 德赢Vwin官网
App
德赢Vwin官网
App


机器学习的可解释性
来源:《计算机研究与发展》,作者陈珂锐等
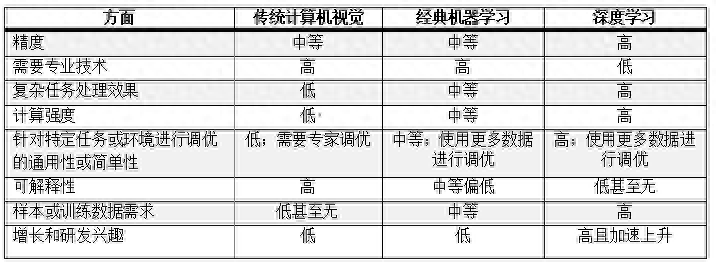
摘 要 近年来,机器学习发展迅速,尤其是深度学习在图像、声音、自然语言处理等领域取得卓越成效.机器学习算法的表示能力大幅度提高,但是伴随着模型复杂度的增加,机器学习算法的可解释性越差,至今,机器学习的可解释性依旧是个难题.通过算法训练出的模型被看作成黑盒子,严重阻碍了机器学习在某些特定领域的使用,譬如医学、金融等领域.目前针对机器学习的可解释性综述性的工作极少,因此,将现有的可解释方法进行归类描述和分析比较,一方面对可解释性的定义、度量进行阐述,另一方面针对可解释对象的不同,从模型的解释、预测结果的解释和模仿者模型的解释3个方面,总结和分析各种机器学习可解释技术,并讨论了机器学习可解释方法面临的挑战和机遇以及未来的可能发展方向.
关键词 机器学习;可解释性;神经网络;黑盒子;模仿者模型
纵观机器学习的历史发展进程,其最初的目标是从一系列数据中寻找出可以解释的知识,因而在追求算法性能的同时,也很注重算法的可解释性.典型的代表譬如线性感知机、决策树、k近邻算法等.进入20世纪80年代之后,伴随神经网络的复苏,机器学习算法在设计时开始放弃可解释性这一要求,强调提高算法泛化的性能.神经网络的激活函数的选择不再局限于线性函数,而采用非线性的譬如Sigmoid,tanh,Softmax,Relu等函数,一方面其表示能力大幅度提高,另一方面,随着其模型复杂度的增加,算法的可解释性就更差.
然而,机器学习解释技术具有巨大的潜在应用空间.譬如科学家在知识发现的过程中,可解释的机器学习系统可以帮助他们更好地理解输出的知识,并寻找各种因素之间的相关性;对于一些复杂任务的端到端系统,几乎无法完全测试,也无法创建系统可能失败的完整场景列表,人类无法枚举出所有可能出现的计算上或者逻辑上的不可行输出,系统的可解释性对于系统的理解则至关重要;需要防范可能产生某些歧视的场景,即使我们有意识将某些特定的受保护类编码到系统中,也仍然存在考虑欠缺的先验偏见,譬如种族歧视[1-3]、性别歧视等.
对机器学习的可解释性需求不仅仅来源于上述的需求,同时还来源于法律法规.欧盟于2018年5月生效的GDPR(General Data Protection Regulation)中有条例明确规定,当机器针对某个个体作出决定时,该决定必须符合一定要求的可解释性.
NIPS2017的工作组曾针对“可解释性在机器学习中是否必要”这一问题展开激烈的讨论[4].并非所有的机器学习系统都需要可解释性,譬如邮政编码分类、航空器防撞系统等都是在没有人类干预的情况下运行,不需要解释.但是在医疗保健、金融等行业而言,模型的可解释性不仅重要而且非常必要.譬如在医疗保健方面,护理人员、医生和临床专家都依赖于新的医疗技术来帮助他们监控和决策患者护理,一个良好的可解释性模型被证明可以提高临床工作人员的解决问题的能力,从而提高患者护理质量[5-7].通常对于系统出现不可接受的结果且无法造成重大后果的情况下,或者在实际应用中,人们已经充分地研究和验证出现的问题,即使系统表现不太完美,人们也愿意相信系统的决定.在类似的场景下,对可解释性是没有需求的.
近几年来针对机器学习的可解释性综述性的工作陆续出现,每个学者从不同的研究角度和侧重点进行概述说明.
Miller[8]从哲学、心理学和认知科学的角度对解释的定义、生成、选择、评估和呈现给予说明,展现人们在研究机器学习可解释过程中的某种认知偏见和社会期望.Zhou等人[9]认为机器学习缺乏解释既是实际问题也是道德问题,根据解释的概念和黑盒子系统的类型不同,对目前的解释技术进行了分类总结.
Gilpin等人[10]重点描述了可解释技术在人机交互领域(human computer interaction, HCI)、黑盒模型和其他领域的应用说明.Carvalho等人[11]阐述可解释性问题的重要性,并粗粒度地给出3种体系的分类归纳:Pre-Model VS In-Model VS Post-Model、内在(intrinsic)VS Hoc以及特异性模型(model-specific)VS不可知模型(model-agnostic).Brian等人[12]提出可解释地预测与可解释模型之间的区别,前者侧重于解释模型预测的结果,通常以个体特征的贡献角度来诠释,而后者从模型本身出发进行解释.还有部分的研究者关注特定研究领域的可解释性.譬如:Zhang等人[13]聚焦卷积神经网络(convolutional neural networks, CNNs)的可解释研究工作.Tjoa等人[14]则关注医疗领域的可解释性工作.纪守领等人[15]侧重可解释技术的应用和安全领域的研究工作.
本文立足于机器学习的可解释技术,借鉴和扩展Brian[12]提出的分类框架,对可解释技术的最新研究进展进行综述.一方面对可解释性的定义、度量进行阐述,另一方面针对可解释对象的不同,从模型的解释、预测结果的解释和模仿者模型3个方面,总结和分析各种机器学习可解释技术.
1 基础知识
1.1 可解释定义
目前,关于机器学习的可解释性没有明确的定义,Liu等人[16]给出定义为:“解释是指解释给人听的过程”.Doshi-Velez等人[17]也提出类似的定义.解释意味着提供可理解的术语来说明一些概念.这些定义隐含地假设,解释是由一些可理解的术语表达概念来构成,这些概念是自包含的,不需要进一步解释.
目前文献中用于描述可解释性的英文单词有解释(interpretation)、解释(explanation)和理解(under-standing).Montavon等人[18]给出了区别定义:Interpretation表示将抽象概念(例如预测类)映射到人类可以理解的领域中;Explanation是一个可解释域的特征集合,用于解释给定实例的决策(譬如分类、回归等)处理过程;Understanding指对模型的功能性解释.
1.2 形式化描述
令D={x1,x2,…,xm}表示包含m个示例的数据集,(xi,yi)表示第i个样例,yi∈y是示例xi的标记,y表示输出空间.给定一个数据集D={(x1,y1),(x2,y2),…,(xm,ym)}和一个预测器p.
1) 模型解释
模型解释的任务是从数据集D和预测器p中建立映射f:(xm→y)×(xn×m×yn)→(xm→y),解释函数fE:(xm→y)→ε,ε表示人类能理解的逻辑值.
2) 预测结果解释
预测结果解释的任务是从数据集D和预测器
p中建立映射f:(xm→y)×(xn×m×yn)→(xm→y),解释函数fE:(xm→y)×xm→ε,解释过程中使用数据记录xm的特征值.
3) 模仿者模型解释
模仿者模型解释的任务是从数据集D和预测器p中建立映射f:xm→y,解释模型函数fE:(xm→y)→ε,且ε≈y.
2 主要研究方向和可解释研究框架
2.1 主要研究方向
解释技术最早出现在基于上下文规则的专家系统中,早在20世纪70年代,Shortliffe等人[19]就讨论了解释专家系统决策过程的必要性.
目前,可解释技术的研究方向主要由表1所示,包括解释理论和机器学习的可解释.解释理论的研究最早可以追溯到20世纪90年代,Chajewska等人[20]在通用的概率系统中提出解释的正式定义.最近则是2017年,Doshi-Velez等人[21]提出的分别以应用为基础、以人类为基础、以功能为基础的3种方法的分类,从而评估机器学习的人类可解释性.其理论的发展伴随应用场景的变化而发生改变.
Table 1 The Main Research Directions of Interpretation and Understanding Technology
表1 解释技术的主要研究方向
Fig. 1 The framework of interpretation and understanding in machine leaning
图1 机器学习的可解释研究框架
对于机器学习的可解释技术发展而言,早期主要关注传统统计机器学习的方法,譬如基于规则的浅层模型的解释、决策树等.现阶段大部分的研究聚焦于深度学习的可解释性,无论是学界还是业界,越来越多的学者注意到深度模型可解释的重要性和急迫性,未来在此方向将出现更多的研究思路和解决方案.
2.2 机器学习的可解释研究框架
人类认知科学中,人类会根据详细的逻辑推理来做决定,于是可以通过一步一步地展示推理过程来清楚地解释决策是如何做出.在这种情况下,决策模型是透明的.另外,人类也会先做出直觉决策,然后寻求对决策的解释,这属于事后解释法.依据这2种建模哲学构建机器学习的可解释技术研究框架如图1所示:机器学习处理流程通常将数据集划分为训练集和测试集,训练数据集经过训练模型得到预测模型,测试数据流入到预测模型,最终给出预测结果.围绕机器学习的处理流程,可解释工作主要围绕在模型和结果解释(result interpretation)两个环节上,对于模型的解释又分为模型解释(model understanding)和模仿者模型解释(mimic model understanding)两种方式,因此,本文将现存在的可解释技术按照上述的框架进行研究和总结分析.
3 机器学习模型的解释技术
3.1 基于规则的解释
基于规则的解释通常使用容易被人类理解的规则模型,譬如决策树和决策列表.Bastani等人[26]提出一种学习决策树的模型提取算法,该算法对新输入的数据主动采样,并利用复杂模型对其进行标记,生成新的训练数据集,最后使用决策树作为全局解释.该学习决策树是非参数的,又高度的结构化,因此是可解释的.Andrews等人[27]概括总结各种基于解释规则的方式,提供对复杂模型的理解.
除了树模型的规则解释之外,还有针对神经网络的规则提取.Bondarenko等人[28]总结基于神经网络规则提取的分解法(decompositional rule extraction method),为网络中每一个隐藏单元都映射一条规则,最终形成复合规则库,并用于整个复杂网络的解释.
3.2 激活值最大化
激活值最大化思想主要是寻找能使一个给定的隐层单元的激活函数值最大的输入模式,即理解哪些输入会产生最大的模型响应.
Dumitru等人[29]将激活值最大化技术应用于受限玻尔兹曼机(restricted Boltzmann machines,RBMs)进行叠加和自编码器去噪后所得到的网络中,通过研究网络中单个单元的响应,更好地深入理解该网络的体系结构和表示.
激活值最大化可看作一个优化问题,假设θ表示神经网络的参数(权重或者偏置),hij(θ,x)是给定层j对给定单元i的激活函数,x表示输入样本,ε是用于解释的输入特征值,激活最大化的目标变为
ε=arg max hij(θ,x).
(1)
式(1)问题通常是非凸优化问题,也就是该问题存在诸多个局部最大值.目前最简单易行的方法是通过梯度下降法(gradient descent)来寻找一个局部最大值.最终模型解释借助于一个或者多个最大值进行描述解释.
将上述的激活值最大化应用到深度置信网络(deep belief network, DBN)中,可转化为寻找
P(hij=1|x)的问题.进而推广到深度神经网络(deep neural network, DNN)框架下,假定DNN分类器映射一系列数据x到一组类ωc中,则转化为求解maxx
该问题在优化的过程中有诸多的优化策略,可以采取类似于L2范数正则化或者Gaussian RBM的专家策略,或者进行特定抽样,然后在decoding函数下映射到原始输入域.Simonyan等人[30]将该方法推广到卷积神经网络上,构造了一个深度卷积网络ConvNets,采取L2正则化进行优化.
激活值最大化方法相比于基于规则的解释,其解释结果更准确.但是该方法只适用于连续型数据,无法适用于自然语言处理模型.
3.3 隐层神经元分析
隐层神经元分析方法的主要思想是借助分析与可视化神经网络模型中隐层神经元的局部特征,从而解释深度神经网络的预测行为.该方法常见于图像处理领域.
对于隐层神经元的分析工作最初见于AlexNet,Krizhevsky直接可视化了神经网络的第1个卷积层的卷积核,其重构出的图像基本是关于边缘、条纹及颜色的信息,因此该方法局限于可视卷积核的1层卷积层[43].
Zeiler等人[31]利用反卷积的方法对隐藏层的特征进行可视化,反卷积操作可看作卷积网络的逆操作.该方法以各隐藏层得到的特征图为输入,进行反卷积操作,最终得到的结果再去验证各个隐藏层提取到的特征图.实验结果表明经过CNN网络的学习,各个卷积层学习到的特征是有辨别性的.对于图像领域而言,隐藏层的最初几层主要学习到背景信息,而随着层数的提高,其学到的特征更加抽象.Zeiler的工作真正可以可视化多层卷积层.
上述2种方法都属于无参数化的可视技术.提出的方法旨在可视化和理解具有最大池化和校正线性单元的卷积神经网络的特征,从而形成一个可视化的解释模式.
Yosinski等人[32]在之前的可视化技术基础之上提出2种解释工具:第1种可视化实时卷积激活,可看出用户输入后如何实时地影响卷积层的工作;第2种利用图像空间中正则化优化技术,从而展示DNN每层的特征.Yosinski在数据集ImageNet上进行训练,首先对所有的输入训练样本减去ImageNet中每个像素的均值,得到网络的输入数据x看作以0为中心的输入.然后构建一个目标函数:
(2)
其中,ε是可视化的结果,ai(x)是激活函数,而Rθ(x)是正则项.为了便于求解出结果,借助于公式

(3)
进行更新.经过正则项来更新x,Yosinski等人[32]给出4种正则化方法:L2衰变、高斯模糊、小范式裁剪像素(clipping pixels with small norm)和小贡献裁剪像素(clipping pixels with small contribution).
Yosinski等人[32]提出的第2种工具属于参数化的可视工具,需要简单的配置安装,即可对CNN模型的隐层神经元进行可视化.
除此之外,隐层神经元分析解释的方法还可以借助重构图像的方法来实现,并取得较好的效果.
Dosovitskiy等人[44]针对传统的计算机视觉图像特征HOG(histograms of oriented gradient)[45],SIFT(scale invariant feature transform)[46],LBP(local binary patterns)[47]和AlexNet网络的每层特征2种类型进行图像重建.
类似的工作还有Mahendran等人[48],给定一个输入图片x∈RC×H×W,其中C表示颜色通道,H表示图片高度,W表示图片的宽度,表征函数Φ:RC×H×W→Rd,特征值Φ0=Φ(x0),则重构图像ε即可表示为如下的目标函数:
(4)
其中,正则项优化主要采用α范式和总变差(total variation, TV),该方法主要优化了特征向量间的误差,并且需要借助人工设置的先验知识,比较而言,Dosovitskiy等人 [44]的工作更多地考虑图像重建误差,再者是根据隐型的方式学习了图像中的先验知识.
区别于前面几种图像领域的隐层神经元分析方法,侯博建和周志华[33]对递归神经网络(recursive neural network, RNN)进行解释,其基于如下的观察:如果RNN的每个隐藏层表示为一个向量或者一个点,向RNN中输入多个序列后,将出现积累大量的隐藏状态点,并且还倾向于构成集群的现象.这个观察假设在最小门控单元(minimal gated unit,MGU)、简版RNN(simple RNN, SRN)、门控循环单元(gated recurrent unit, GRU)和长短期记忆网络(long short-term memory, LSTM)上通过实验都得以验证.于是,他们提出在训练数据集上训练RNN,然后将验证数据集中所有隐藏层标注为一个点并执行聚类,最终学习到一个验证数据集上的有限状态机(finite state automaton, FSA),并用FSA对RNN做出解释,阐述RNN的性能如何受到门控数量的影响,以及数值隐藏状态转换背后的语义含义.该方法借用FSA对RNN内部机制进行透视.
虽然隐层神经元分析的方法提供了每个隐藏神经元的定性分析,然而该做法并不能对每个神经网络的整体机制提供太多可操作和定量的分析.
3.4 分离式表征
Zhou等人[34-35]认为对于大型的深度神经网络而言,人类可理解的概念常常成为这些深度网络中的个体潜在变量,而这些网络可以自发学习分离式表征(disentangled representation),因而提出一种网路分割(network dissection)的方法来评估隐藏层和一系列语义概念之间的契合度,从而对深度网络做出解释.该方法处理如图2所示:
Fig. 2 The processing of disentangled representation
图2 分离式表征处理流程
分离式表征解释方法大致可以分成3步:
Step1. 人工创建一个视觉语义概念数据集Broden,其中包含的每张图片都富含像素(pixel-wise)标签(颜色、纹理、场景、物体等),即对于每种语义概念都有一张标记映射(label map),图2中Broden数据集中每张图片标记成猫、自行车和塔等;
Step2. 对于一个训练好的模型S,输入Broden所有的图片,收集神经网络中某个隐藏单元在Broden所有图片上的响应图,这些响应较大的区域即是该隐藏层的语义表征,将得到一个二值的mask值;
Step3. 利用IoU量化隐层的语义表征mask和概念对标记映射之间的匹配程度,从而利用标记映射(label map)解释神经网络的某隐藏层所表示的含义.
分离式表征的方法和3.3节中介绍的隐层神经元分析是一个相反的过程,前者是利用给隐藏单元计算匹配度并打标签的方式来正向解释隐藏层学习的特征,而后者是通过反向机制,重构各隐藏层的提取特征.分离式表征的解释方法效率较高,但是其准确度受限于语义概念数据集的大小以及其描述能力.
3.5 注意力机制
注意力机制(attention mechanism)[49]主要是在Encoder + Decoder模型框架下提出的,解决了该框架下输入数据中的各个部分具有相同权重的问题,为模型赋于区分辨别关键重要信息的能力.
目前广泛应用于图像处理[50-53]、自然语言处理[54]、语音识别[55]等领域,并取得较好的结果.在这些应用中依据对齐算法为每个部分赋予不同的权重,注意力机制可以很好地解释输入与输出之间的对齐关系,解释说明模型学到的内容,可以为我们打开机器学习模型的黑箱提供了一种可视方法.
Xu等人[53]提出确定性软注意力(deterministic “soft” attention)和随机硬注意力(stochastic “hard” attention)两种机制.确定性软注意力是参数化的,可被嵌入到模型中直接训练.而随机硬注意力不会选择整个Encoder的输出为其输入,以概率采样的形式选择Encoder端输出的部分数据来进行计算,为了实现梯度的反向传播,通常需要采用蒙特卡洛采样的方法来估计模块的梯度.2种注意力机制各有利弊,因为前者可直接求导,进行梯度反向传播,因此,目前更多的研究和应用倾向于使用确定性软注意力.
注意力模型中采用多种对齐函数[56]:
(5)
其中,
(6)
其中,f(mt,ms)表示源端到目标端的对齐程度,常见有点乘(dot)、权值网络映射(general)和concat映射3种方式.
目前,注意力机制被用于解释各类任务的预测.Xu等人[53],对于给定输入数据为图像,而输出数据为该图像的英文描述的任务,使用注意力机制来解释输出的英文描述中某个词语与图片中某个区域的高度依赖关系.
Chorowski等人[55]采用基于混合注意力机制的新型端到端可训练语音识别方法,应用于基于注意力的递归序列生成器(attention-based recurrent sequence generator, ARSG)之上,借助内容和位置信息,选择输入系列中下一个位置用于解码,并很好地解释输入端的声音片段和输出序列的音素之间的对应关系.Bahdanau等人[57]利用注意力机制表示输出序列中每个单词与输入序列中的某个特定单词的关联程度,从而解释法语到英语单词之间的对应关系.
Rocktäschel等人[58]应用长短期记忆网络LSTM的神经模型,可1次读取2个句子来确定它们之间的蕴含关系,而非传统地将每个句子独立映射到一个语义空间方式.该模型利用逐词(word-by-word)的注意力机制解释了前提和假设中词和词之间的对应关系.
Rush等人[59]设计了基于注意力机制的神经网络用于摘要抽取工作,注意力机制解释了输入句子和输出摘要之间的单词对应关系.
根据注意力的2种机制和对齐函数的分类标准,将各种神经网络的注意力机制整理成表2所示:
Table 2 The Summary of Attention Mechanism Explanation Methods
表2 注意力机制解释方法总结
注意力机制能否用于模型解释,目前仍存在一些争议.Jain等人[61]认为基于梯度的机制下,注意力机制学习到的注意力权重值不总能够正确地解释特征的重要性,同时不同的注意力分布可能也会得到相同的预测结果,因此认为注意力机制不能作为模型解释的一种手段.部分学者认为其实验设计有诸多不妥,例如基准的注意力权重值是随意设置的,本应该由模型的其他图层参数共同决定;模型预测结果的变化和注意力得分变化之间缺乏可比性等.本文认为注意力机制是可以被用来解释模型决策,但是该方法缺乏解释的一致性,相似的2个数据点,其解释的注意力分布和注意力权重值可能会有变化.
4 预测结果和解释技术
4.1 敏感度分析
敏感度分析[62]是研究如何将模型输出不确定地分配给不同的模型输入.该方法应用在预测结果的解释上,多数是建立在模型的局部梯度估计或者其他的一些局部变量测量的基础之上[63-65].该方法的理论基础来源于Sundararajan等人[66]认为深度学习模型具有2个基本公理:敏感性和实现不变性.
敏感度分析常使用如下的公式来定义相关性分数:
(7)
其梯度的值在数据点x处估计,最终输出那些最相关的输入特征,也即是最敏感的特征.该方法并不能解释函数f(x)本身,仅能解释函数f(x)的变化.
Cortez等人[63-65]使用梯度和变量等因素来衡量敏感度的程度.另外,Baehrens等人[67]引入解释向量来解释分类器分类的行为,其定义贝叶斯分类器为
(8)
而解释向量定义为
fE(x0)
(9)
其中,fE(x0)和x0维度相同,都是d,分类器g*(x)将数据空间Rd至多划分成C份,g*是常量.解 释向量fE(x0)在每个部分上都定义了1个向量场,该向量场表征是远离相应类的流向,从而具有最大值的fE(x0)中的实体突出显示了影响x0的类标签决策特征,然后使用高亮技术可视化高度影响决策结果的那些特征,从而很好地解释决策结果.
为了更好地量化类似梯度、变量等因素的影响,Datta等人[68]设计一套定量输入影响(quantitative input influence, QII)用于衡量模型的输入因素对预测输出结果的影响.
4.2 泰勒分解
采用泰勒分解的方法来解释预测结果,主要依靠分解函数值f(x)为相关分数之和[69].简单的泰勒分解通过识别函数在某个根点
处的一阶泰勒展开式的项,得到相关度的得分,该根点
是满足
的点,则一阶泰勒展开式为
(10)
其中,Ri(x)为相关度分数,d是输入数据的尺寸大小,b表示二阶或者更高阶的多项式.对于多数的线性模型,譬如ReLU函数,其二阶或者更高阶的多项式趋向为0,因此可以将式(10)简化为
Li等人[70]在泰勒展开式基础上,还利用表示绘图方法对自然语言处理(natural language process,NLP)领域中的文本进行解释.Montavon等人[71]将其扩展为深度泰勒展开式,重新分配当前层和其下一层之间的相关度值.深度泰勒展开式为
(11)
其中,
表示当前层的所有神经元,
表示更低一层的神经元.通过将解释从输出层反向传播到输入层,有效地利用了网络结构.该方法借助空间响应图[72]来观察神经网络输出,同时在像素空间中滑动神经网络来构建热图.根据泰勒展开式的拟合特性,深度泰勒分解[71]准确度明显高于简单的泰勒分解[69],但前者比后者的计算量和复杂度更高.泰勒分解的方法适合神经网络下的各种简单或者复杂网络.
4.3 相关度传播
Bach等人[36]提出的分层优化的相关度传播(layer-wise relevance propagation, LRP)从模型的输出开始,反向移动,直到到达模型输入为止,重新分配预测的分数或者相关度值,该方法常用于神经网络的预测结果解释.
1) 传播定义
假设1个DNN网络中具有2个神经元j和k,j和k所在的隐藏层是连续的,Rk表示较高层的神经元k的相关度得分,Rj←k表示神经元k到神经元j分享的相关度得分,则相关度的分配满足:
(12)
Fig. 3 The sample diagram of LRP propagation mechanism
图3 LRP传播机制示例图
具体传递流程如图3所示.w13表示正向传播神经元节点1到神经元节点3的权重,
表示神经元节点3到神经元节点1在1,2层之间传播的相关得分.神经元之间的传递只能是连续层,不可跨层传递,即不可能出现类似
的情况.从传递机制可以看出,
(13)
(14)
(15)
(16)
2) 传播规则
针对DNN网络,使用α β原则实现相邻层之间的相关度传递.
假设DNN网络的神经元激活函数为
(17)
其中,ak表示神经元k的激活值,j表示神经元k所在隐藏层的前一层的所有神经元之一,wjk表示权重,bk为偏置项.
则α β原则定义为
(18)
其中,+表示正例,-表示负例,α和β满足α-β=1,β≥0 约束.从而不同的α β组合解释预测结果的不同行为.
不同的任务、不同的网络以及不同的数据上,各种α β原则组合表现出不同的效果.Montavon等人[73]给出多种α β组合,譬如α2β1,α1β0等,以及α β组合选取的原则,并且在实验中将敏感度分析、简单泰勒分解以及相关度传播的方法进行比较,明显看出其预测结果解释的准确度由大到小的排序为:相关度传播的方法、简单泰勒展开式、敏感度分析.
5 模仿者模型解释技术
模仿者模型解释方法的基本思想是通过训练一个可解释的模仿者模型M来解释复杂的原模型S.相同的输入x1,x2,…,xN,模仿者模型M和复杂的原模型S具有相似的输出,即
5.1 线性分类器拟合
局部解释法的主要思想是在一系列输入实例中采样获得一组近邻实例,然后训练出一个线性模型来拟合神经网络模型在该近邻实例上的决策输出,最后使用训练好的线性模型来解释复杂的神经网络模型.该方法典型的代表是LIME[37],训练出的模型可用于本地局部解释预测结果,该方法适用于任何分类器的预测解释,作者还通过文本处理的随机森林模型和图像分类应用的神经网络数据集为例证明其方法的灵活性.
此类方法其优点在于模型设计训练过程简单,但由于近邻实例的抽样极具随机性,训练出的线性解释模型是不稳定的,极易造成对于相似的输入实例解释不一致的问题,以及对同一输入实例的多次解释不一致的问题,同时,近邻实例的选择也极大地影响解释结果的准确度.
Chu等人[38]研究了激活函数为分段线性函数的分段线性神经网络(piecewise linear neural network, PLNN)的解释问题,提出OpenBox的解释模型.
以激活函数为PReLU的深度神经网络为例,其激活单元可分为0和1 这2种情况,因为PReLU激活函数的线性性质,则可推导出无论神经元处于何种激活状态,其输入和输出始终保持线性关系.
解释模型OpenBox的处理流程如下所示:
给定一个输入实例x,将隐藏层中所有神经元的激活状态按逐层顺序排列成一个向量conf(x),该向量的每一个元素为0或1,也称为PLNN网中输入实例x的配置.
那么,对于单个输入实例的解释使用PLNN网络中输入实例x的配置conf(x).当conf(x)的元素排列值不变时,PLNN中所有隐藏层的计算等价于一个简单的线性运算Wx+b,即可构造F(x)=Softmax(Wx+b)的线性分类器.
为了解决解释一致性的问题,为PLNN的每个隐层神经元的输入z加上一组线性不等式约束r,因为输入x和每个隐层神经元输入z是线性关系,则等价于对每个输入实例x加上一组线性不等式约束.因而,所有满足r中线性不等式约束的实例x都具有相同的conf(x),这些实例共享着相同的线性分类器.
对于总体的决策行为解释依靠一个线性分类器组来解释,不同的隐层神经元激活状态对应不同的conf(x),因此具有多个不同的线性分类器,这个分类器组可作为PLNN的解释模型.
该方法时间复杂度为线性的,具有较好的解释性能,但是局限性太强,仅能解释PLNN类的网络结构,对于其他复杂的网络显得无能为力.
5.2 模型压缩
采取模型压缩的方式vwin 深度网络,训练出一个层数较少的浅层网络,这个新的浅层网络可以达到深度模型一样的效果,实验表明浅层神经网络能够学习与深度神经网络相同的功能[74-75].基于上述思想,研究出一系列的模仿者模型用于解释复杂的模型.
从原复杂的深度模型S到模仿者模型M,多数是通过模型压缩途径获取.模型压缩技术的研究动机主要是为了引入机器学习到移动终端,但是设备处理能力有限,因而设计各种算法减少隐藏层的节点数量和模型层数.Lei等人[76]通过减少隐藏层中节点的数量和输出层中多元音素(senone)方式压缩模型,最终在移动设备上安装 CD-DNN-HMM(context-dependent deep neural network hidden Markov model).Li等人[77]利用最小化模型S和模型M输出分布之间的KL(Kullback-Leibler)偏差进行层次压缩,使用对数模型和高斯模型之间的等价关系对多元音素进行压缩.多数学者利用压缩模型简单易解释特性用于复杂模型的可解释性工作.
5.3 知识蒸馏
知识蒸馏也称为模型蒸馏或模型模拟学习方法,属于模型压缩方法的一种.其基本思想是从预先训练好的大模型,蒸馏学习出性能较好的小模型.该方法有效地减小模型大小和计算资源.
Hinton等人[39]提供一种高效的知识蒸馏的方法,蒸馏主要通过软性的Softmax概率来实现.对于Softmax的输入z而言,其对于每个子类的输出概率为
(19)
其中,当T=1时,即为普通的Softmax变换,当T≻1时,即得到软化的Softmax的概率分布.通过式(19)生成软标签,然后结合硬标签同时用于新网络的学习.
最后用KL散度来约束模仿者模型M和原模型S的概率分布较为相似,即:
(20)
其中,pM,pS分别表示模仿者模型M和原模型S的概率分布,Ak表示一组模仿者模型,q表示原模型S和模仿者模型M所包含所有类别的最小子集的概率分布.
Frosst等人[40]在Hinton提出的知识蒸馏方法的基础之上,提出利用软决策树来模拟和解释复杂的原深度神经网络.
Balan等人[41]利用蒙特卡洛算法实现从教师模型S中蒸馏出学生模型M,并使M近似S的贝叶斯预测分布.该方法可简化问题的复杂性,但是大量的抽样将导致计算量较大.
Xu等人[78]设计了DarkSight解释方法,利用蒸馏知识压缩黑盒分类器成简单可解释的低维分类器,并借助可视化技术对提取的暗知识进行呈现.
5.4 其他方法
Che等人[42]利用梯度提升树(gradient boosting trees)来学习深度模型中的可解释特征,并构造出GBTmimic model 对模型进行解释.其基本处理流程如图4所示:
Fig. 4 The processing of GBTmimic model
图4 GBTmimic模型处理流程
给定输入特征x和目标y,输入特征x进入原模型S后,输出xnn和ynn.原模型S可能是多层降噪自动编码机(stacked denoising autoencoder, SDAE)或者LSTM,都具有几个隐藏层和一个预测层,xnn是选择从最高隐藏层的激活函数中提出的特征,ynn是从预测层获得软预测分数.接下来,目标y和xnn同时进入Classifier,Classifier选择Logistics回归,在相同的分类任务上,xnn进入分类器获得软预测分值yc.最后,选择yc或ynn以及特征x作为模仿者模型M的输入,通过最小均方差得到最终输出
模仿者模型即梯度提升回归树(gradient boosting regression trees).
Wu等人[79]提出树规则化的方法,使用二分类决策树模拟深度时间序列模型的预测,该模型比深度神经网络更容易解释,但是构造二分类决策树开销较大.
然而,由于模拟模型的模型复杂度降低,将无法保证具有超大维度的深神经网络可以被更简单的浅模型成功模拟,因此,模仿者模型不适合超深层的神经网路.同时,由于学习到一个更加简单的神经网络模型,解释模型的复杂度则达到某种程度的降低,而效果是以牺牲部分模型的准确度为代价而取得.
6 性能评估
对于可解释的评估因为任务的不同、解释模型的不同等诸多因素造成目前无法使用普适的方法.多数的方法都采用热力图[29,31-32]、错误率、准确率或者AUC[42]等方法进行评估.为了考虑到可用性,Zhou等人[9,34]引入人类评估作为基线.本文试图从可解释研究框架的角度给出如下的评估标准:
给定数据集D={X,Y},对于任意的x∈X,得到原预测模型S的值
其解释模型M的预测值是
6.1 解释的一致性
一致性是指对于2个相似的数据点x和x′,其预测解释M(x)和M(x′)也应该是接近相等的.解释的一致性可表示为:
(21)
6.2 解释的选择性
Bach等人 [36]和Samek等人[80]提出解释的选择性可由相关度最高的特征移除时,激活函数f(x)降低的速度来评价.该方法也称为像素翻转(pixel-flipping),不仅适合图像,同样适用于文本数据.
其执行过程循环的执行步骤为:
Step1. 计算f(x)当前的值;
Step2. 找到最高相关度特征Ri(x);
Step3. 从特征集合中移除该特征x←x-{xi}.
6.3 解释的准确性
准确性是指预测模型的准确度,可使用准确度值、F1指数等来衡量,构造一个可解释性模型,该模型自身的准确度依旧需要保持高精度,可解释模型的准确度为
6.4 解释的保真度
解释的保真度主要描述解释模型在何种程度上准确模仿原模型.针对黑盒子结果而言,利用其准确度、F1指数进行评价.保真度即是评估
此外,除上述几个与可解释性严格相关的指标外,机器学习的模型具有其他的重要因素,例如可靠性、鲁棒性、因果关系、可扩展性和通用性等,从而意味着模型能够独立于参数或者输入数据保持一定的性能(可靠性与鲁棒性),输入的变化影响模型行为的变化(因果关系),此外要求能够将模型扩展到更大的输入空间(可扩展性).最后在不同的应用场景中,人们会使用相同的模型和不同的数据,因此需要能够通用的解释模型,而非定制的受限的,这也将为性能评估方法提出巨大的挑战.
7 总结与展望
本文从机器学习模型的解释技术、预测结果的解释技术和模仿者模型技术3个方法总结了现有的关于机器学习的可解释技术,并总结其相关信息如表3所示.
7.1 可解释技术的内部问题
纵观当前机器学习的可解释技术,仍然面临着3个方面的挑战.
1) 准确性和解释性的均衡.伴随着模型的愈加复杂,提高最后预测的准确性,然后要求其预测的可解释性,必将意味着模型的复杂度受到一定程度的制约,预测模型需要牺牲部分准确度来满足可解释性,预测精度的损失是一个令人担忧的问题,因此,这一工作领域的中心重点是在保持可解释性的同时将精度损失最小化.
2) 解释一致性问题.输入一系列数据,经过预测模型,其解释机制给出一个解释.当下次再次输入相同或者类似的数据,解释机制是否能给出相同或者一致的解释是至关重要的,否则很难取得用户的信任,并将其真正地应用于实际项目中.
3) 评估问题.如何评估机器学习的解释质量的评价标准对于持续提升系统至关重要,因为只有这样才能更明确地有针对性地设计技术方案进行改进.机器学习的评估指标除了第6节中提到的之外,还有待于深入研究.
Doshi-Velez等人[17]提出如何考虑评估机器学习模型的人类可解释性方法.他们提出3种类型的方法:以应用为基础,以帮助人类完成实际任务的程度来判断解释效果;以人类为基础,以人类偏好或根据解释对模型进行推理的能力来判断解释;以功能为基础,以无人类输入的情况下,来判断代理模型的解释效果.对于这3种方法,皆假设结果数据的矩阵因子法有利于识别出解释性的常见潜在因素.
Mohseni等人[81]尝试将机器学习的可解释任务根据目标用户分为数据新手(data novices)、数据专家、机器学习专家3类,在每个类别下分别给出用户心智模型、用户-机器任务性能、用户解释的满意度、用户信任和信赖度和计算性能4个维度的评估.Mohseni认为机器学习的可解释性评估需要跨学科学者的共同努力,并充分考虑到人力和计算等要素.
7.2 安全和隐私性的问题
对模型研究得越透彻,意味着更大的风险,便于攻击者的攻击.无论是从数据上,还是从模型上,模型的可解释性和安全存在某种程度的相冲突.譬如模型训练阶段的数据投毒攻击[82]可造成模型的预测和解释失败;推理阶段根据解释技术中的激活值最大化和隐层神经元分析的方法,攻击者可以依据模型的解释机制而发起模型完整性攻击的模型推测攻击(model inversion attack)[83-85]和模型窃取攻击(model extraction attack)[86].
Table 3 The Summary of Interpretation and Understanding Methods
表3 可解释技术方法汇总表
目前,越来越多的人开始关注深度学习的隐私保护问题,该问题的目标是保护训练数据集和训练参数.主流的做法是Shokri等人[87]提出的分布式训练方法,将噪声注入到参数的梯度中进行训练,以保护神经网络中的隐私.在该方法中,注入噪声的大小和隐私预算与共享参数的数量都将成比例地累积.因此,它可能消耗不必要的大部分隐私预算,多方之间的训练时期的参数数量和共享参数的数量通常很大,可用性较差.
机器学习的可解释方法是否可以提高深度学习的差分隐私的可用性?Phan等人[88]设计自适应拉普拉斯扰动机制,尝试将“更多噪声”注入到模型输出“不太相关”的特征中.预测结果的解释技术中的分层优化的相关度传播LRP算法是不错的解决方案,实验表明在MNIST和CIFAR-10数据集上都取得不错的效果.Papernot等人[89]提出的PATE(private aggregation of teacher ensembles)模型借鉴了模仿者模型解释技术中的蒸馏知识技术,包含敏感信息的教师模型不能直接被访问,蒸馏出的学生模型可以被查询访问,从而有效地保护模型和数据的隐私.综上所述,将机器学习的可解释技术和深度学习的隐私保护技术相结合,同时有效地解决机器学习的隐私和可解释性2个问题成为一种可能.
7.3 研究视角的拓展
当前机器学习的可解释框架主要从模型和结果2个角度进行解释,具有一定的局限性.DeepMind 团队的 Rabinowitz 等人[90]试图以心智理论的视角来研究机器学习的可解释性问题,其研究目标是让观察者在有限的数据集的基础之上自动学习如何应对新的智能体建模,区别于以往的模仿算法,将学习如何像人理解人一样来预测另一个智能体的行为.其团队提出ToMnet模型改变以往尝试设计能表述内在状态的系统的做法,利用中转系统、人机接口,缩小原系统的行为空间大小,从而以人类更好理解的形式转述.同时,从训练数据分析的视角来解释机器学习的预测结果,也越来越被研究者所关注.譬如,Papernot等人[91] 提出的深度k近邻(deep k-nearest neighbors, DkNN) 混合分类器将k近邻算法与DNN各层学习数据的表示形式相结合,有效地解决数据投毒攻击和模型可解释性2个问题.
目前,机器学习技术已渗入到数据库、图像识别、自然语言处理等多个研究领域,而机器学习的可解释技术必将影响着这些领域产品由实验室实验阶段走向工业实际应用的进程.
在数据库领域,将机器学习融入到数据库管理的索引结构[92]、缓冲区管理[93]和查询优化[94-95]等多个环节中,出现一种机器学习化的数据库系统趋势.一方面可提高数据库的处理速度;另一方面,数据库系统可智能自动调配数据库系统模块.然而,机器学习的其可解释性较差的缺点日趋凸显,再者机器学习化的数据库中重要的组成模块事务处理要求事务处理过程具有可追溯性和可解释性[96].因此,将可解释性引入到机器学习化的数据库中,可有效地帮助数据库设计者和使用者更快、更好地设计和使用数据库.
在自然语言理解领域,如何更好地利用知识和常识成为一个重要的研究课题.很多情况下,只有具备一定常识的情况下,才便于对机器做出更深入的解释和理解.在人机交互系统中需要相关领域知识,从而能更加准确地完成用户查询理解、对话管理和回复生成等任务,受益于类似人机交互系统通常需要相关的领域知识这一特点,提高了基于知识和常识的可解释性NLP的可能性.
多数学者将领域知识引入到机器学习中,主要出于处理小数据场景或者提高性能的考虑,极少考虑到领域知识也可看作解释技术的重要组成部分.Rueden等人[97]首次提出知情机器学习(informed ML),对知识的类型、知识表示、知识转换以及知识与机器学习的方法的融合做出详细的分类说明.譬如知识类型可分为:自然科学、处理流程、世界知识和专家直觉.在该框架指导下,用户可以逐步选择合适的知识类型、知识表示和融合算法实现对机器学习模型的可解释和预测结果的可解释.
除此之外,知识图谱具有海量规模、结构良好、语义丰富等优点,使其成为机器学习理解语言的重要背景知识成为可能.肖仰华团队针对词袋[98]、概念[99]、实体集[100]和链接实体[101]做出一系列的解释工作,探索性地帮助机器理解和解释概念.然而,大规模的常识获取以及将符号化知识植入到数值化表示的神经网路都缺乏有效手段,这些问题将得到普遍的关注和研究.
再者不同的应用场景对于机器学习的可解释性的要求不同,如果仅是作为技术安全审查而用,专业的解释即可;如果当机器解释成为人机交互的一部分时,其解释必须通俗易懂.总之,机器学习的可解释性解决方案源于实用性的需求.
审核编辑:符乾江


























 工商网监
工商网监
评论