 BigBiGAN问世,“GAN父”都说酷的无监督表示学习模型有多优秀?
BigBiGAN问世,“GAN父”都说酷的无监督表示学习模型有多优秀?
众所周知,对抗训练生成模型(GAN)在图像生成领域获得了不凡的效果。尽管基于GAN的无监督学习方法取得了初步成果,但很快被自监督学习方法所取代。
DeepMind近日发布了一篇论文《Large Scale Adversarial Representation Learning》(大规模对抗性表示学习),提出了无监督表示学习新模型BigBiGAN。

致力于将图像生成质量的提升转化为表征学习性能的提高,基于BigGAN模型的基础上提出了BigBiGAN,通过添加编码器和修改鉴别器将其扩展到图像学习。作者评估了BigBiGAN模型的表征学习能力和图像生成功能,证明在ImageNet上的无监督表征学习以及无条件图像生成,该模型达到了目前的最佳性能。
论文发布后,诸多AI大牛转发并给出了评价。
“GAN之父”Ian Goodfellow表示这很酷,在他读博士期间,就把样本生成双产物的表示学习感兴趣,而不是样本生成本身。

特斯拉AI负责人Andrej Karpathy则表示,自我监督的学习是一个非常丰富的领域(但需要比ImageNet提供更高的密度和结构),这将避免大规模数据集的当前必要性(或在RL中推出)。

1、介绍
近年来,图像生成模型快速发展。虽然这些模型以前仅限于具有单模或多模的结构域,生成的图像结构简单,分辨率低,但随着模型和硬件的发展,已有生成复杂、多模态,高分辨率图像的能力。
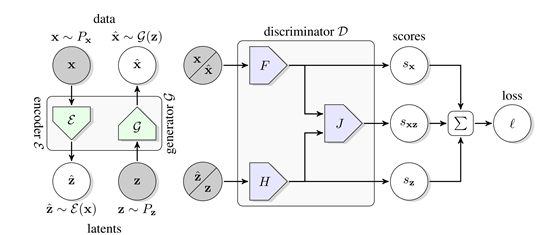
图1 BigBiGAN框架框图
联合鉴别器
 ,输入是数据潜在对,
,输入是数据潜在对,
,从数据分布Px和编码器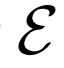 输出中采样,或
输出中采样,或
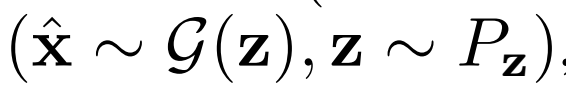
从生成器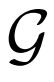 输出和潜在分布Pz中采样。损失
输出和潜在分布Pz中采样。损失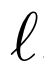 包括一元数据项
包括一元数据项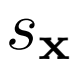 和一元潜在项
和一元潜在项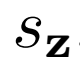 ,以及将数据和潜在分布联系起来的联合项
,以及将数据和潜在分布联系起来的联合项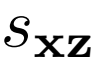 。
。
通过BiGAN或ALI框架学习的编码器,是ImageNet上用于下游任务的可视化表示学习的有效手段。然而,该方法使用了DCGAN样式生成器,无法在该数据集上生成高质量图像,因此编码器可以建模的语义非常有限。作者基于该方法,使用BigGAN作为生成器,能够捕获ImageNet图像中存在的多模态和出现的大部分结构。总体而言,本文的贡献如下:
(1)在ImageNet上,BigBiGAN(带BigGAN的BiGAN生成器)匹配无监督表征学习的最新技术水平
(2)为BigBiGAN提出了一个稳定版本的联合鉴别器
(3)对模型设计选择进行了全面的实证分析和消融实验
(4)表征学习目标还有助于无条件图像生成,并展示无条件ImageNet生成的最新结果
2、BigBiGAN
BiGAN、ALI方法作为GAN框架的扩展,能够学习可以用作推理模型或特征表示的编码器。给定数据项x的分布Px(例如,图像)和潜在项z的分布Pz(通常是像各向同性高斯N(0;I)的简单连续分布),生成器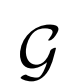 vwin
条件概率分布
vwin
条件概率分布
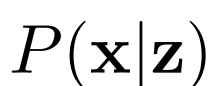
,给定潜在项z后数据项x的概率值,如标准GAN生成器。编码器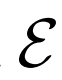 对逆条件分布
对逆条件分布
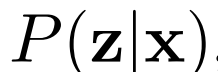
进行建模,预测给定数据项x的情况下,潜在项z的概率值。
除了添加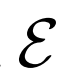 之外,BiGAN框架中对GAN的另一种修改是联合鉴别器
之外,BiGAN框架中对GAN的另一种修改是联合鉴别器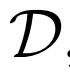 - 潜在项对(x,z)(而不仅仅是标准GAN中的数据项x),并且学习区分数据分布和编码器对,生成器和潜在分布。具体地说,它的输入对是
- 潜在项对(x,z)(而不仅仅是标准GAN中的数据项x),并且学习区分数据分布和编码器对,生成器和潜在分布。具体地说,它的输入对是
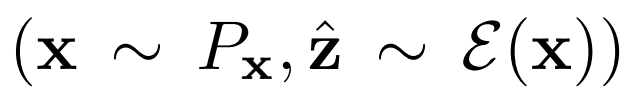
和
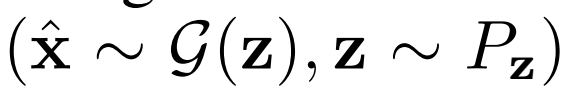
,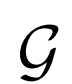 和
和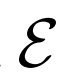 的目标是“欺骗”鉴别器,使得被采样的两个联合概率分布
的目标是“欺骗”鉴别器,使得被采样的两个联合概率分布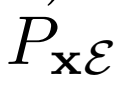 和
和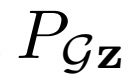 难以区分。GAN框架的目标,定义如下:
难以区分。GAN框架的目标,定义如下:
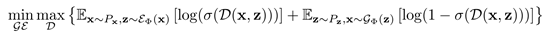
在这个目标下,在最优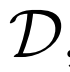
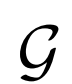 和
和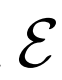 最小化联合分布
最小化联合分布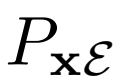 和
和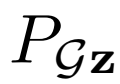 之间的Jensen-Shannon散度,因此在全局最优时,两个联合分布
之间的Jensen-Shannon散度,因此在全局最优时,两个联合分布
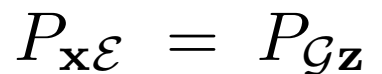
匹配。此外,在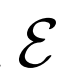 和
和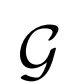 是确定性函数的情况下(即,学习条件分布
是确定性函数的情况下(即,学习条件分布

和
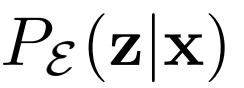
是Dirac δ函数),这两个函数是全局最优的逆:例如
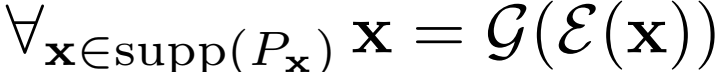
,最佳联合鉴别器有效地对x和z施加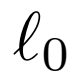 重建成本。
重建成本。
具体地,鉴别器损失值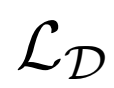
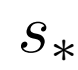
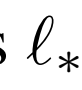
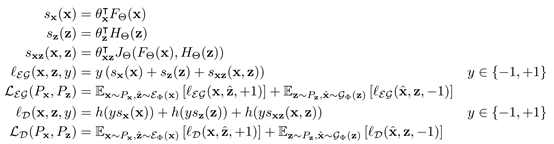
其中
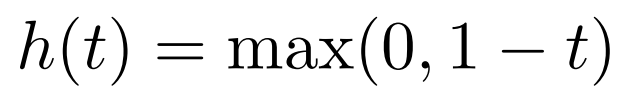
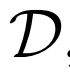
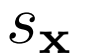
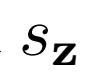
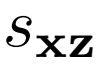
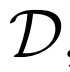
优化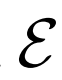 和
和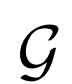 参数
参数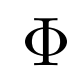
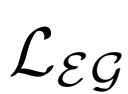
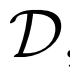
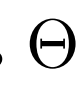
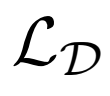
3、评估
作者在未标记的ImageNet上训练BigBiGAN,固定其表征学习结果,然后在其输出上训练线性分类器,使用所有训练集标签进行全面监督学习。 作者还测量图像生成性能,其中
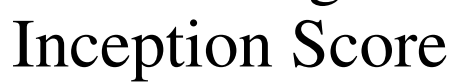
IS)和
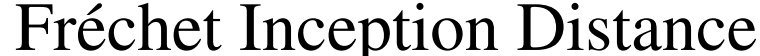
FID)作为标准指标。
3.1 消融
作者先评估了多种模型,见表1。作者使用不同的种子对每个变体进行三次运行并记录每个度量的平均值和标准差。
潜在分布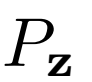 随机值
随机值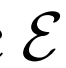 :
:
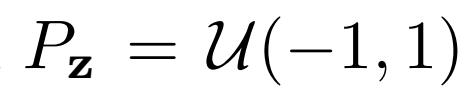
,其中在给定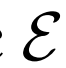 和线性输出
和线性输出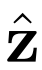 的情况下,预测
的情况下,预测
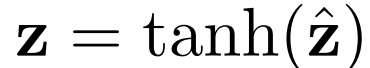
一元损失:
评估删除损失函数的一元项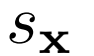
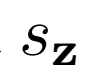 影响。只有z一元项和没有一元项的IS和FID性能要比只有x一元项和两者都有的性能差,结果表明x一元项对生成性能有很大的正面影响。
影响。只有z一元项和没有一元项的IS和FID性能要比只有x一元项和两者都有的性能差,结果表明x一元项对生成性能有很大的正面影响。
生成器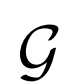 容量:
容量:
为了证明生成器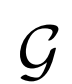 在表征学习中的重要性,作者改变生成器的容量观察对结果的影响。实验结果表明,好的图像生成器模型能提高表征学习能力。
在表征学习中的重要性,作者改变生成器的容量观察对结果的影响。实验结果表明,好的图像生成器模型能提高表征学习能力。
带有不同分辨率的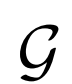 的高分辨率
的高分辨率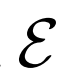 :
:
使用更高的分辨率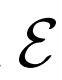 ,尽管
,尽管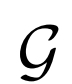 的分辨率相同,但是生成结果显着改善(尤其是通过FID)。
的分辨率相同,但是生成结果显着改善(尤其是通过FID)。
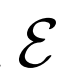 结构:
结构:
使用不同结构的评估性能,结果表明网络宽度增加,性能会得到提升。
解耦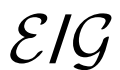 优化:
优化:
将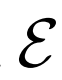 优化器与
优化器与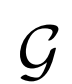 的优化器分离,并发现简单地使用10倍的E学习速率可以显着加速训练并改善最终表征学习结果。
的优化器分离,并发现简单地使用10倍的E学习速率可以显着加速训练并改善最终表征学习结果。
3.2与已有方法比较
表征学习
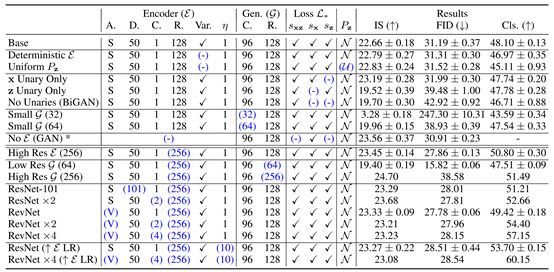
表1:BigBiGAN变体的结果
在生成图像的IS和FID中,以及ImageNet top-1分类准确率,根据从训练集中随机抽样的10K图像的分割计算,称为Train分裂。每行中基本设置的更改用蓝色突出显示。具有误差范围的结果(写为“μ±σ”)是具有不同随机种子的三次运行的平均值和标准偏差。
表2:使用监督逻辑回归分类器对官方ImageNet验证集上的BigBiGAN模型与最近竞争方法的比较
基于10K训练集图像的trainval子集的最高精度,选择BigBiGAN结果并提前停止。ResNet-50结果对应于表1中的行ResNet(“ELR”),RevNet-50×4对应于RevNet×4(“ELR”)

表3:无监督(无条件)生成的BigBiGAN与已有的无监督BigGAN的比较结果
作者将“伪标签”方法指定为SL(单标签)或聚类。为了进行比较,训练BigBiGAN的步数(500K)与基于BigGAN的方法相同,但也可以在最后一行中对1M步骤进行额外训练,并观察其变化。上述所有结果均包括中值m以及三次运行的平均μ和标准偏差σ,表示为“m(μ±σ)”。BigBiGAN的结果由最佳FID与Train的停止决定的。
无监督图像生成
图2:从无监督的BigBiGAN模型中选择的重建
上图2中第一行表示真实数据x~Px;第二行表示由
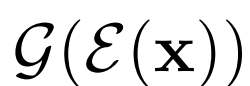
3.3 重建
BiGAN E和G通过计算编码器预测的潜在表示E(x),然后将预测的潜在表示传回生成器,得到重建的G(E(x)),从而重构数据实例x。我们在图2中展示了BigBiGAN重构。这些重构远非有像素级的完美度,部分原因可能是目标并没有明确强制执行重构成本,甚至在训练时也没有计算重构。然而,它们可能为编码器学习建模的特性提供一些直观的认识。例如,当输入图像包含一条狗、一个人或一种食物时,重建通常是相同“类别”的不同实例,具有相似的姿势、位置和纹理。这些重构倾向于保留输入的高级语义,而不是低级细节,这表明BigBiGAN训练鼓励编码器对前者建模,而不是后者。
4、相关研究
基于自我监督图像中的无监督表示学习的许多方法被证明是非常成功的。自我监督通常涉及从以某种方式设计成类似于监督学习的任务中学习,但是其中“标签”可以自动地从数据本身创建而无需人工操作。早期的例子是相对位置预测,其中模型在输入的图像块对上进行训练并预测它们的相对位置。
对比预测编码(CPC)是最近的相关方法,其中,给定图像补丁,模型预测哪些补丁出现在其他图像位置中。其他方法包括着色、运动分割、旋转预测和样本匹配。
对这些方法进行了严格的实证比较。相对于大多数自我监督的方法,BigBiGAN和基于生成模型的其他方法的关键优势是它们的输入可能是全分辨率图像或其他信号,不需要裁剪或修改所需的数据。这意味着结果表示通常可以直接应用于下游任务中的完整数据,而不会发生域移位(domain shift)。
还提出了许多相关的自动编码器和GAN变体。关联压缩网络(ACN)学会通过调节其他先前在代码空间中相似的传输数据的数据来压缩数据集级别,从而产生可以“模糊”语义相似样本的模型,类似于BigBiGAN重建。VQ-VAE 将离散(矢量量化)编码器与自回归解码器配对,以产生具有高压缩因子的忠实重建,并在强化学习设置中展示表示学习结果。在对抗性空间中,对抗性自动编码器提出了一种自动编码器式编码器 - 解码器对,用像素级重建成本训练,用鉴别器代替VAE中使用的先验的KL-发散正则化。
在另一个提出的VAE-GAN混合中,在大多数VAE中使用的像素空间重建误差被替换为距GAN鉴别器的中间层的特征空间距离。AGE和α-GAN等其他混合方法增加了编码器来稳定GAN训练。这些方法与BiGAN框架间的一个区别是,BiGAN不会以明确的重建成本训练编码器,虽然可以证明BiGAN隐含地使重建成本最小化,但定性重建结果表明这种重建成本具有不同的风格,强调了像素级细节上的高级语义。
5.探讨
我们已经证明,BigBiGAN是一种纯粹基于生成模型的无监督学习方法,它在ImageNet上实现了图像表示学习的最好的结果。我们的消融实验进一步证实强大的生成模型可以有利于表征学习,反过来,学习推理模型可以改善大规模的生成模型。在未来,我们希望表示学习可以继续受益于生成模型和推理模型的进一步发展,同时扩展到更大的图像数据库。
-
GaN
+关注
关注
19文章
1933浏览量
73286 -
无监督学习
+关注
关注
1文章
16浏览量
2754
原文标题:BigBiGAN问世,“GAN父”都说酷的无监督表示学习模型有多优秀?
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
时空引导下的时间序列自监督学习框架

java子类可以继承父类的什么
【《大语言模型应用指南》阅读体验】+ 基础知识学习
神经网络如何用无监督算法训练
深度学习中的无监督学习方法综述
基于FPGA的类脑计算平台 —PYNQ 集群的无监督图像识别类脑计算系统
大语言模型:原理与工程时间+小白初识大语言模型
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】揭开大语言模型的面纱
跟优秀的人,学习记笔记!文末有看海的点评






 工商网监
工商网监
评论