 德赢Vwin官网
App
德赢Vwin官网
App


Redis 是一个开源、高性能的 Key-Value 数据库,被广泛应用在服务器各种场景中。Redis 是一种内存数据库,将数据保存在内存中,读写效率要比传统的将数据保存在磁盘上的数据库要快很多。所以,监控 Redis 的内存消耗并了解 Redis 内存模型对高效并长期稳定使用 Redis 至关重要。
在介绍之前先说明下,一般生产环境下,对开发同事不会开放直连 redis 集群的权限,一般是提供 daas 平台,通过可视化命令窗口,输入 redis 命令,一般只有 read 权限;对于 write 操作,需要提 redis 数据变更单,而对于 redis 内存、大 key、慢命令,一般都会将信息集成及中显示在监控看板,而不需要开发同事自己去输入命令;但是基本的相关知识还是要具备的。
reids 内存分析
redis 内存使用情况:info memory

示例:
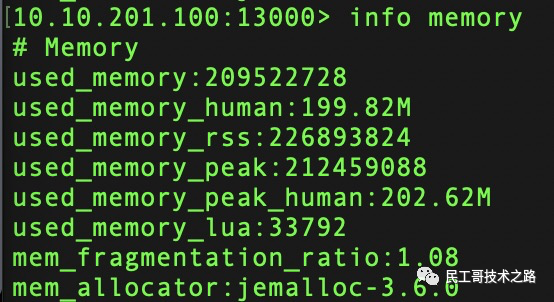
可以看到,当前节点内存碎片率为 226893824/209522728 ≈ 1.08,使用的内存分配器是 jemalloc。
used_memory_rss 通常情况下是大于 used_memory 的,因为内存碎片的存在。
但是当操作系统把 redis 内存 swap 到硬盘时,memory_fragmentation_ratio 会小于 1。redis 使用硬盘作为内存,因为硬盘的速度,redis 性能会受到极大的影响。
redis 内存使用
redis 的内存使用分布:自身内存,键值对象占用、缓冲区内存占用及内存碎片占用。
redis 空进程自身消耗非常的少,可以忽略不计,优化内存可以不考虑此处的因素。
对象内存
对象内存,也即真实存储的数据所占用的内存。
redis k-v 结构存储,对象占用可以简单的理解为 k-size + v-size。
redis 的键统一都为字符串类型,值包含多种类型:string、list、hash、set、zset五种基本类型及基于 string 的 Bitmaps 和 HyperLogLog 类型等。
在实际的应用中,一定要做好 kv 的构建形式及内存使用预期,。
缓冲内存
缓冲内存包括三部分:客户端缓存、复制积压缓存及 AOF 缓冲区。
客户端缓存
接入redis服务器的TCP连接输入输出缓冲内存占用,TCP 输入缓冲占用是不受控制的,最大允许空间为 1G。输出缓冲占用可以通过 client-output-buffer-limit 参数配置。
redis 客户端主要分为从客户端、订阅客户端和普通客户端。
从客户端连接占用
也就是我们所说的 slave,主节点会为每一个从节点建立一条连接用于命令复制,缓冲配置为:client-output-buffer-limit slave 256mb 64mb 60。
主从之间的间络延迟及挂载的从节点数量是影响内存占用的主要因素。因此在涉及需要异地部署主从时要特别注意,另外,也要避免主节点上挂载过多的从节点(<=2);
订阅客户端内存占用
发布订阅功能连接客户端使用单独的缓冲区,默认配置:client-output-buffer-limit pubsub 32mb 8mb 60。
当消费慢于生产时会造成缓冲区积压,因此需要特别注意消费者角色配比及生产、消费速度的监控。
普通客户端内存占用
除了上述之外的其它客户端,如我们通常的应用连接,默认配置:client-output-buffer-limit normal 1000。
可以看到,普通客户端没有配置缓冲区限制,通常一般的客户端内存消耗也可以忽略不计。
但是当 redis 服务器响应较慢时,容易造成大量的慢连接,主要表现为连接数的突增,如果不能及时处理,此时会严重影响 redis 服务节点的服务及恢复。
关于此,在实际应用中需要注意几点:
maxclients 最大连接数配置必不可少。
合理预估单次操作数据量(写或读)及网络时延 ttl。
禁止线上大吞吐量命令操作,如 keys 等。
高并发应用情景下,redis内存使用需要有实时的监控预警机制。
复制积压缓冲区
v2.8 之后提供的一个可重用的固定大小缓冲区,用以实现向从节点的部分复制功能,避免全量复制。配置单数:repl-backlog-size,默认 1M。单个主节点配置一个复制积压缓冲区。
AOF缓冲区
AOF重写期间增量的写入命令保存,此部分缓存占用大小取决于 AOF 重写时间及增量。
内存碎片内存占用
固定范围内存块儿分配。redis默认使用jemalloc内存分配器,其它包括glibc、tcmalloc。
内存分配器会首先将可管理的内存分配为规定不同大小的内存块以备不同的数据存储需求,但是,我们知道实际应用中需要存储的数据大小不一,规范不一,内存分配器只能选择最接近数据需求大小的内存块儿进行分配,这样就伴随着“占不满”空间的碎片浪费。
jemalloc针对内存碎片有相应的优化策略,正常碎片率为mem_fragmentation_ratio在1.03左右。
第二部分我们说过,对string值得频繁append及range操作会会导致内存碎片问题,另外,第七部分,SDS惰性内存回收也会导致内存碎片,同时过期键内存回收也伴随着所释放空间的无法充分利用,导致内存碎片率上升的问题。
碎片处理:
应用层面:尽量避免差异化的键值使用,做好数据对齐。
redis服务层面:可以通过重启服务,进行碎片整理。
maxmemory 及 maxmemory-policy
redis 基于以上配置控制 redis 最大可用内存及内存回收。需要注意的是内存回收执行影响redis的性能,避免频繁的内存回收开销。
redis 子进程内存消耗
子进程即 redis 执行持久化(RDB/AOF)时 fork 的子任务进程。
关于 linux 系统的写时复制机制
父子进程会共享相同的物理内存页,父进程处理写请求时会对需要修改的页复制一份副本进行修改,子进程读取的内存则为fork时的父进程内存快照,因此,子进程的内存消耗由期间的写操作增量决定。
关于 linux 的透明大页机制THP(Transparent Huge Page)
THP 机制会降低 fork 子进程的速度:写时复制内存页由 4KB 增大至 2M。高并发情境下,写时复制内存占用消耗影响会很大,因此需要选择性关闭。
关于linux配置
一般需要配置 linux 系统 vm.overcommit_memory = 1,以允许系统可以分配所有的物理内存。防止fork任务因内存而失败。
redis 内存管理
redis 的内存管理主要分为两方面:内存上限控制及内存回收管理。
内存上限:maxmemory
目的:缓存应用内存回收机制触发 + 防止物理内存用尽(redis 默认无限使用服务器内存) + 服务节点内存隔离(单服务器上部署多个 redis 服务节点)
在进行内存分配及限制时要充分考虑内存碎片占用影响。动态调整,扩展redis服务节点可用内存:config set maxmemory {}
内存回收
回收时机:键过期、内存占用达到上限
过期键删除
redis 键过期时间保存在内部的过期字典中,redis 采用惰性删除机制+定时任务删除机制。
惰性删除
即读时删除,读取带有超时属性的键时,如果键已过期,则删除然后返回空值。这种方式存在问题是,触发时机,加入过期键长时间未被读取,那么它将会一直存在内存中,造成内存泄漏。
定时任务删除
redis 内部维护了一个定时任务(默认每秒10次,可配置),通过自适应法进行删除。
删除逻辑如下:
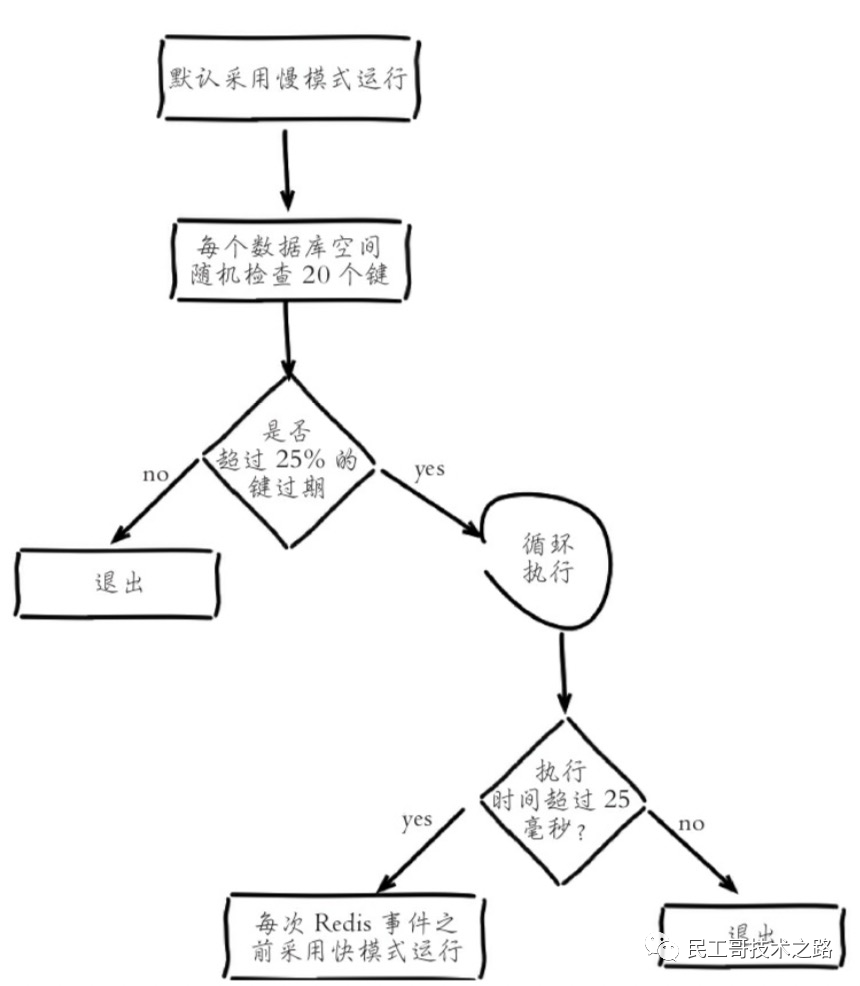
需要说明的一点是,快慢模式执行的删除逻辑相同,这是超时时间不同。
内存溢出控制
当内存达到 maxmemory,会触发内存回收策略,具体策略依据 maxmemory-policy 来执行。
noevication:默认不回收,达到内存上限,则不再接受写操作,并返回错误。
volatile-lru:根据LRU算法删除设置了过期时间的键,如果没有则不执行回收。
allkeys-lru:根据LRU算法删除键,针对所有键。
allkeys-random:随机删除键。
volatitle-random:随机删除设置了过期时间的键。
volatilte-ttl:根据键ttl,删除最近过期的键,同样如果没有设置过期的键,则不执行删除。
动态配置:config set maxmemory-policy {}
在设置了maxmemory情况下,每次的redis操作都会检查执行内存回收,因此对于线上环境,要确保所这只的 maxmemory > used_memory。
另外,可以通过动态配置 maxmemory 来主动触发内存回收。
内存回收策略
内存回收触发有两种情况,也就是内存使用达到maxmemory上限时候触发的溢出回收,还有一种是我们设置了过期的对象到期的时候触发的到期释放的内存回收。
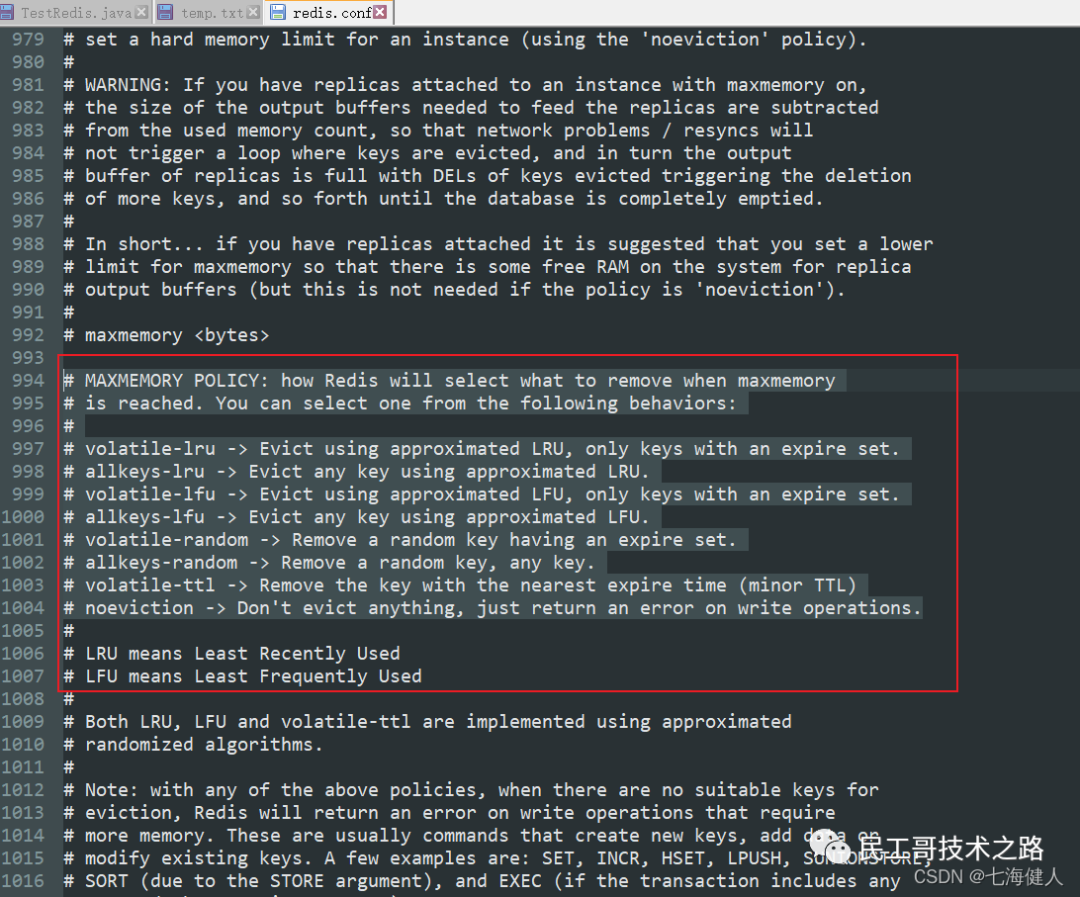
Redis内存使用达到maxmemory上限时候触发的溢出回收;Redis 提供了几种策略 (maxmemory-policy) 来让用户自己决定该如何腾出新的空间以继续提供读写服务:
(1)volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
(2)volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
(3)volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
(4)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
(5)allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
(6)no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0版本后增加以下两种:
(7)volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
(8)allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
redis默认的策略就是noeviction策略,如果想要配置的话,需要在配置文件中写这个配置:
maxmemory-policy volatile-lru
Redis 的 LRU 算法
LRU是Least Recently Used 近期最少使用算法,很多缓存策略都使用了这种策略进行空间的释放,在学习操作系统的内存回收的时候也用到了这种机制进行内存的回收,类似的还有LFU(Least Frequently Used)最不经常使用算法,这种算法。
我们在上面的描述中也可以了解到,redis使用的是一种类似LRU的算法进行内存溢出回收的,其算法的代码:
/* volatile-lru and allkeys-lru policy */
else if (server.maxmemory_policy == REDIS_MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == REDIS_MAXMEMORY_VOLATILE_LRU)
{
struct evictionPoolEntry *pool = db->eviction_pool;
while(bestkey == NULL) {
evictionPoolPopulate(dict, db->dict, db->eviction_pool);
/* Go backward from best to worst element to evict. */
for (k = REDIS_EVICTION_POOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
de = dictFind(dict,pool[k].key);
/* Remove the entry from the pool. */
sdsfree(pool[k].key);
/* Shift all elements on its right to left. */
memmove(pool+k,pool+k+1,
sizeof(pool[0])*(REDIS_EVICTION_POOL_SIZE-k-1));
/* Clear the element on the right which is empty
* since we shifted one position to the left. */
pool[REDIS_EVICTION_POOL_SIZE-1].key = NULL;
pool[REDIS_EVICTION_POOL_SIZE-1].idle = 0;
/* If the key exists, is our pick. Otherwise it is
* a ghost and we need to try the next element. */
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... */
continue;
}
}
}
}
Redis会基于server.maxmemory_samples配置选取固定数目的key,然后比较它们的lru访问时间,然后淘汰最近最久没有访问的key,maxmemory_samples的值越大,Redis的近似LRU算法就越接近于严格LRU算法,但是相应消耗也变高。所以,频繁的进行这种内存回收是会降低redis性能的,主要是查找回收节点和删除需要回收节点的开销。
所以一般我们在配置redis的时候,尽量不要让它进行这种内存溢出的回收操作,redis是可以配置maxmemory,used_memory指的是redis真实占用的内存,但是由于操作系统还有其他软件以及内存碎片还有swap区的存在,所以我们实际的内存应该比redis里面设置的maxmemory要大,具体大多少视系统环境和软件环境来定。maxmemory也要比used_memory大,一般由于碎片的存在需要做1~2个G的富裕。
编辑:黄飞














 工商网监
工商网监
评论