解决了单GPU显存无法存下模型的问题。当模型大小可以放入单个GPU时,“Persia”也支持切换为目前在图像识别等任务中流行的AllReduce分布训练模式。据研究人员透露,对于一个8GPU的计算机,单机数据处理速度可达原CPU平台单机的640倍。
由于普遍使用的传统异步SGD有梯度的延迟问题,若有n台计算机参与计算,每台计算机的梯度的计算实际上基于n个梯度更新之前的模型。在数学上,对于第t步的模型xt,传统异步SGD则更新为:
xt+1←xt − learning rate × g(xt−τt),
其中g(xt−τt) 是训练样本的损失函数在τt个更新之前的模型上的 梯度。而τt的大小一般与计算机数量成正比:当计算机数量增多,xt−τt与xt相差就越大,不可避免地导致模型质量的降低。“Persia”的训练模式解决了这种梯度延迟的问题,因此模型质量也有所提升。
同时,“Persia”训练系统还支持对Embedding运算在GPU上进行负载均衡,使用“贪心算法”将不同Embedding均匀分散在不同GPU上,以达到均匀利用GPU的目的。给定k个 GPU,当模型具有m个Embedding层:e1, e2, …, em,对应负载分别为l1, l2, …, lm,“Persia”将会尝试将Embedding分为k组S1, S2, …, Sk,并分别存放在对应GPU上,使得每组∑i∈Sjli, ∀j大致相等。
训练数据分布式实时处理
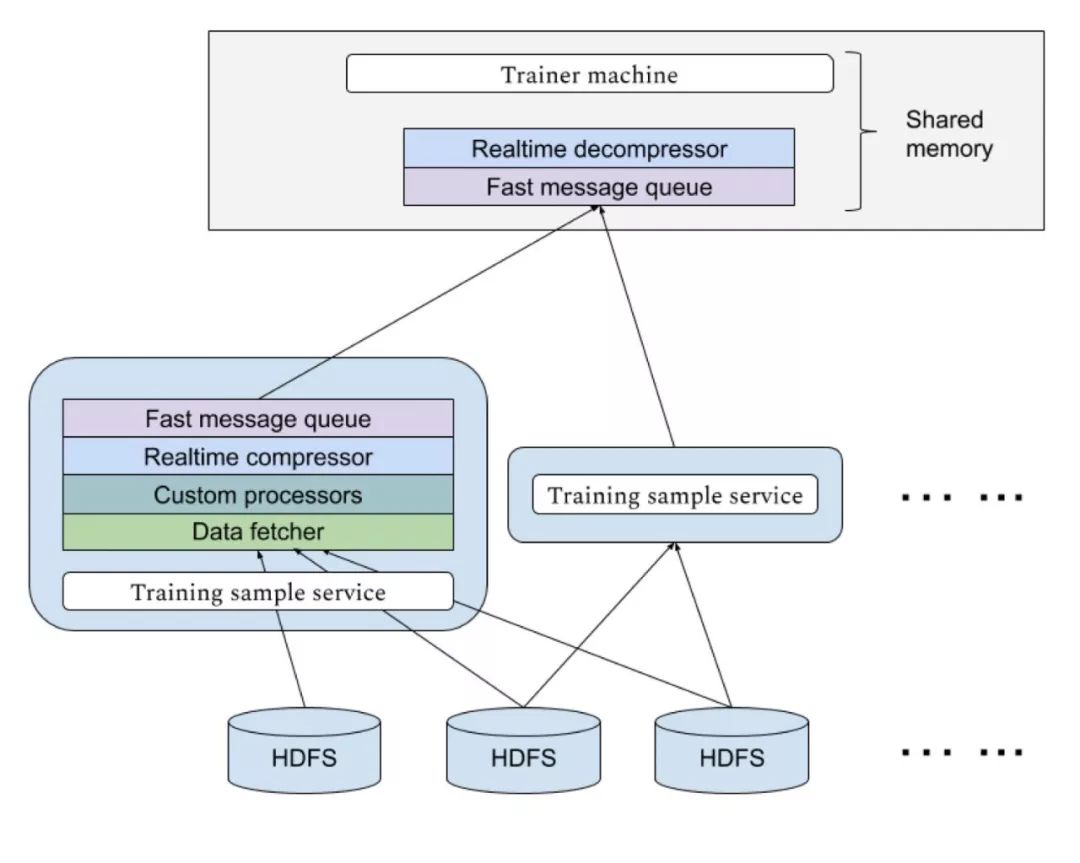
快手“Persia”的高速GPU训练,需要大量数据实时输入到训练机中,由于不同模型对样本的需求不同,对于每个新实验需要的数据格式可能也不同。快手“Persia”系统具备基于Hadoop集群的实时数据处理系统,可以应不同实验需求从HDFS中使用任意多计算机分布式读取数据进行多级个性化处理传送到训练机。传输使用高效消息队列,并设置多级缓存。传输过程实时进行压缩以节约带宽资源。
未来:分布式多机训练
未来,快手“Persia”系统即将展开分布式多GPU计算机训练。有别于成熟的计算机视觉等任务,由于在广告任务中模型大小大为增加,传统分布式训练方式面临计算机之间的同步瓶颈会使训练效率大为降低。“Persia”系统将支持通讯代价更小,并且系统容灾能力更强的去中心化梯度压缩训练算法。
快手FeDA智能决策实验室负责人刘霁介绍,该算法结合新兴的异步去中心化训练 (Asynchronous decentralized parallel stochastic gradient descent, ICML 2018)和梯度压缩补偿算法(Doublesqueeze: parallel stochastic gradient descent with double-pass error-compensated compression, ICML 2019), 并有严格理论保证。据预计,快手“Persia”系统在多机情景下在单机基础上将有数倍到数十倍效率提升。
-
cpu
+关注
关注
68文章
10854浏览量
211570 -
gpu
+关注
关注
28文章
4729浏览量
128890 -
机器学习
+关注
关注
66文章
8406浏览量
132558
原文标题:单机训练速度提升高达640倍,快手开发GPU广告模型训练平台
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论