 德赢Vwin官网
App
德赢Vwin官网
App


TLDR(AI Claude 的总结)
本文来自一位 Python 开发者对一个庞大的 Python 项目的代码结构的总结。
该项目包含近 3 万个 Python 文件,由全球 400 多名开发者共同维护。为了应对代码日益增长的复杂性,项目采用了分层架构的设计。即将代码库划分为多个层级,并限制不同层级之间的依赖关系,依赖只能从上层流向下层。
文章详细介绍了该项目的分层结构,以及如何利用 Import Linter 工具来强制执行分层规则。通过追踪被忽略的非法 import 语句数量,可以衡量分层结构实现的进度。
分层架构确实能够有效降低大型项目的复杂度,方便独立开发。但也存在一些缺点,比如容易在高层产生过多代码,完全实施分层需要花费时间等。总体来说,尽早引入分层架构,能够减少后期的重构工作量,是管理大型 Python 项目的一个有效方式。
本文通过一个真实的大规模 Python 项目案例,生动地介绍了分层架构的实施过程、优势和不足,对于管理大型项目很有借鉴作用。
前言
大家好,我是来自 Kraken Technologies 的 Python 开发者 David。我在的 Kraken 工作是维护一个 Python 应用,根据最新统计它拥有 27637 个模块的。是的,你没看错,这个项目拥有近 28K 独立的 Python 文件(不包括测试代码)。
我与全球其他 400 名开发人员一同维护这个庞然大物,不断地为它合并新的代码。任何人只需要在 Github 上获得一位同事的批准,就能修改代码文件,并启动软件的部署,该软件在 17 家不同的能源和公用事业公司运行着,拥有数百万的客户群体。
看到上面的描述,你大概率会下意识地认为这个项目的代码肯定无比的混乱。坦白讲,我也会这么想。但事实是,至少在我工作的领域,大量的开发人员可以在一个大型的 Python 项目上高效地工作。
实现这个目标的要素有很多,其中许多要素来自文化与规则而非技术,在本篇博文中,我想着重讲一下我们是如何通过优化代码组织结构来实现这一目标的。
分层架构
如果你已经负责维护某个应用的代码仓库一段时间,肯定会感受到随着时间的推移代码复杂度越来越高。在不断开发与维护的过程中,应用中各部分的逻辑代码混合在一起,独立地分析应用中的某个模块变得越来越困难。
这也是我们早期维护代码仓库时遇到的问题,经过研究后我们决定采用分层架构(即将代码库划分成多个组件(也就是层级,后面不再注释),并限制各组件间的引用关系)来应对这一问题。
分层(Layering)是一种较为常见的软件架构模式,在这种模式下不同的组件(即层级,后面不在重复注释)会被以(概念上)栈的形式组织起来。在这个栈中,下层组件不能依赖(引入)其上层组件。
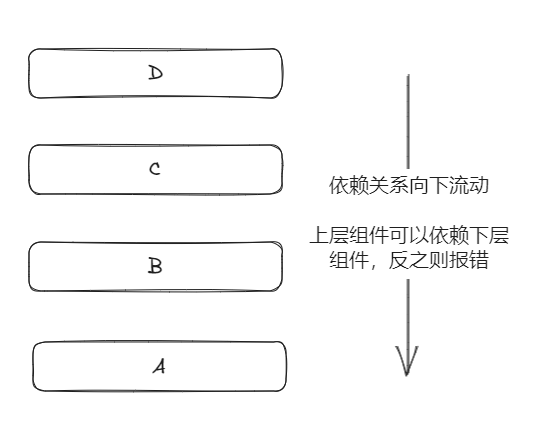 依赖向下关系流动的分层架构
依赖向下关系流动的分层架构
例如,在上图中,C 可以依赖 B 和 A,但不能依赖 D。
分层架构的应用很宽泛,你可以自由地定义组件。例如:你可以将多个可独立部署的服务视作多个组件,也可以直接将项目中不同部分的源码文件视作不同的组件。
依赖关系的定义也很宽泛。通常,只要两个组件间存在直接交叉(即使只发生在概念层级上),我们就认为它们之间存在依赖关系。间接交叉(例如通过配置传递)通常不被视为依赖关系。
如何在 Python 项目中应用分层架构
分层架构在 Python 项目中的最佳实践是:将 Python 模块作为分层依据,将导入语句视为依赖依据。
以如下项目仓库目录举例:
myproject __init__.py payments/ __init__.py api.py vendor.py products.py shopping_cart.py
目录中模块之间的嵌套关系是分层的最佳依据。假设,我们决定按照一下顺序进行分层:
# 依赖关系向下流动(即上层可以依赖下层) shopping_cart payments products
为了满足上述架构的要求,我们需要禁止 payments 中的模块从 shopping_cart 模块中引入内容,但可以从 products 模块中引入内容(参考图 1)。
分层也可以嵌套,因此我们可以在 payments 模块中继续分层,例如:
api vendor
设置多少分层以及以什么顺序进行排列没有唯一正确的答案,需要我们不断的在实践中总结。但是合理的运用分层架构确实能够有效地降低项目结构的复杂度,使其能够更易于理解和修改。
我们是如何在 Kraken 的项目中实践分层架构的
在我编写这边文章的时候,已经有 17 家不同的能源和公共事业相关的企业购买了 Kraken 的许可证。我们在内部称呼这些企业为 client,并为每一家企业都运行了一个独立的实例。也正因如此,Kraken 的不同实例间形成了一种「同根不同枝」的特点。
通俗地讲就是不同实例间的很多行为其实是共享的,但是每个 client 也都有属于自己的定制代码,以满足他们特定的需求。从地域层面来讲也如此,在英国运行的所有 client 之间存在一定的共性(他们属于同类的能源行业),而日本的 Octopus Energy 则不共享这些的共性。
随着 Kraken 平台的成长,我们也在不断地优化着我们的分成架构,来帮助我们更好地满足不同客户的需求。目前的分层的顶层结构大致如下:
# 依赖关系向下流动(即上层可以依赖下层) kraken/ __init__.py client/ __init__.py oede/ oegb/ oejp/ ... territories/ __init__.py deu/ gbr/ jpn/ ... core/
client 组件在结构的顶部。每一个 client 在该层都有一个专属的子包(例如,oede 对应 Octopus Energy Germany)。在此之下的是 territories 组件,用于满足不用国家所需的特定行为,同样为不同地区设置了不同的子包。最底层是 core 组件,包含了所用 client 都会用到的通用代码。
我们还制定了一个特别的规则:client 组件下的子包必须是独立的(即不能被其他 client 引用),territories 组件下的子包也是如此。
将 Kraken 以这种分层结构构建之后,我们可以在有限的区域内(例如一个组件的子包)便捷地进行代码的更新和维护。由于 client 组件位于结构的顶部,因此不会有任何其他组件会直接依赖于它,这样我们就能更方便地更改特定 client 有关的内容,而且不必但因会影响到其他 client 的行为。
同样,只更改 territories 组件内的一个子包也不会影响到其他的子包。这样,我们就可以快速、独立地进行跨团队开发,尤其是当我们进行的更改只影响少量 Kraken 实例的时候。
通过 Import Linter 确保项目中的分层实现
虽然引入了分层结构,但我们很快发现,仅仅在理论上论述分层是不够的。开发人员经常会不小心进行分层间的违规引入。我们需要以某种方式确保分层结构的理论能够在代码结构中被遵循,为了达到此目的我们在项目中引入了第三方库 Import Linter。
Import Linter 是一款开源工具,用于检查项目中的引用逻辑是否遵循了指定的结构。首先,我们需要在一个 INI 文件中定义一个描述目标需求的配置,类似这样:
[importlintertop-level] name = Top level layers type = layers layers = kraken.clients kraken.territories Kraken.core
我们还可以使用另外两个配置文件强制不同的 clients、territories 之间相互独立。类似这样:
# 文件 1 [importlinterclient-independence] name = Client independence type = independence layers = kraken.clients.oede kraken.clients.oegb kraken.clients.oejp ... # 文件 2 [importlinterterritory-independence] name = Territory independence type = independence layers = kraken.territories.deu kraken.territories.gbr kraken.territories.jpn ...
然后,你可以在命令行运行 lint-import,它会告诉你项目中是否有任何导入行为违反了我们配置中的要求。我们会在每次拉取代码的时候运行此功能,因此如果有人使用了不合规的导入,检查就会失败,代码也就不会被合并。
上面展示的并不是我们项目全部的配置文件。团队成员可以在应用程序的更深处添加自己的分层,例如:kranken.ritories.jpn 本身就是分层。我们目前拥有超过 40 个配置文件用于规定我们的分层结构。
消除技术债
我们没有办法在确定是由分层架构的第一时间就使整个项目符合架构需求。因此,我们使用了 Import Linter 中的一项特性,该功能允许您在检查非法导入之前忽略对某些导入的检查。
[importlintermy-layers-contract] name = My contract type = layers layers = kraken.clients kraken.territories kraken.core ignore_imports = kraken.core.customers -> kraken.territories.gbr.customers.views kraken.territories.jpn.payments -> kraken.utils.urls (and so on...)
此后,我们使用项目构建时被 Import Linter 忽略的导入语句的数量作为跟踪技术债完成度的指标。这样,我们就能观察到随着时间的推移技术债的情况是否有所改善,以及改善的速度如何。
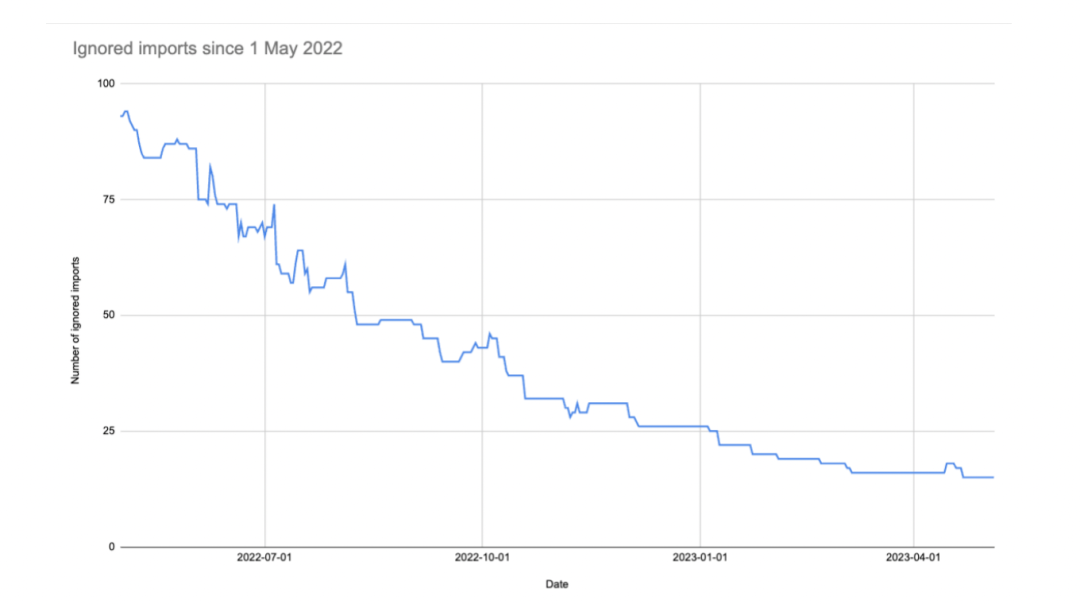 Ignored imports since 1 May 2022
Ignored imports since 1 May 2022
上图是我们过去一年多的时间里被我们忽略的有问题的引入语句数量的变化。我会定期分享这张图,想大家展示我们最新的工作进度,并鼓励我们的开发者努力做到完全遵守分层结构的约定。我们对其他几个技术债也使用了这种燃尽图的方法去展示。
没有银弹,谈谈分层架构的缺点
复杂现实
现实世界无比的复杂,依赖关系遍布在项目的各个角落。在采用分层架构后,你会经常遇到想要打破现有层级关系的情况,会经常在不经意间从低层级的组件中调用高层级的组件。
幸运的是,总有办法解决这类问题,那就是所谓的 控制反转(Ioc),在 Python 中你可以很容易地做到这一点,只是需要转换一下思维方式。不过使用这个方法会增加「局部复杂性」,但为了让项目整体变得更加简单,这点代价还是值得的。
结构中高层代码过多
在分层结构中,层数越高的组件天然地越容易更改。正因如此,我们特地简化了修改特定 clinents 或 territories 的代码流程。另一方面,core 是一切其他代码的基础,修改它就成为了一件高成本、高风险的事情。
高成本、高风险的底层代码修改行为让我们望而却步,促使我们编写更多针对特定客户或地区的高层级代码。最终的结果就是,高层的代码比我们想象中要多的多的多。我们仍在学习如何解决这个问题。
目前为止我们仍未完全完成
还记得之前提到过的被设置在 Import Linter 特殊配置文件中被忽略的 import 吗?多年过去了,它仍未被全部解决,根据统计还有最少 15 个。最后的这几个 import 也是最顽固、最难以被优化的。
我们需要付出很多的时间才能重构完一个现有项目,所以,越早分层需要面对的麻烦就越少。
总结
Kraken 的分层结构使我们在如此庞大的代码体量下仍旧保持着健康的开发和维护,而且操作难度相对较小,特别是在考虑到它的规模的情况下。如果不对数以万计的模块之间的依赖关系加以限制,我们的项目仓库很可能会像揉乱的线团一样复杂。
但是我们选择的代码架构顺利的帮助我们在单一的 Python 代码库中进行大量工作。看似不可能,但这就是事实。
如果你正在开发一个大型的 Python 项目,或者哪怕是一个相对较小的项目,不发试试分层结构,还是那句话:越早分层需要面对的麻烦就越少。
















 工商网监
工商网监
评论