 什么是异常检测_异常检测的实用方法
什么是异常检测_异常检测的实用方法
什么是异常检测?
异常检测是一个发现“少数派”的过程,由于它们与大多数数据不一样而引起我们的注意。在几个典型场景中,异常数据能为我们关联到一些潜在的问题,如银行欺诈行为、药品问题、结构缺陷、设备故障等。这些关联关系能帮助我们挑出哪些点可能是异常的,从商业角度来看,查出这些事件是非常有价值的。
这样就引出我们的主要目标:我们如何分辨每个点是正常还是异常呢?在一些简单的场景中,如下图所示,数据可视化就可以给出重要信息。
图 1:两个变量的异常
在这个二维数据(X 和 Y)的例子中,判断异常点是非常容易的,只需要观察数据点在二维平面上的分布即可。然而,观察右图可以发现,只观察一个变量是无法看出异常的,只有把变量 X 和变量 Y 结合起来观察,才能发现异常点。当我们把数据维度从 2 提升到 10-100,这件事情就极其复杂了,实际场景的异常检测也是如此。
什么是状态监控?
无论任何机器,旋转电机(泵、压气机、燃气或蒸汽轮机等)或非旋转机器(热交换器、分裂蒸馏塔、阀门等),都会最终出现运转异常的情况。出现这种情况时,机器并不一定是彻底坏掉了,可能只是无法以最佳状态运转,它可能需要进行维修以恢复完全的运转能力。简而言之,识别设备的“健康状态”就是状态监控领域所研究的问题。
在状态监控中,最常用的方法是观测机器的每个传感器,并对其设置一个最小值和最大值。如果当前值在所设置范围之内,说明机器运转正常。如果当前值超出范围,系统会给出预警信号,提醒机器运转不正常。
对机器硬性施加报警阈值这一过程,会导致系统发出大量假的预警信号,即机器运转正常时却收到了异常报警。同时也存在预警信号遗漏的问题,即机器运转异常却没有收到警示。第一个问题不仅浪费时间精力,也影响机器寿命。第二个问题更为严重,可能导致机器损坏,进而损失大量维修费用和生产损失。
而两个问题都源于一个原因:设备的健康程度是一个高维的复杂问题,不能依赖于某个单独的指标进行判断(和图 1 展示的异常检测问题同理)。我们必须结合考虑多个检测值,从而获得一个更为真实的信号。
主要方法
说到异常检测,很难把机器学习和统计分析全部覆盖,我会避免在理论知识上过于深入(但会提供一些有详细介绍的链接)的同时介绍一些常用方法。如果你对机器学习和统计分析在状态监控方面的实际应用更感兴趣,可以往下看“状态监控实例”部分。
方法一:多变量统计分析
使用主成分分析法进行降维:PCA
处理高维数据总是充满挑战的,减少变量个数(降维)的方法有很多。其中最主要的方法是主成分分析法(PCA, principal component analysis),该方法将数据映射到一个低维空间,使数据在低维空间的方差最大化。在实际应用中,需要建立数据的协方差矩阵,并计算矩阵的特征向量。对应最大特征值(即主要成分)的特征向量可用作重新构建原数据集。如今原特征空间被减小了(部分数据丢失了,但保留了最重要的信息),得到了由部分特征向量构成的空间。
降维:
https://en.wikipedia.org/wiki/Dimensionality_reduction
PCA:
https://en.wikipedia.org/wiki/Principal_component_analysis
协方差矩阵:
https://en.wikipedia.org/wiki/Covariance_matrix
特征向量:
https://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectors
多变量异常检测
当处理单变量或两个变量的异常检测时,数据可视化常常是一个好的方法。然而,当拓展到高维数据时(同时也是大多数实际应用中的情况),这种方法就会极其难处理。幸运的是,多变量分析可以帮得上忙。
当处理一个数据点的集合时,这些点会有典型的特定分布(如高斯分布)。要想定量地检测异常点,我们要先计算数据点的概率分布 p(x)。之后出现新的点 x,我们就可以用 p(x) 与阈值 r 作对比了。如果 p(x)
状态监控场景中的异常检测很有趣,因为异常可以告诉我们有关被监控设备是否“健康”的讯息:当设备临近故障或非最优操作所产生的数据,与设备正常运转所产生的数据在分布上不同。
多变量统计/多元统计:
https://en.wikipedia.org/wiki/Multivariate_statistics
高斯分布:
https://en.wikipedia.org/wiki/Normal_distribution
概率分布:
https://en.wikipedia.org/wiki/Probability_distribution
马氏距离
试考虑一个数据点是否属于某一分布的概率问题。第一个步骤是找到质心或者说样本点的质量中心。直观上来看,该点离质心越近,越可能属于这个集合。然而,我们也要注意该集合的范围大小,这样我们才能判断给定的离质心的距离是否值得注意。简化的方法是去估计样本点与质心距离的标准差。将其插入标准分布中,我们可以得出数据点是否属于同一分布的概率值。
上述方法也存在缺陷,我们假设了样本点相对于质心是球形分布的。如果它们的分布不是球状的,而是椭圆状的,我们在判断测试点是否属于该集合时,不仅要考虑与质心的距离,还要考虑方向。在那些椭圆短轴的方向上,测试点的距离一定更近,但那些长轴方向上测试点是远离质心的。从数学角度看,我们可以通过计算样本的协方差矩阵,来估计出最能代表集合分布的椭圆。马氏分布是指从测试点到质心的距离除以椭圆在测试点方向上的宽度。
为了使用马氏距离来判别一个测试点属于 N 个分类中的哪一个,首先应该基于已知样本与各个分类的对应情况,来估计每个类的协方差矩阵。在我们的例子中,我们只对“正常”和“异常”两个类别感兴趣,我们使用只包含正常操作状态的数据作为训练数据,来计算协方差矩阵。接下来,拿来测试样本,计算出它们与“正常”类别的马氏距离,如果距离高于所设置的阈值,则说明该测试点为“异常”。
马氏距离:
https://en.wikipedia.org/wiki/Mahalanobis_distance
方法二:人工神经网络
自动编码器网络
第二种方法是基于自动编码器神经网络。它的基本思想与上面的统计分析相似,但略有差异。
自动编码器是一种人工神经网络,通过无监督的方式学习有效的数据编码。自动编码器的目的是学习一组数据的表示(编码),通常用于降维过程。与降维的一层一起,通过学习得到重建层,自动编码器尝试将降维层进行编码,得到尽可能接近于原数据集的结果。
在结构上,最简单的自动编码器形式是前馈非循环神经网络,与许多单层感知器类似,它们构成了包含输入层、输出层和用于连接的一个或多个隐藏层的多层感知器(MLP, multilayer perceptron),但输出层的节点数与输入层相同,目的是对自身的输入进行重建。
自动编码器:
https://en.wikipedia.org/wiki/Autoencoder
人工神经网络:
https://en.wikipedia.org/wiki/Artificial_neural_network
有效数据编码:
https://en.wikipedia.org/wiki/Feature_learning
无监督:
https://en.wikipedia.org/wiki/Unsupervised_learning
多层感知器:
https://en.wikipedia.org/wiki/Multilayer_perceptron
图2:自动编码器网络
在异常检测和状态监控场景中,基本思想是使用自动编码器网络将传感器的读数进行“压缩”,映射到低维空间来表示,获取不同变量间的联系和相互影响。(与 PCA 模型的基本思想类似,但在这里我们也允许变量间存在非线性的影响)
接下来,用自动编码器网络对表示“正常”运转状态的数据进行训练,首先对其进行压缩然后将输入变量重建。在降维过程中,网络学习不同变量间的联系(例如温度、压力、振动情况等)。当这种情况发生时,我们会看到通过网络重构后的输入变量的异常报错增多了。通过对重构后的报错进行监控,工作人员能够收到所监控设备的“健康”信号,因为当设备状态变差时,报错会增多。与基于马氏距离的第一种方法类似,我们在这里使用重建误差的概率分布来判断一个数据点是正常还是异常。
状态监控实例:齿轮轴承故障
在这个部分,我会介绍上述两个不同方法在状态监控实例中的应用。由于实际工作中大部分客户的数据是无法公开的,我们选择使用 NASA 的数据来展示两种方法,读者也可以通过链接自行下载。
NASA 数据下载:
http://data-acoustics.com/measurements/bearing-faults/bearing-4/
在该实例中,目的是检测发动机上的齿轮轴承退化,并发送警告,以帮助工作人员及时采取措施以免齿轮故障。
实验细节和数据准备
在恒定负载和运行条件下,三个数据集各包含四个轴承运行出现异常的数据。数据集提供了轴承生命周期内的振动测量信号,直到出现故障。前连天的运行数据被用作训练数据,以表示正常且“健康”的设备。剩余部分的数据包含轴承运转直到故障的过程,这部分数据用作测试数据,以评估不同方法是否能在运转故障前检测到其轴承异常。
方法一:PCA + 马氏距离
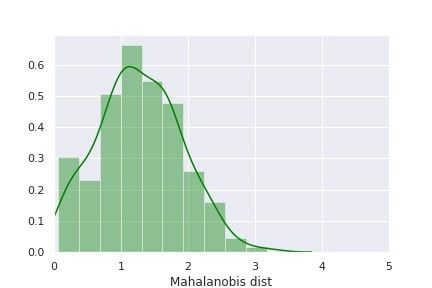
正如本文“技术部分”中所介绍的,第一种方法先进行主成分分析,然后计算其马氏距离,来辨别一个数据点是正常的还是异常的(即设备退化的信号)。代表“健康”设备的训练数据的马氏距离的分布如下图所示:
图3:“健康”设备的马氏距离分布
利用“健康”设备的马氏距离分布,我们可以设定判断是否为异常点的阈值。从上面的分布图来看,我们可以定义马氏距离大于 3 的部分为异常。这种检测设备老化的估计方法,需要计算测试集中全部数据点的马氏距离,并将其与所设置的阈值进行比较,来标记其是否异常。
基于测试数据的模型评估
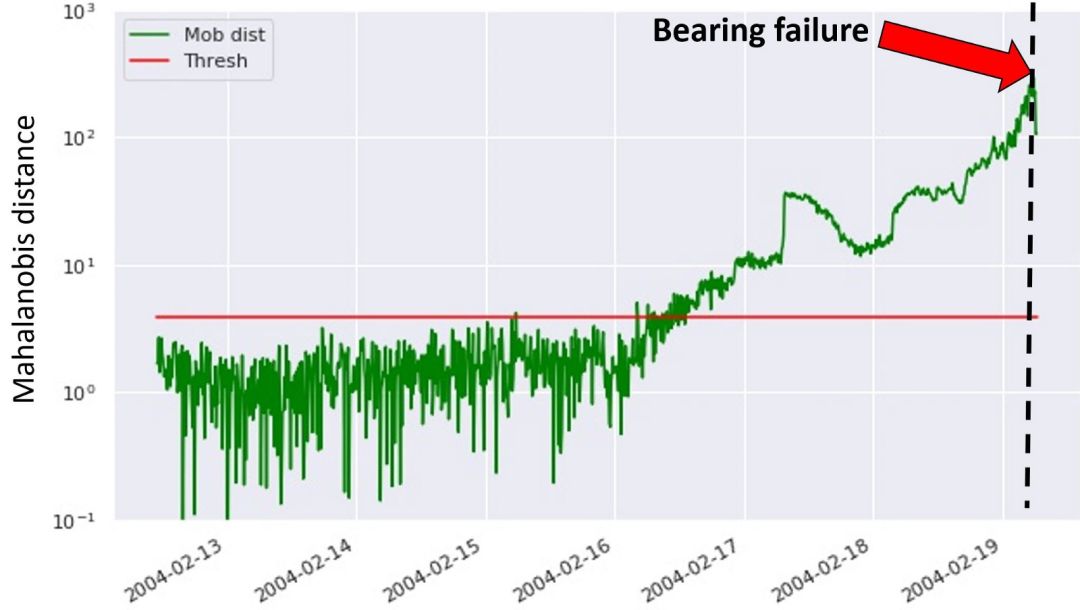
利用上述方法,我们计算测试数据,即运转直到轴承故障这一时间段内数据的马氏距离,如下图所示:
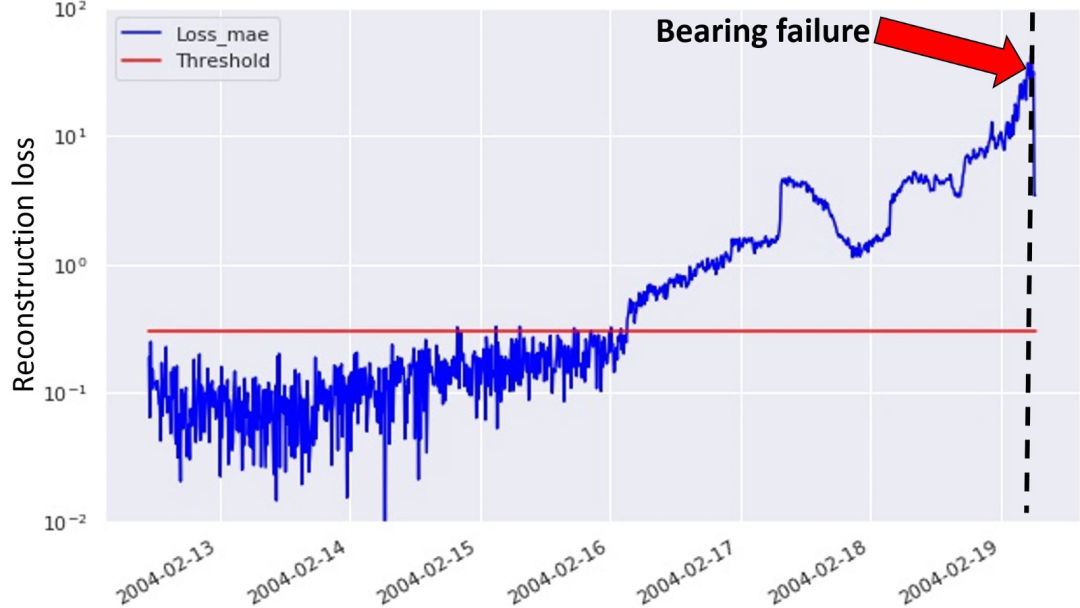
图 4:利用方法一检测轴承故障
在上图中,绿色点对应计算得到的马氏距离,而红线表示所设置的异常阈值。轴承故障发生在数据集的最末端,即黑色虚线标记处。这说明第一种方法可以检测到 3 天后即将发生的设备故障。
现在我们用第二种建模方法做类似的实验,以评估哪种方法更好。
方法二:人工神经网络
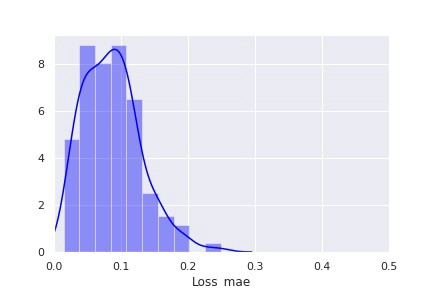
如本文“技术部分”中所写的,第二种方法包括使用自动编码器神经网络来寻找异常点。和第一种方法类似,我们在此也是用模型输出的分布,用表示“健康”设备的数据作为训练数据,来进行异常检测。训练数据集的重建损失分布如下图所示:
图 5::“健康”设备的重建损失分布
利用“健康”设备的重建损失分布,我们可以设置判断数据是否异常的阈值。由上图中的分布,我们可以设置损失大于 0.25 的部分为异常。这种检测设备老化的评估方法包括计算测试集中全部数据点的重建损失,将该损失与所设置阈值作比较,来判别其是否异常。
基于测试数据的模型评估
利用上述方法,我们计算测试数据,即运转直到轴承故障这一时间段内数据的重建损失,如下图所示:
图 6:利用方法二检测轴承故障
在上图中,蓝色点对应重建损失,而红线表示所设置的异常阈值。轴承异常发生在数据集的末端,即黑色虚线标记处。这表示该建模方法也能够检测到未来 3 天即将发生的设备异常。
总结
综上所述,两种不同的方法都能用作异常检测,在机器实际发生故障前几天就检测到即将发生的事故。在现实生活场景中,这项技术可以帮助我们早在故障前就采取预防措施,不仅可以节约开销,也在设备故障的 HSE 方面具有潜在的重要性。
展望
使用传感器收集数据的成本越来越低,设备间的连通度也日益提升,从数据中提取有价值的信息变得越来越重要。从大量数据中挖掘模式是机器学习和统计的重要领域,利用这些数据背后隐藏的信息来改善不同领域有极大的可能性。异常检测和状态监控只是诸多可能性中的一种。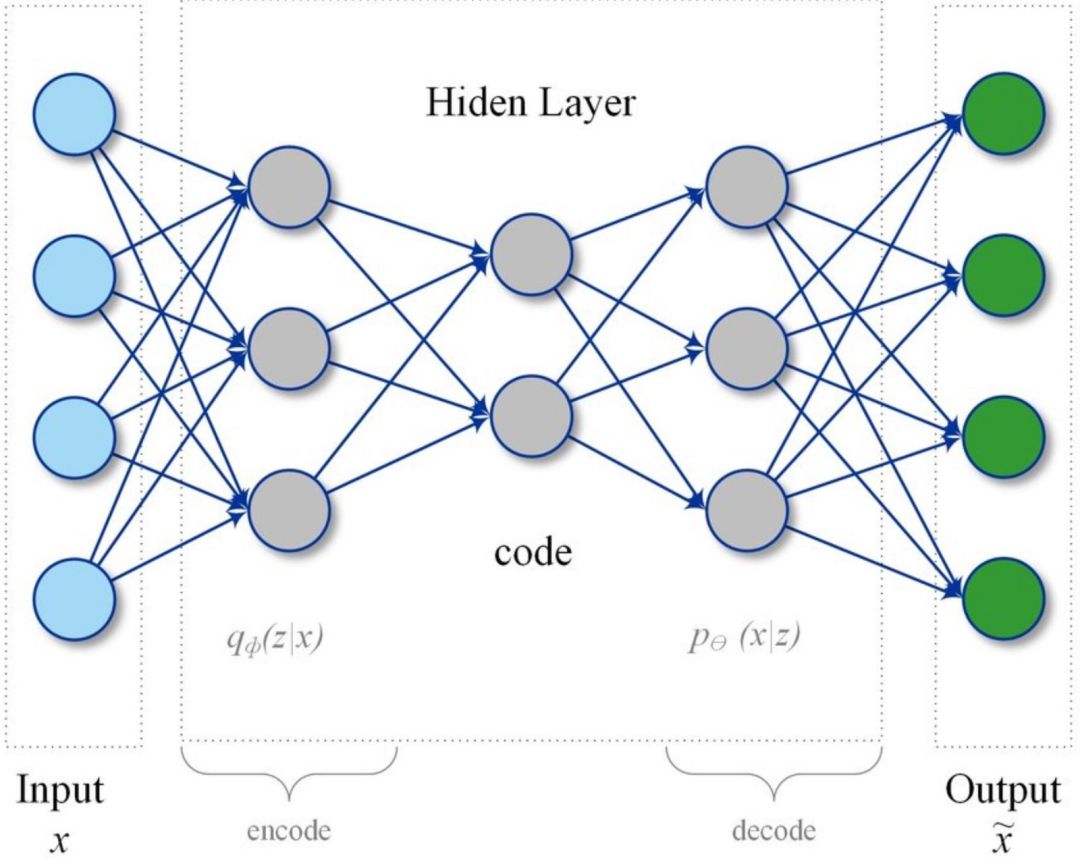
-
数据
+关注
关注
8文章
7002浏览量
88937 -
异常检测
+关注
关注
1文章
42浏览量
9740
原文标题:一文掌握异常检测的实用方法 | 技术实践
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于transformer和自监督学习的路面异常检测方法分享

基于深度学习的异常检测的研究方法
基于深度学习的异常检测的研究方法
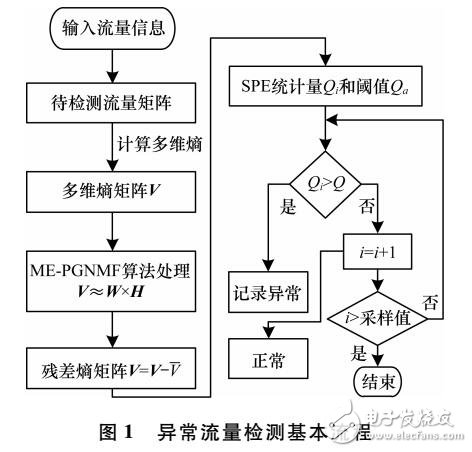
基于ME-PGNMF的异常流量检测方法
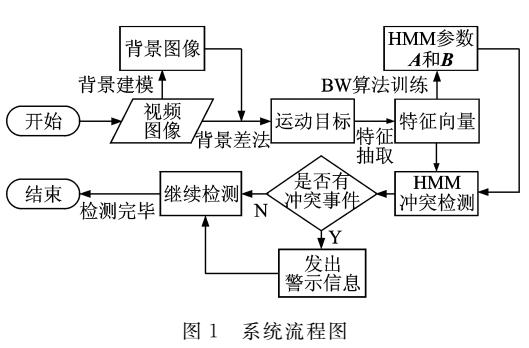
智能监控视频异常事件检测





 工商网监
工商网监
评论