 德赢Vwin官网 App
德赢Vwin官网 App

避障是指移动机器人在行走过程中,通过传感器感知到在其规划路线上存在静态或动态障碍物时,按照 一定的算法实时更新路径,绕过障碍物,最后达到目标点。
避障常用哪些传感器?
不管是要进行导航规划还是避障,感知周边环境信息是第一步。就避障来说,移动机器人需要通过传感器 实时获取自身周围障碍物信息,包括尺寸、形状和位置等信息。避障使用的传感器多种多样,各有不同的原理和特点,目前常见的主要有视觉传感器、激光传感器、红外传感器、超声波传感器等。下面我简单介绍一下这几种传感器的基本工作原理。
超声波
超声波传感器的基本原理是测量超声波的飞行时间,通过d=vt/2测量距离,其中d是距离,v是声速,t是 飞行时间。由于超声波在空气中的速度与温湿度有关,在比较精确的测量中,需把温湿度的变化和其它因素考虑进去。
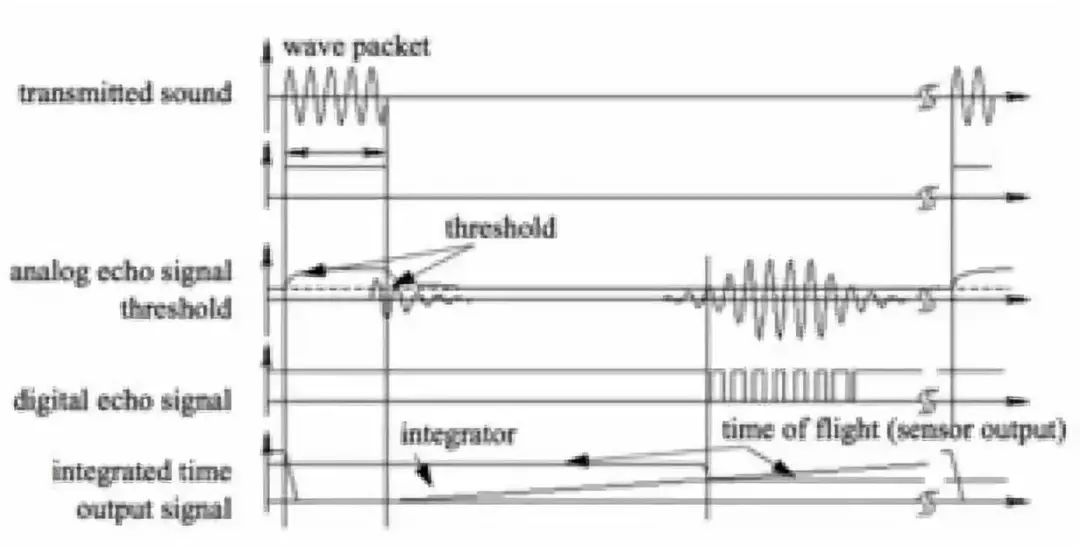
上面这个图就是超声波传感器信号的一个示意。通过压电或静电变送器产生一个频率在几十kHz的超声波脉冲组成波包,系统检测高于某阈值的反向声波,检测到后使用测量到的飞行时间计算距离。
超声波传感器一般作用距离较短,普通的有效探测距离都在几米,但是会有一个几十毫米左右的最小探测盲区。由于超声传感器的成本低、实现方法简单、技术成熟,是移动机器人中常用的传感器。超声波传感器也有一些缺点,首先看下面这个图。
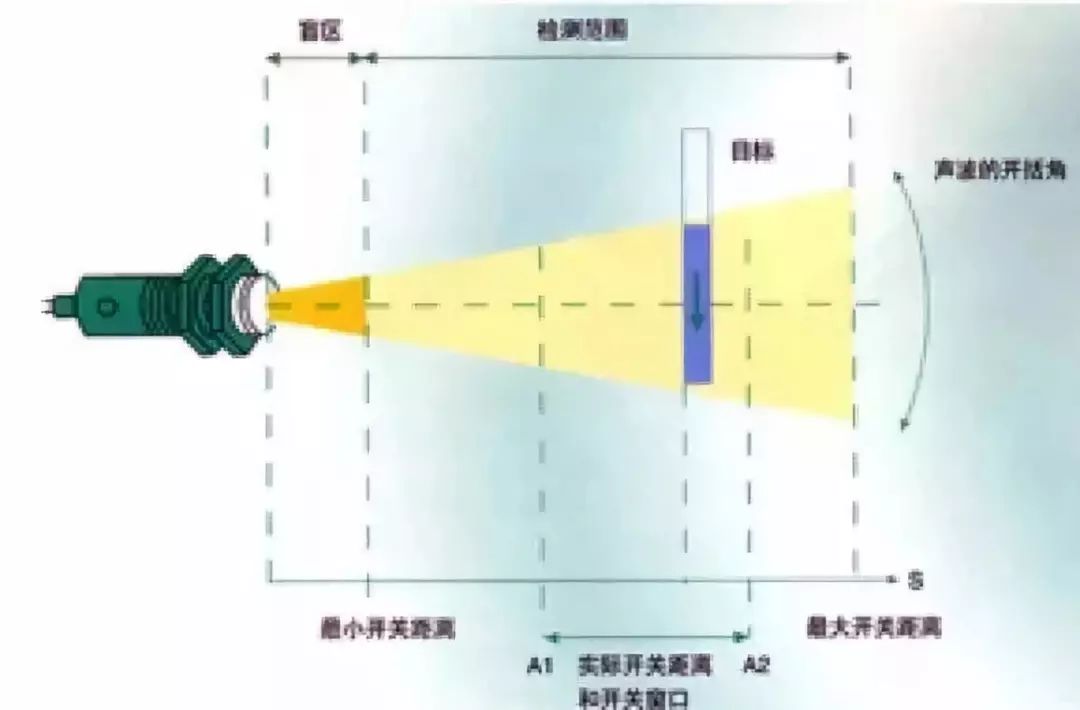
因为声音是锥形传播的,所以我们实际测到的距离并不是 一个点,而是某个锥形角度范围内最近物体的距离。 另外,超声波的测量周期较长,比如3米左右的物体,声波传输这么远的距离需要约20ms的时间。再者,不同材料对声波的反射或者吸引是不相同的,还有多个超声传感器之间有可能会互相干扰,这都是实际应用的过程中需要考虑的。
红外
一般的红外测距都是采用三角测距的原理。红外发射器按照一定角度发射红外光束,遇到物体之后,光会反向回来,检测到反射光之后,通过结构上的几何三角关系,就可以计算出物体距离D。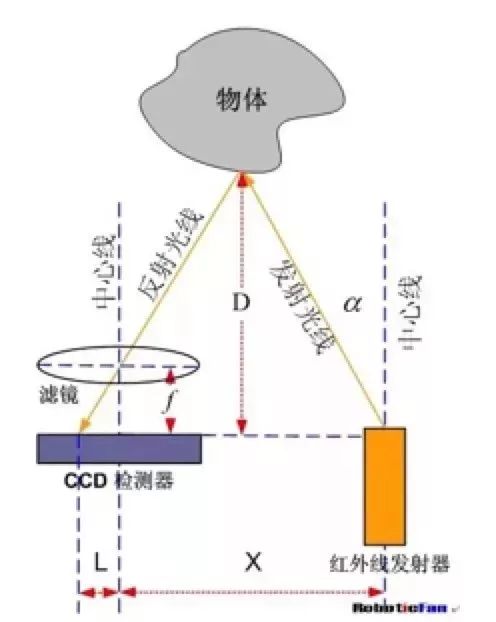
当D的距离足够近的时候,上图中L值会相当大,如果超过CCD的探测范围,这时,虽然物体很近,但是传感器反而看不到了。当物体距离D很大时,L值就会很小,测量量精度会变差。因此,常见的红外传感器 测量距离都比较近,小于超声波,同时远距离测量也有最小距离的限制。另外,对于透明的或者近似黑体的物体,红外传感器是无法检测距离的。但相对于超声来说,红外传感器具有更高的带宽。
激光
常见的激光雷达是基于飞行时间的(ToF,time of flight),通过测量激光的飞行时间来进行测距d=ct/2,类似于前面提到的超声测距公式,其中d是距离,c是光速,t是从发射到接收的时间间隔。
激光雷达包括发射器和接收器,发射器用激光照射目标,接收器接收反向回的光波。机械式的激光雷达包括一个带有镜子的机械机构,镜子的旋转使得光束可以覆盖 一个平面,这样我们就可以测量到一个平面上的距离信息。 对飞行时间的测量也有不同的方法,比如使用脉冲激光,然后类似前面讲的超声方案,直接测量占用的时间,但因为光速远高于声速,需要非常高精度的时间测量元件,所以非常昂贵;另一种发射调频后的连续激光波,通过测量接收到的反射波之间的差频来测量时间。
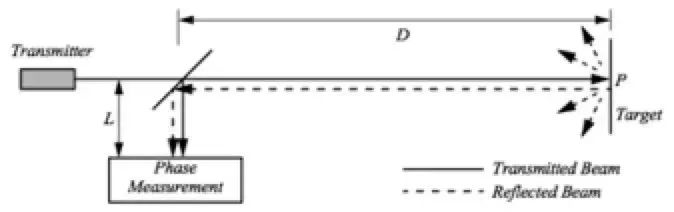
图一
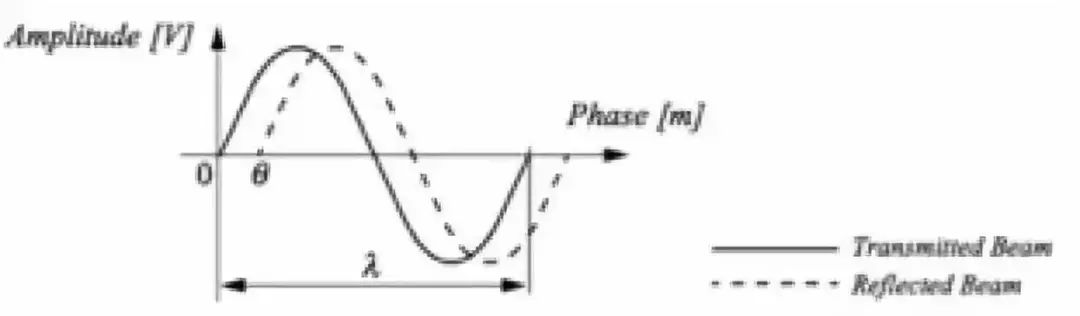
图二
比较简单的方案是测量反射光的相移,传感器以已知的频率发射一定幅度的调制光,并测量发射和反向信号之间的相移,如上图一。调制信号的波长为lamda=c/f,其中c是光速,f是调制频率,测量到发射和反射光束之间的相移差theta之后,距离可由lamda*theta/4pi计算得到,如上图二。
激光雷达的测量距离可以达到几十米甚至上百米,角度分辨率高,通常可以达到零点几度,测距的精度也高。但测量距离的置信度会反比于接收信号幅度的平方,因此,黑体或者远距离的物体距离测量不会像光亮的、近距离的物体那么好的估计。
并且,对于透明材料,比如玻璃,激光雷达就无能为力了。还有,由于结构的复杂、器件成本高,激光雷达的成本也很高。 一些低端的激光雷达会采用三角测距的方案进行测距。但这时它们的量程会受到限制,一般几米以内,并且精度相对低一些,但用于室内低速环境的SLAM或者在室外环境只用于避障的话,效果还是不错的。
视觉
常用的计算机视觉方案也有很多种, 比如双目视觉,基于TOF的深度相机,基于结构光的深度相机等。深度相机可以同时获得RGB图和深度图,不管是基于TOF还是结构光,在室外强光环境下效果都并不太理想,因为它们都是需要主动发光的。
像基于结构光的深度相机,发射出的光会生成相对随机但又固定的斑点图样,这些光斑打在物体上后,因为与摄像头距离不同,被摄像头捕捉到的位置也不相同,之后先计算拍到的图的斑点与标定的标准图案在不同位置的偏移,利用摄像头位置、传感器大小等参数就可以计算出物体与摄像头的距离。而我们目前的E巡机器人主要是工作在室外环境,主动光源会受到太阳光等条件的很大影响,所以双目视觉这种被动视觉方案更适合,因此我们采用的视觉方案是基于双目视觉的。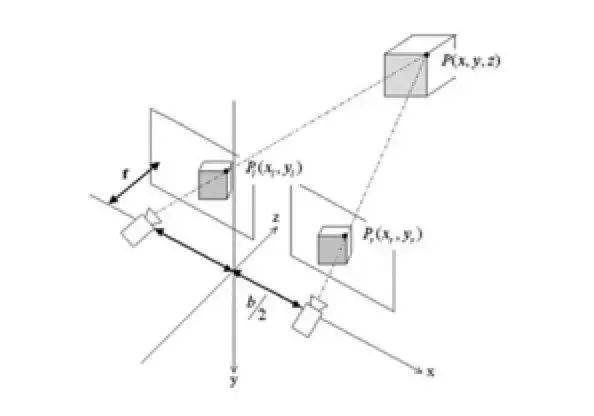
双目视觉的测距本质上也是三角测距法,由于两个摄像头的位置不同,就像我们人的两只眼睛一样,看到的物体不一样。两个摄像头看到的同一个点P,在成像的时候会有不同的像素位置,此时通过三角测距就可以测出这个点的距离。与结构光方法不同的是,结构光计算的点是主动发出的、已知确定的,而双目算法计算的点一般是利用算法抓取到的图像特征,如SIFT或SURF特征等,这样通过特征计算出来的是稀疏图。
要做良好的避障,稀疏图还是不太够的,我们需要获得的是稠密的点云图,整个场景的深度信息。稠密匹配的算法大致可以分为两类,局部算法和全局算法。局部算法使用像素局部的信息来计算其深度,而全局算法采用图像中的所有信息进行计算。一般来说,局部算法的速度更快,但全局算法的精度更高。
这两类各有很多种不同方式的具体算法实现。能过它们的输出我们可以估算出整个场景中的深度信息,这个深度信息可以帮助我们寻找地图场景中的可行走区域以及障碍物。整个的输出类似于激光雷达输出的3D点云图,但是相比来讲得到信息会更丰富,视觉同激光相比优点是价格低很多,缺点也比较明显,测量精度要差 一些,对计算能力的要求也高很多。当然,这个精度差是相对的,在实用的过程中是完全足够的,并且我们目前的算法在我们的平台NVIDIA TK1和TX1上是可以做到实时运行。
KITTI采集的图

实际输出的深度图,不同的颜色代表不同的距离
在实际应用的过程中,我们从摄像头读取到的是连续的视频帧流,我们还可以通过这些帧来估计场景中 目标物体的运动,给它们建立运动模型,估计和预测它们的运动方向、运动速度,这对我们实际行走、避障规划是很有用的。 以上几种是最常见的几种传感器 ,各有其优点和缺点,在真正实际应用的过程中,一般是综合配置使用多种不同的传感器 ,以最大化保证在各种不同的应用和环境条件下,机器人都能正确感知到障碍物信息。我们公司的E巡机器人的避障方案就是以双目视觉为主,再辅助以多种其他传感器,保证机器人周边360度空间立体范围内的障碍物都能被有效侦测到,保证机器人行走的安全性。
避障常用算法原理
在讲避障算法之前,我们假定机器人已经有了一个导航规划算法对自己的运动进行规划,并按照规划的路径行走。避障算法的任务就是在机器人执行正常行走任务的时候,由于传感器的输入感知到了障碍物的存在,实时地更新目标轨迹,绕过障碍物。
Bug算法知乎用户无方表示
Bug算法应该是最简单的一种避障算法了,它的基本思想是在发现障碍后,围着检测到的障碍物轮廓行走,从而绕开它。Bug算法目前有很多变种, 比如Bug1算法,机器人首先完全地围绕物体,然后从距目标最短距离的点离开。Bug1算法的效率很低,但可以保证机器人达到目标。
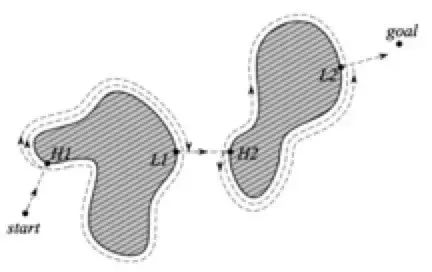
Bug1算法示例
改进后的Bug2算法中,机器人开始时会跟踪物体的轮廓,但不会完全围绕物体一圈,当机器人可以直接移动至目标时,就可以直接从障碍分离,这样可以达到比较短的机器人行走总路径。
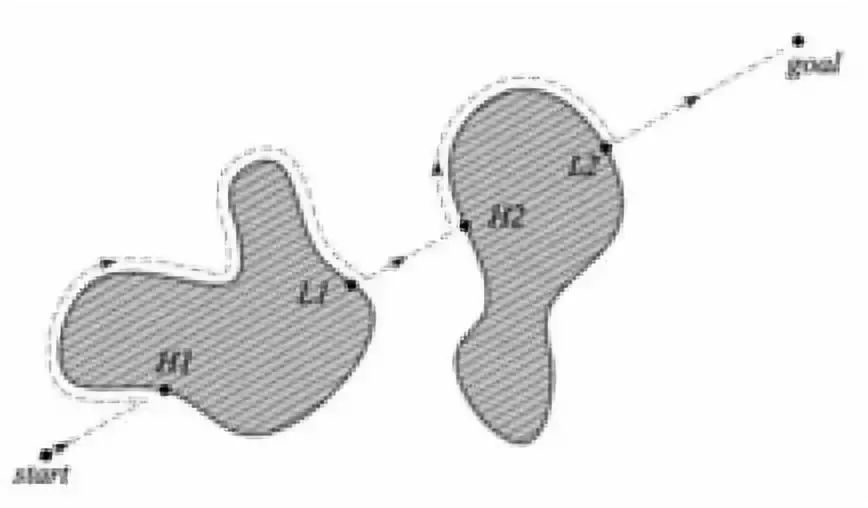
Bug2算法示例
除此之外,Bug算法还有很多其他的变种, 比如正切Bug算法等等。在许多简单的场景中,Bug算法是实现起来比较容易和方便的,但是它们并没有考虑到机器人的动力学等限制,因此在更复杂的实际环境中就不是那么可靠好用了。
势场法(PFM)
实际上,势场法不仅仅可以用来避障,还可以用来进行路径的规划。势场法把机器人处理在势场下的 一个点,随着势场而移动,目标表现为低谷值,即对机器人的吸引力,而障碍物扮演的势场中的一个高峰,即斥力,所有这些力迭加于机器人身上,平滑地引导机器人走向目标,同时避免碰撞已知的障碍物。当机器人移动过程中检测新的障碍物,则需要更新势场并重新规划。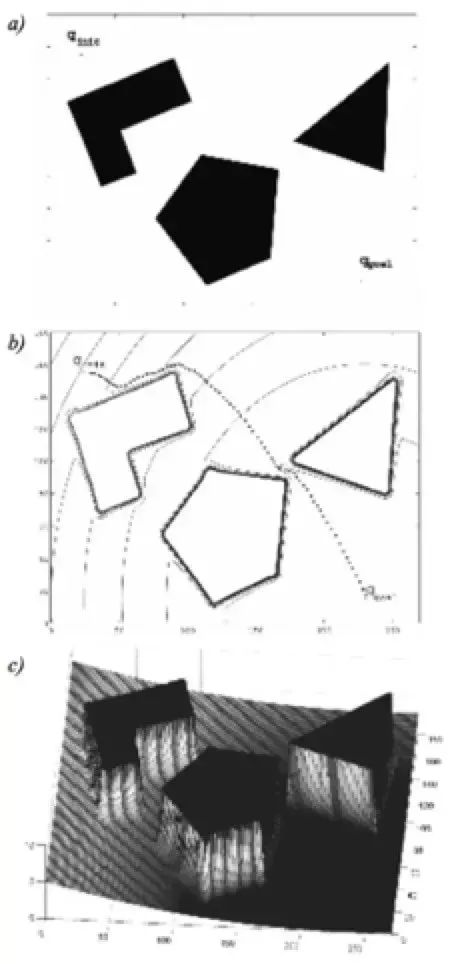
上面这个图是势场比较典型的示例图,最上的图a左上角是出发点,右下角是目标点,中间三个方块是障碍物。中间的图b就是等势位图,图中的每条连续的线就代表了一个等势位的一条线,然后虚线表示的在整个势场里面所规划出来的一条路径,我们的机器人是沿着势场所指向的那个方向一直行走,可以看见它会绕过这个比较高的障碍物。
最下面的图,即我们整个目标的吸引力还有我们所有障碍物产生的斥力最终形成的一个势场效果图,可以看到机器人从左上角的出发点出发,一路沿着势场下降的方向达到最终的目标点,而每个障碍物势场表现出在很高的平台,所以,它规划出来的路径是不会从这个障碍物上面走的。
一种扩展的方法在基本的势场上附加了了另外两个势场:转运势场和任务势场。它们额外考虑了由于机器人本身运动方向、运动速度等状态和障碍物之间的相互影响。
转动势场考虑了障碍与机器人的相对方位,当机器人朝着障碍物行走时,增加斥力, 而当平行于物体行走时,因为很明显并不会撞到障碍物,则减小斥力。任务势场则排除了那些根据当前机器人速度不会对近期势能造成影响的障碍,因此允许规划出 一条更为平滑的轨迹。 另外还有谐波势场法等其他改进方法。势场法在理论上有诸多局限性, 比如局部最小点问题,或者震荡性的问题,但实际应用过程中效果还是不错的,实现起来也比较容易。
向量场直方图(VFH)
它执行过程中针对移动机器人当前周边环境创建了一个基于极坐标表示的局部地图,这个局部使用栅格图的表示方法,会被最近的一些传感器数据所更新。VFH算法产生的极坐标直方图如图所示:
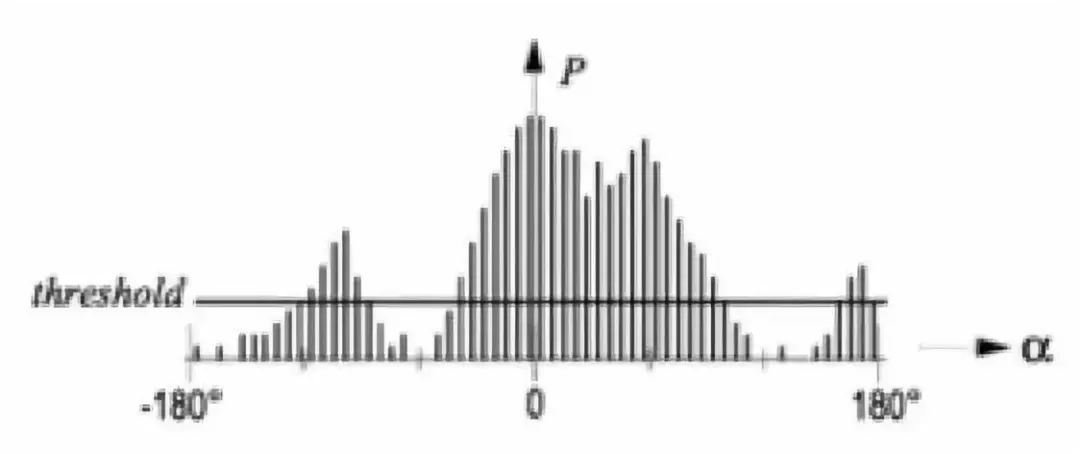
图中x轴是以机器人为中心感知到的障碍物的角度,y轴表示在该方向存在障碍物的概率大小p。实际应用的过程中会根据这个直方图首先辨识出允许机器人通过的足够大的所有空隙,然后对所有这些空隙计算其代价函数,最终选择具有最低代价函数的通路通过。
代价函数受三个因素影响:目标方向、机器人当前方向、之前选择的方向,最终生成的代价是这三个因素的加权值,通过调节不同的权重可以调整机器人的选择偏好。VFH算法也有其他的扩展和改进,比如在VFH+算法中,就考虑了机器人运动学的限制。
由于实际底层运动结构的不同,机器的实际运动能力是受限的,比如汽车结构,就不能随心所欲地原地转向等。VFH+算法会考虑障碍物对机器人实际运动能力下轨迹的阻挡效应,屏蔽掉那些虽然没有被障碍物占据但由于其阻挡实际无法达到的运动轨迹。我们的E巡机器人采用的是两轮差动驱动的运动形式,运动非常灵活,实际应用较少受到这些因素的影响。
具体可以看 一下这个图示:
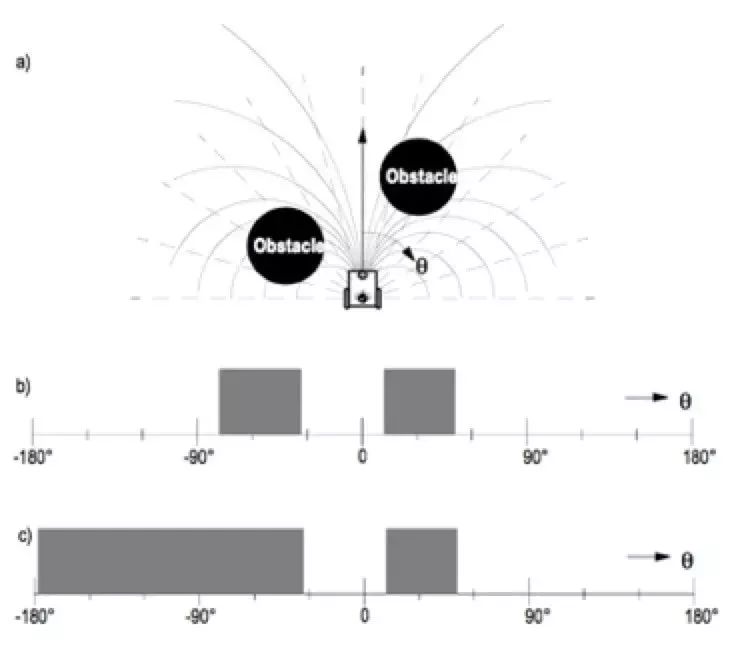
类似这样传统的避障方法还有很多,除此之外,还有许多其他的智能避障技术,比如神经网络、模糊逻辑等。 神经网络方法对机器人从初始位置到目标位置的整个行走路径进行训练建模,应用的时候,神经网络的输 入为之前机器人的位姿和速度以及传感器的输 入,输出期望的下一目标或运动方向。
模糊逻辑方法核心是模糊控制器,需要将专家的知识或操作人员的经验写成多条模糊逻辑语句,以此控制机器人的避障过程。比如这样的模糊逻辑:第一条,若右前方较远处检测到障碍物,则稍向左转;第 二条,若右前方较近处检测到障碍物,则减速并向左转更多角度;等等。
审核编辑:刘清







 工商网监
工商网监
评论