 德赢Vwin官网
App
德赢Vwin官网
App


基于DSP的实时图像处理系统
引言
本文设计了基于TMS320C6000系列DSP的MPEG-4编码器。将摄像头获取的图像以MPEG-4标准进行实时压缩并通过VGA实时显示,同时把压缩好的数据通过PCI总线传输给ARM控制器,经由ARM根据实际的需要进行视频数据的网络传输。
MPEG-4 是一种开放性标准,其中许多部分都没有规定,可以加入一些新的算法,因此采用通用DSP 能够随时更新算法、优化算法,使得编码效率更高。由于MPEG-4 编码算法复杂,需要存储的数据量大,无论是存储空间分配、数据传输还是运算速度对DSP来说都是挑战。
C6000系列DSP是TI公司生产的高档DSP。这一系列DSP都是基VelociTITM构架的VLIW DSP,它在每个周期可以执行八条32bit 的指令, 具有高达200MHZ的CPU,从而使得其运算能力达到1600MIPS。而6416在600MHz主频下,只利用50%的运算能力就可以同时进行单通道MPEG-4视频编码、单通道MPEG-4视频解码和单通道MPEG-2视频编码的处理。同时其对外接口灵活、开发工具齐全,被大多数嵌入式图像实时压缩系统所采用。因此本系统采用TI公司TMS320C6416芯片为核心处理器。
1.TMS320C6416的结构及特点
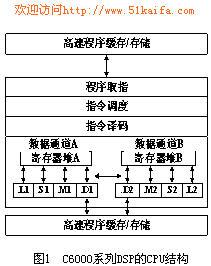
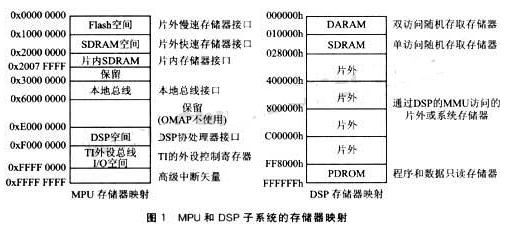
DSP的CPU结构如图1所示,它具有两个通道,每个通道具有4个功能单元(1个乘法器和3个算术逻辑单元),16个32位通用寄存器,每个通道的功能单元可以随意访问本通道的寄存器。CPU还有两个交叉单元,通过它们,一个通道的功能单元可以访问另一个通道的寄存器。另外, CPU还具有256 bit宽的数据和程序通道,可以使程序存储器在每个时钟周期提供8条并行执行指令。这种CPU结构是DSP具有VLIW结构的最基本条件。此DSP的存储空间映射为内部存储器、内部外设及扩展存储器。其中内部存储器由64KB内部程序存储器和数据存储器构成,内部程序存储器可以映射到CPU地址空间或者作为Cache操作。内部和外部数据存储器均可通过CPU、DMA或HPI(Host Interface)方式访问,HPI接口使上位机可以访问DSP的存储空间。
2.系统硬件设计
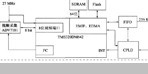
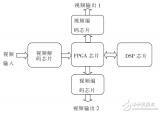
本系统主要分为三部分,分别是视频采集模块、视频的MPEG-4编码模块和视频传输模块,其结构框图如图2所示。

2.1 视频采集
在本系统中,对输入的vwin 视频信号的采集是由BT835视频Decoder完成的,支持的视频输入为PAL制或NTSC制式的标准模拟视频信号,输入的视频信号既可以是复合视频信号,也可以是S-Video信号,输出为4:2:2的YUV格式的图像数据。

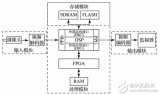
图3所示为DSP 模拟视频输入接口原理框图。标准模拟视频信号经预处理进入A/ D转换器;同时又经时钟产生电路得到与行同步同相位的A/ D 转换时钟,这样可以使得每行的采样点均为整数。为了确保视频数据整行地被采集到DSP 中进行处理,特将行同步信号作为FIFO 读入数据的起点。同时,行同步、场同步以及奇偶场标志信号也直接进入DSP ,使其能够确定读入的视频数据在一帧中的具体位置。为了增强系统的实时性,这里利用TMS320C6416 DSP 的DMA(直接存储器存取) 通道背景操作特性,以使DSP 和外设的数据交换能够与其内部CPU 的高速运算操作同时进行。而FIFO 的功能在于,通过它的缓冲,使得DSP 可以从容地与A/ D 之外的其它外设交换数据。
其中ARM7的作用是时钟的产生及控制视频采集芯片,将采得的数据从8位或16位转化为32位,并且使数据按照Y、U、V分开的方式排列。这样相当于对采集到的数据进行了一次预处理,以便于视频编码使用。另外ARM7将32位宽的数据输出给32位的FIFO。用32位的FIFO以及将视频数据转换为32位,可以使DSP读取视频数据时32位的数据总线没有空闲,从而提高DSP读取视频数据的效率;这里使用FIFO是为了减少DSP读取数据的时间、降低高速设备和低速设备的不匹配。每次FIFO半满时,ARM7会给DSP发送中断信号, 并且在中断处理程序中使用DMA方式读取视频数据;如果不使用ARM7,DSP会频繁中断,从而花费大量时间在入栈、出栈以及寄存器的设置上。
2.2 视频的MPEG-4编码模块
DSP读入视频数据后进行先期处理,如将YUV格式转为RGB格式等;然后进行MPEG-4视频编码。在这一过程中,数据访问通常要占用50%的时间,算术运算要占用30%的时间,控制要占用20%的时间。因为需要进行运动估计和运动补偿,在数据存储器中通常保存一帧I(原始帧)帧图像和至少一帧P(预测帧)帧图像,这些图像占用的空间都比较大,因此放在外部存储器SDRAM里。在编码过程中还要存储DCT系数、运动向量、量化矩阵、可变长编码表、Z形编码表等,由于占用较小的存储空间而且会反复用到,因此把它们放在片内存储器中。
2.3 视频传输
与PC 机不同,DSP 片内片外的两级存储体系结构以及数据分配原则决定了编码器实现过程中必然存在大量的数据传输,因而必须有效地管理以减少数据
传输所需的时间。
至于数据的采集部分可以利用DSP的DMA来进行。TMS320C6000 DSP 大都具有几个独立的DMA 通道,DMA 的特点是可以在不受CPU 干预的情况下完成数据从源地址到目的地址的搬移。
但是DMA 只适合于数据块的整体搬移,对于不同数据结构间的数据传输,前DSP 的DMA 控制器就无能为力了。所以可以借助ARM7控制DSPDMA 来完成视频编码中复杂的数据传输。
完成编码后的视频数据通过ARM7来进行和外界的传输,可以通过Internet、 CDMA或者GSM网络等,只需要ARM7设计相应的传输接口即可。至于ARM7与编码卡通信可以通过并口、串口、USB口、PCI接口等方式实现。其中PCI 接口方式易于ARM7与编码器高速传输数据,因此可以采用PCI接口。编码后的数据通过DSP的HPI、PCI桥芯片、PCI总线到达ARM7。ARM7通过DSP的HPI直接对DSP的存储空间进行访问。
3 软件设计及优化
3.1 视频采集
本系统在视频采集中设计了一个数据结构将空间连续的先行缓冲区转化为一个环形的缓冲区,其简单的示意图如图4所示。

采用此方法只要为这个缓冲区分配足够大的空间,使其中存放的图像帧的数目至少大于3,这样就可以保证在对图像数据进行处理的同时还可以同步进行新的图像数据的采集,而不会发生任何数据冲突。系统将会永远保留环形缓冲区中最旧的N帧图像直至被系统取走。
3.2 视频编码
MPEG-4的视频编码是基于对象的视频编码,它仍然采用传统的预测编码、运动补偿、DCT变换构成的混合编码方式。编码器的核心算法包括运动估计、DCT/IDCT、量化、VLC 等,其中运动估计占据整个编码器近四分之一的运算量。因此,研究适合DSP 结构的、在速度和编码质量之间具有良好折中的运动估计算法是实现实时编码的一个关键问题。
在视频编码中应该采用块匹配的运动估计算法,但传统的块匹配算法在匹配速度上达不到满意的效果,因此本系统采用了在三步搜索算法的基础上改进的四步搜索的块匹配算法。
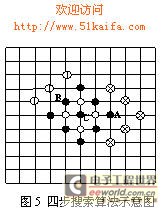
四步搜索算法描述如下:
(1)搜索匹配点组成一个菱形窗口,如图5所示。初始的9个匹配点为菱形的4个顶点、4条边的中点及菱形的中心点,如图5中的实心点。对每个点计算SAD的值,选取SAD最小的点。如果该点是此次搜索窗口的中心则跳到第4步,否则到第2步。

图5 四步搜索算法示意图
(2)以SAD最小的点为新的菱形匹配点窗口的中心点,其余的匹配点的选取按下面的原则进行。
a)如果SAD最小的点是当前搜索窗口的角上的点,如A点,则取与A点不相邻的另外5个点,如图5中的形如的点。选取SAD最小的点,并到第3步;
b)如果SAD最小的点是当前搜索窗口的边上的点,如B点,则取与B点不相邻的另外3个点,如图5中的形如的点。选取SAD最小的点,并到第3步;
c)如果SAD最小的点是当前搜索窗口的中心点C点,则到第4步;
(3)搜索模式同2,最后都到第4步。
(4)选取周围的四个点作为匹配点,步长改为1,如图5中所示的空心点。选取SAD最小的点作为最终目标点。
四步搜索算法比三步搜索算法的复杂度更小,但精度并没有降低,同时算法规则易于实现软件流水,而非常适合在DSP 上实现。
3.3 软件优化
由于图像处理的数据量大,数据处理相关性高,并且具有严格的帧、场时间限制,因此如何针对图像处理的特点对DSP 进行优化编程,充分发挥其性能就成为提高整个系统性能的关键。
要想充分发挥DSP的运算能力,必须从它的硬件结构出发,最大限度地利用八个功能单元,使用软件流水线,尽量让程序无冲突地并行执行。一般循环体都满足并行处理的条件,并且循环体往往是程序中耗时最长的。因此在进行优化时将重点放在循环体上。
1) DSP跳转指令的优化
DSP的指令多为单周期指令,但是转移类指令却通常要耗费较多的时钟周期,每个跳转都有5个延迟间隙,从性能上考虑是一项很耗时的工作,因此应尽可能地减少程序中的分支。
2) 使用库函数
TI公司对TMS320C6000的用户提供了功能强大的IMAGE LIB库支持。在这个库中,包含许多常用函数,可以完成DCT/IDCT变换、小波变换、DCT量化、自适应滤波等功能。这些函数都是优化过的,完全能够实现软件流水,效率很高。
3)存储空间的考虑
DSP存储空间的配置十分重要。因为DSP对不同的存储单元的访问速度是有区别的,对片内寄存器的访问速度最快,对片内RAM的访问速度比片外RAM的访问速度快。因此合理地配置和使用存储空间,对系统整体效率影响很大。应该尽可能地把访问比较频繁的常数表和代码段装入片内RAM,如果过大,则把其中一部分装入片外存储器。
4)混合编程
不同于传统的VLIW ,Veloci TI 采用了多种先进技术,从而使得DSP的C编译器具有很高的效率,我们称之为面向C语言结构的DSP芯片。其平均编译效率可以达到手工汇编的84 %。这使得在绝大多数应用中我们可以采用C 语言编写程序从而充分利用大量用C 描述的算法程序,并获得远胜于传统DSP程序的可维护性、可移植性、可继承性,缩短开发周期。
虽然C6000的C编译器有如此高的编译效率,但是对于MPEG-4这样复杂的算法,只运用C语言是远远不够的,一般采用C语言和汇编语言相结合的方式来完成程序设计。程序设计流程如下:先写C代码并对其优化,如果不能达到预期的运行效率,则编写汇编代码来提高效率。
4 总结
该系统非常灵活,支持的视频输入为PAL制或NTSC制式的标准模拟视频信号,输入的视频信号既可以是复合视频信号,也可以是S-Video信号。并支持多分辨率,分别为FULL、CIF和QCIF,可以满足多种应用的需求。测试证明经过以上的优化可以实现视频图像的实时压缩,同时系统运行可靠、功耗低。













 工商网监
工商网监
评论