 德赢Vwin官网
App
德赢Vwin官网
App


普通文件类型
理解了文件系统的结构之后,我们来看一下文件的类型。
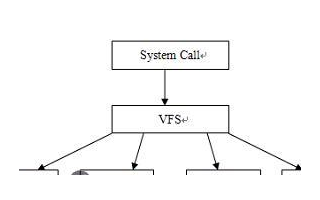
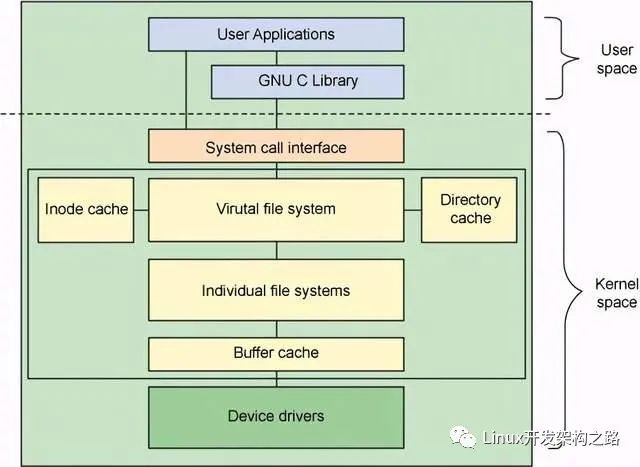
Linux以文件的形式对计算机中的数据和硬件资源进行管理,也就是彻底的一切皆文件,反映在Linux的文件类型上就是:**普通文件、目录文件(也就是文件夹)、设备文件、链接文件、管道文件、套接字文件(数据通信的接口)**等等。而这些种类繁多的文件被Linux使用目录树进行管理, 所谓的目录树就是以根目录(/)为主,向下呈现分支状的一种文件结构。
普通文件
从Linux的角度来说,类似mp4、pdf、html这样应用层面上的文件类型都属于普通文件,Linux用户可以根据访问权限对普通文件进行查看、更改和删除。我们知道,文件的属性,权限,大小,占用那些数据块是存在inode当中的。所以,这里注意一点,inode 当中并没有存放文件名,至于为什么,我们接下来看目录文件。
目录文件
本质上来说,目录页是文件,目录文件inode除了存放一些目录的权限,等属性之外,目录文件的内容则是该目录文件下文件名和其inode编号的一个映射关系。最简单的保存格式就是列表,就是一项一项地将目录下的文件信息(如文件名、文件 inode、文件类型等)列在表里。
文件目录块:
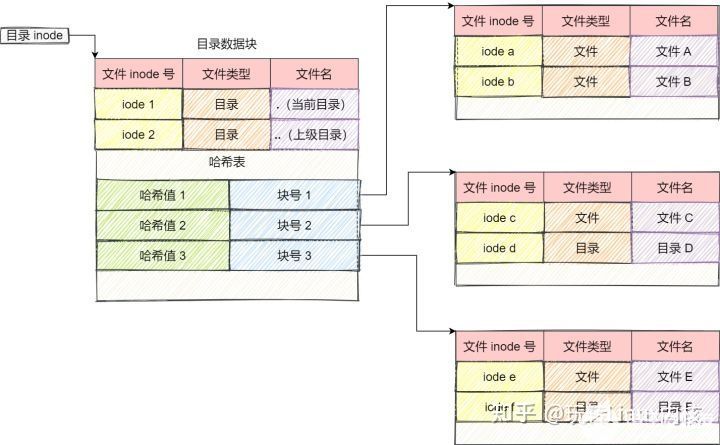
通常,第一项是「.」,表示当前目录,第二项是「…」,表示上一级目录,接下来就是一项一项的文件名和 inode。
如果一个目录有超级多的文件,我们要想在这个目录下找文件,按照列表一项一项地找,效率就不高了。
于是,保存目录的格式改成哈希表,对文件名进行哈希计算,把哈希值保存起来,如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应地块里面。
Linux 系统的 ext 文件系统就是采用了哈希表,来保存目录的内容,这种方法的优点是查找非常迅速,插入和删除也比较简单,不过需要一些预备措施来避免哈希冲突。
目录查询是通过在磁盘上反复搜索完成,需要不断地进行 I/O 操作,开销较大。所以,为了减少 I/O 操作,把当前使用的文件目录缓存在内存,以后要使用该文件时只要在内存中操作,从而降低了磁盘操作次数,提高了文件系统的访问速度。
文件inode
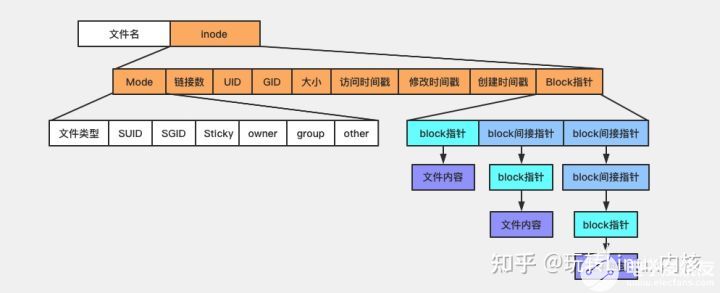
文件操作
文件链接
- 硬链接
一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。
这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
其实原理很简单,我们会在某个目录下创建一个文件名,这个文件名和硬链接的文件inode 相同,并且会在这个inode的记录中增加链接数量。
我们看到的就是两个链接到同一个inode 的文件其实是一个文件和inode的映射。
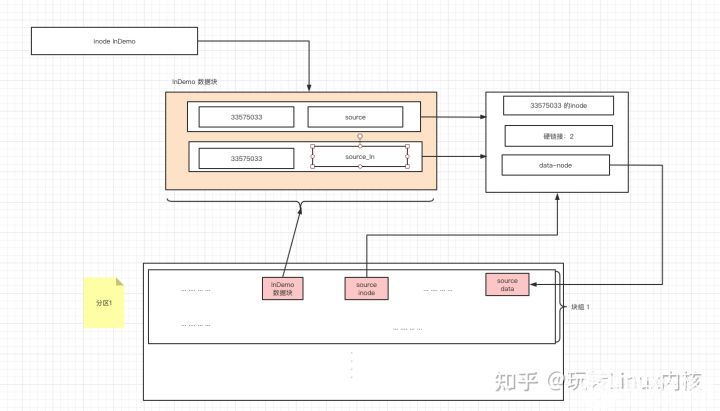
ln命令可以创建硬链接:
root@CentOS7 lnDemo]# ln source source_ln
[root@CentOS7 lnDemo]# ls -ali
总用量 8
33575032 drwxr-xr-x. 2 root root 37 9月 30 17:35 .
33574977 dr-xr-x---. 4 root root 161 9月 30 17:34 ..
33575033 -rw-r--r--. 2 root root 7 9月 30 17:31 source
33575033 -rw-r--r--. 2 root root 7 9月 30 17:31 source_ln
[root@CentOS7 lnDemo]# stat source
文件:"source"
大小:7 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:33575033 硬链接:2
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
环境:unconfined_u:object_r:admin_home_t:s0
最近访问:2020-09-30 17:34:54.975711266 +0800
最近更改:2020-09-30 17:31:49.124074625 +0800
最近改动:2020-09-30 17:35:05.665345071 +0800
创建时间:-
[root@CentOS7 lnDemo]# stat source_ln
文件:"source_ln"
大小:7 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:33575033 硬链接:2
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
环境:unconfined_u:object_r:admin_home_t:s0
最近访问:2020-09-30 17:34:54.975711266 +0800
最近更改:2020-09-30 17:31:49.124074625 +0800
最近改动:2020-09-30 17:35:05.665345071 +0800
创建时间:-
根据我们上面的研究,我们发现,硬链接有以下几个问题:
- 目录不允许硬链接
如果目录允许硬链接,那么我们完全可以将两个目录链接起来,那么操作系统则在找文件的时候,就会在两个目录跳来跳去,形成死循环。
[root@CentOS7 ~]# ln lnDemo/ ./lnDemo2
ln: "lnDemo/": 不允许将硬链接指向目录
[root@CentOS7 ~]#
- 不同分区不允许硬链接
由于硬链接是在本分区指向相同的inode,那么就意味着inode的命名空间需要一致,但是不同的分区,inode的编号将会重置,所有不能通过inode映射同一个文件。
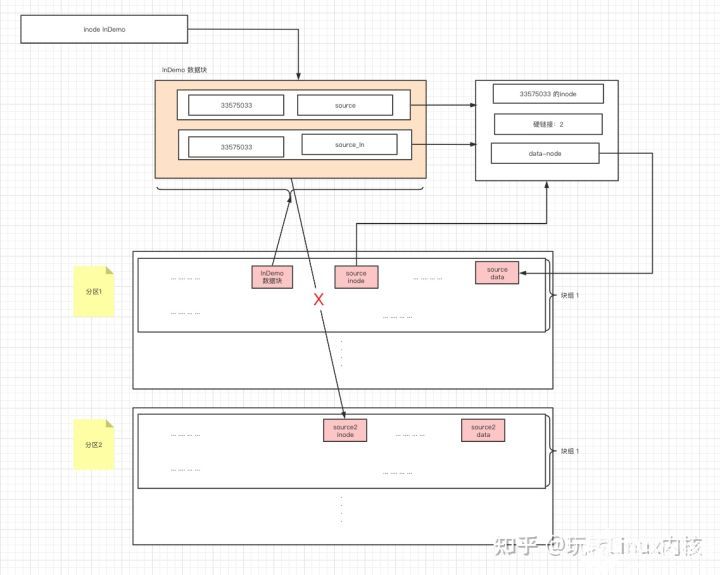
- 软连接
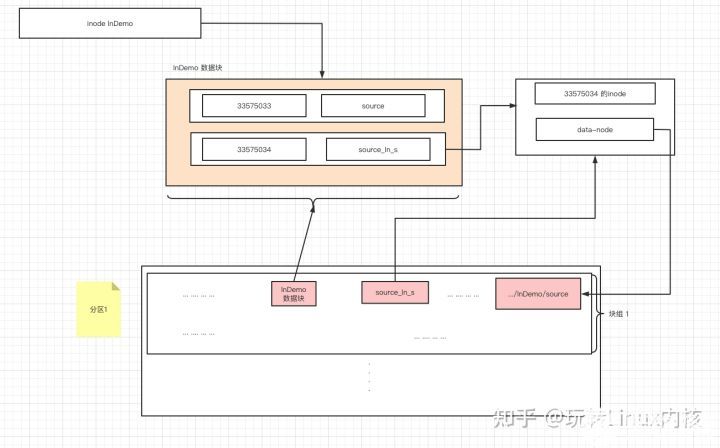
而软连接则不同,当创建软连接的时候,linux确实已经创建了一个inode 和起对应来的data block,只不过,在data block存放的是字符串,字符串的内容则是 链接文件的地址。
[root@CentOS7 lnDemo]# ln -s source source_sln
[root@CentOS7 lnDemo]# ls
source source_sln
[root@CentOS7 lnDemo]# ls -alt
总用量 4
drwxr-xr-x. 2 root root 38 9月 30 18:08 .
lrwxrwxrwx. 1 root root 6 9月 30 18:08 source_sln -> source
dr-xr-x---. 5 root root 172 9月 30 17:55 ..
-rw-r--r--. 1 root root 7 9月 30 17:31 source
[root@CentOS7 lnDemo]# ls -ailt
总用量 4
33575032 drwxr-xr-x. 2 root root 38 9月 30 18:08 .
33575034 lrwxrwxrwx. 1 root root 6 9月 30 18:08 source_sln -> source
33574977 dr-xr-x---. 5 root root 172 9月 30 17:55 ..
33575033 -rw-r--r--. 1 root root 7 9月 30 17:31 source
我们发现 source_sln 的文件类型为 l ,且inode和source 不同。大小很小,原因就是我们存放的是地址字符。
【文章福利】小编推荐自己的Linux内核技术交流群:【865977150】整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!

文件新建(复制)
- (1).读取GDT,找到各个(或部分)块组imap中未使用的inode号,并为待存储文件分配inode号;
- ((2).在inode table中完善该inode号所在行的记录;
- ((3).在目录的data block中添加一条该文件的相关记录;
- ((4).将数据填充到data block中。
注意,填充到data block中的时候会调用block分配器:一次分配4KB大小的block数量,当填充完4KB的data block后会继续调用block分配器分配4KB的block,然后循环直到填充完所有数据。也就是说,如果存储一个100M的文件需要调用block分配器100*1024/4=25600次。 另一方面,在block分配器分配block时,block分配器并不知道真正有多少block要分配,只是每次需要分配时就分配,在每存储一个data block前,就去bmap中标记一次该block已使用,它无法实现一次标记多个bmap位。这一点在ext4中进行了优化。
- (5)填充完之后,去inode table中更新该文件inode记录中指向data block的寻址指针。
文件删除
删除文件分为普通文件和目录文件,知道了这两种类型的文件的删除原理,就知道了其他类型特殊文件的删除方法。
对于删除普通文件:
- (1)找到文件的inode和data block(根据前一个小节中的方法寻找);
- (1.5) 如果inode的硬链接是数量不是1 ,则将硬链接的数量-1, 否则执行真正的删除。
- (2)将inode table中该inode记录中的data block指针删除;
- (3)在imap中将该文件的inode号标记为未使用;
- (4)在其所在目录的data block中将该文件名所在的记录行删除,删除了记录就丢失了指向inode的指针(实际上不是真的删除,直接删除的话会在目录data block的数据结构中产生空洞,所以实际的操作是将待删除文件的inode号设置为特殊的值0,这样下次新建文件时就可以重用该行记录);
- (5)将bmap中data block对应的block号标记为未使用。
对于删除目录文件:
- 找到目录和目录下所有文件、子目录、子文件的inode和data block;
- 在imap中将这些inode号标记为未使用;将bmap中将这些文件占用的 block号标记为未使用;
- 在该目录的父目录的data block中将该目录名所在的记录行删除。需要注意的是,删除父目录data block中的记录是最后一步,如果该步骤提前,将报目录非空的错误,因为在该目录中还有文件占用。
文件搜索
当执行"cat /var/log/messages"命令在系统内部进行了什么样的步骤呢?
- 找到根文件系统的块组描述符表所在的blocks,读取GDT(已在内存中)找到inode table的block号。
根文件系统是不需被引用的,因为在操作系统加载到内存当中的时候,跟文件系统已经存在,其中第inode编号也已经注册到了操作系统内核当中。根文件系统的GDT早已经在内存中了,在系统开机的时候会挂载根文件系统,挂载的时候就已经将所有的GDT放进内存中。
- 在inode table的block中定位到根"/“的inode,找出”/"指向的data block。
- 在"/"的datablock中记录了var目录名和var的inode号,找到该inode记录,inode记录中存储了指向var的block指针,所以也就找到了var目录文件的data block。
- 通过var目录的inode号,可以寻找到var目录的inode记录,但是在寻找的过程中,还需要知道该inode记录所在的块组以及所在的inode table,所以需要读取GDT,同样,GDT已经缓存到了内存中。
- 在var的data block中记录了log目录名和其inode号,通过该inode号定位到该inode所在的块组及所在的inode table,并根据该inode记录找到log的data block。
- 在log目录文件的data block中记录了messages文件名和对应的inode号,通过该inode号定位到该inode所在的块组及所在的inode table,并根据该inode记录找到messages的data block。
- 最后读取messages对应的datablock。
- 当然,在每次定位到inode记录后,都会先将inode记录加载到内存中,然后查看权限,如果权限允许,将根据block指针找到对应的data block。
文件移动
同文件系统下移动文件实际上是修改目标文件所在目录的data block,向其中添加一行指向inode table中待移动文件的inode指针,如果目标路径下有同名文件,则会提示是否覆盖,实际上是覆盖目录data block中冲突文件的记录,由于同名文件的inode记录指针被覆盖,所以无法再找到该文件的data block,也就是说该文件被标记为删除
所以在同文件系统内移动文件相当快,仅仅在所在目录data block中添加或覆盖了一条记录而已。也因此,移动文件时,文件的inode号是不会改变的。
对于不同文件系统内的移动,相当于先复制再删除的动作。
文件挂载
Linux 系统下,文件是虚拟文件系统,当我们ls / 的时候,linux 会吧所有磁盘,所有分区下的且挂载在根目录下的所有目录列出来。 挂载文件系统到某个目录下,例如"mount /dev/cdrom /mnt",挂载成功后/mnt目录中的文件全都暂时不可见了,且挂载后权限和所有者(如果指定允许普通用户挂载)等的都改变了,知道为什么吗?
下面就以通过"mount /dev/cdrom /mnt"为例,详细说明挂载过程中涉及的细节。
在将文件系统/dev/cdrom(此处暂且认为它是文件系统)挂载到挂载点/mnt之前,挂载点/mnt是根文件系统中的一个目录,"/"的data block中记录了/mnt的一些信息,其中包括inode号inode_n,而在inode table中,/mnt对应的inode记录中又存储了block指针block_n,此时这两个指针还是普通的指针。
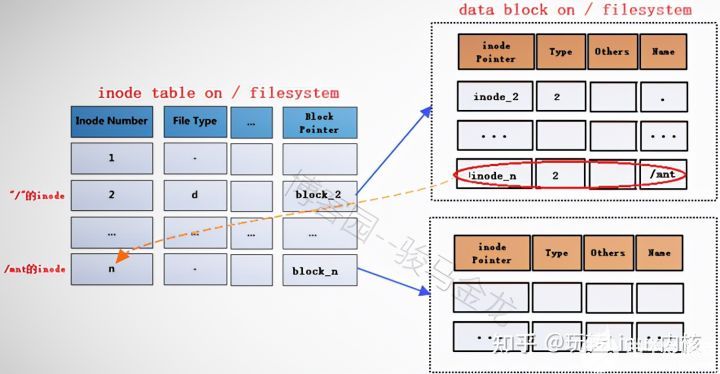
当文件系统/dev/cdrom挂载到/mnt上后,/mnt此时就已经成为另一个文件系统的入口了,因此它需要连接两边文件系统的inode和data block。
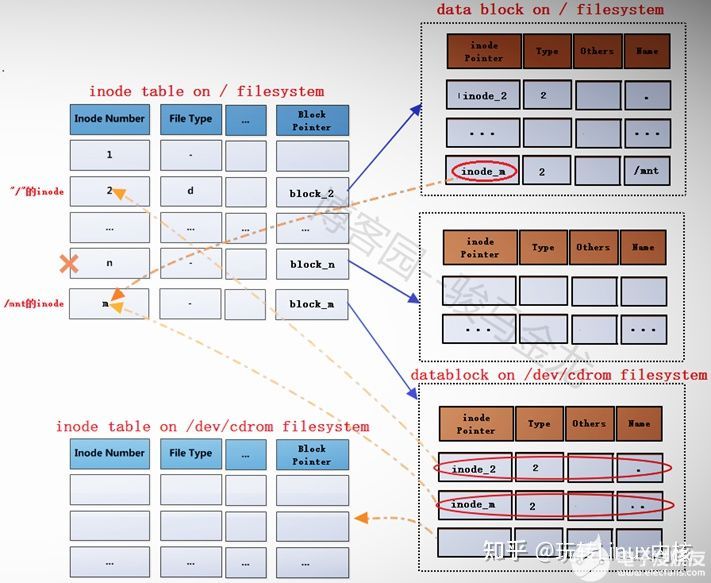
- 在根文件系统的inode table中,为/mnt重新分配一个inode记录m,该记录的block指针block_m指向文件系统/dev/cdrom中的data block。
- /mnt分配了新的inode记录m,那么在"/"目录的data block中,也需要修改其inode指针为inode_m以指向m记录。
- 同时,原来inode table中的inode记录n就被标记为暂时不可用。
block_m指向的是文件系统/dev/cdrom的data block,所以严格说起来,除了/mnt的元数据信息即inode记录m还在根文件系统上,/mnt的data block已经是在/dev/cdrom中的了。这就是挂载新文件系统后实现的跨文件系统,它将挂载点的元数据信息和数据信息分别存储在不同的文件系统上。
挂载完成后,将在/proc/self/{mounts,mountstats,mountinfo}这三个文件中写入挂载记录和相关的挂载信息,并会将/proc/self/mounts中的信息同步到/etc/mtab文件中,当然,如果挂载时加了-n参数,将不会同步到/etc/mtab。
而卸载文件系统,其实质是移除临时新建的inode记录(当然,在移除前会检查是否正在使用)及其指针,并将指针指回原来的inode记录,这样inode记录中的block指针也就同时生效而找回对应的data block了。由于卸载只是移除inode记录,所以使用挂载点和文件系统都可以实现卸载,因为它们是联系在一起的。
下面是分析或结论。
(1).挂载点挂载时的inode记录是新分配的。
挂载前挂载点/mnt的inode号
[root@server2 tmp]# ll -id /mnt
100663447 drwxr-xr-x. 2 root root 6 Aug 12 2015 /mnt
[root@server2 tmp]# mount /dev/cdrom /mnt
# 挂载后挂载点的inode号
[root@server2 tmp]# ll -id /mnt
1856 dr-xr-xr-x 8 root root 2048 Dec 10 2015 mnt
由此可以验证,inode号确实是重新分配的。
(2).挂载后,挂载点的内容将暂时不可见、不可用,卸载后文件又再次可见、可用。
在挂载前,向挂载点中创建几个文件
[root@server2 tmp]# touch /mnt/a.txt
[root@server2 tmp]# mkdir /mnt/abcdir
# 挂载
[root@server2 tmp]# mount /dev/cdrom /mnt
挂载后,挂载点中将找不到刚创建的文件
[root@server2 tmp]# ll /mnt
total 636
-r--r--r-- 1 root root 14 Dec 10 2015 CentOS_BuildTag
dr-xr-xr-x 3 root root 2048 Dec 10 2015 EFI
-r--r--r-- 1 root root 215 Dec 10 2015 EULA
-r--r--r-- 1 root root 18009 Dec 10 2015 GPL
dr-xr-xr-x 3 root root 2048 Dec 10 2015 images
dr-xr-xr-x 2 root root 2048 Dec 10 2015 isolinux
dr-xr-xr-x 2 root root 2048 Dec 10 2015 LiveOS
dr-xr-xr-x 2 root root 612352 Dec 10 2015 Packages
dr-xr-xr-x 2 root root 4096 Dec 10 2015 repodata
-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-7
-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-Testing-7
-r--r--r-- 1 root root 2883 Dec 10 2015 TRANS.TBL
卸载后,挂载点/mnt中的文件将再次可见
[root@server2 tmp]# umount /mnt
[root@server2 tmp]# ll /mnt
total 0
drwxr-xr-x 2 root root 6 Jun 9 08:18 abcdir
-rw-r--r-- 1 root root 0 Jun 9 08:18 a.txt
之所以会这样,是因为挂载文件系统后,挂载点原来的inode记录暂时被标记为不可用,关键是没有指向该inode记录的inode指针了。在卸载文件系统后,又重新启用挂载点原来的inode记录,"/"目录下的mnt的inode指针又重新指向该inode记录。
(3).挂载后,挂载点的元数据和data block是分别存放在不同文件系统上的。
(4).挂载点即使在挂载后,也还是属于源文件系统的文件。
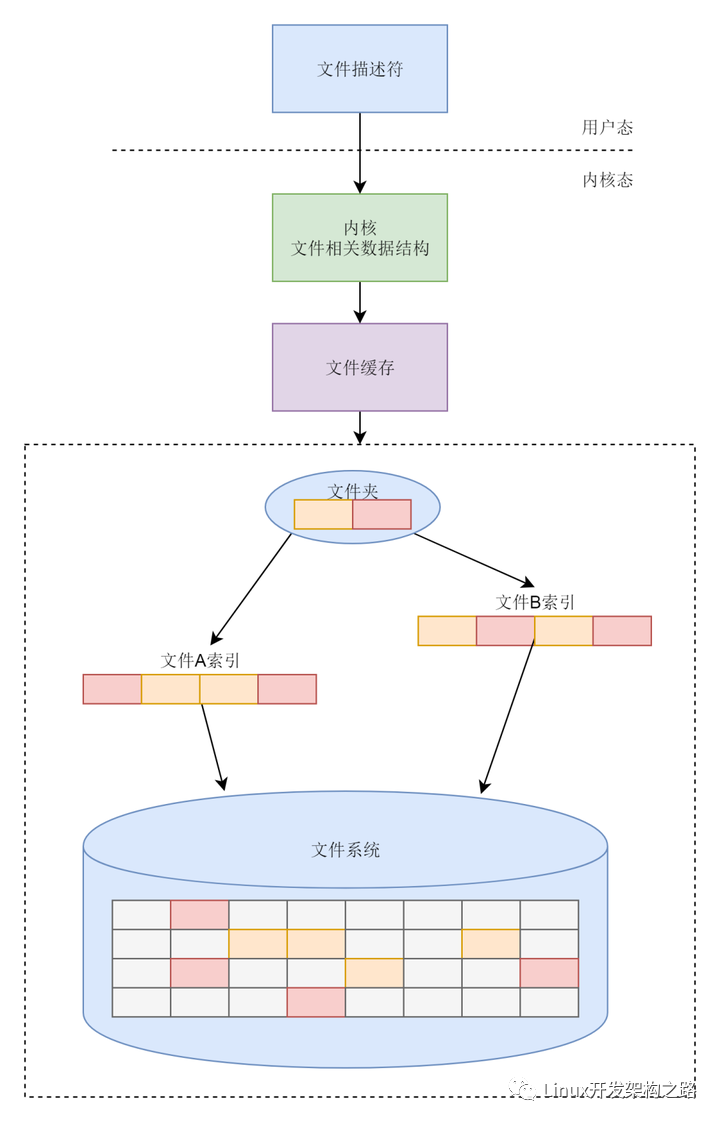
文件描述符
先看一段最文件描述符的官方说明
维基百科:文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。
- 作用
Linux 系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来指向被打开的文件,所有执行I/O操作的系统调用都会通过文件描述符。
- 概念定义文件描述符 是 用来访问资源(文件,输入输出设备等)的一种抽象指示符。文件描述符 是POSIX(Portable Operating System Interface)规范的组成部分文件描述符 通常是非负整数,C 语言中使用int类型。
- FD 具体可以指向什么文件/目录 files/directories输入输出源 input/output管道 pipes套接字 sockets其他 Unix 文件类型 other Unix files
- 默认的fds每一个 Unix 进程中,通常会有三个预制的 FD。它们分别是标准输入 Standard input 标准输入 用于程序接受数据标准输出 Standard output 标准输出 用于程序输出数据标准错误(输出) Standard error 标准错误 用于程序输出错误或者诊断信息
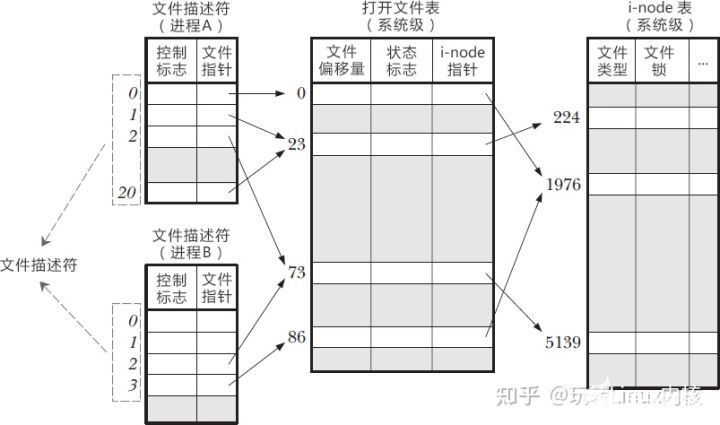
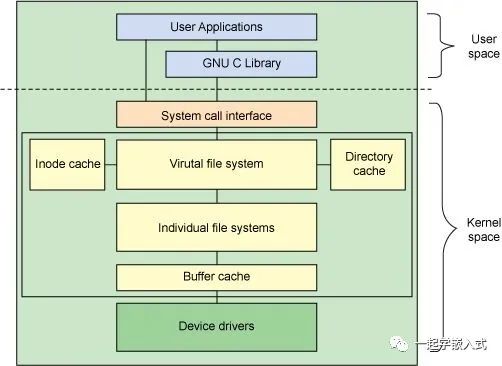
- 文件描述符的意义 一个 Linux 进程启动后,会在内核空间中创建一个 PCB 控制块,PCB 内部有一个文件描述符表(File descriptor table),记录着当前进程所有可用的文件描述符,也即当前进程所有打开的文件。
除了文件描述符表,系统还需要维护另外两张表:
打开文件表(Open file table)
i-node 表(i-node table)
文件描述符表每个进程都有一个,打开文件表和 i-node 表整个系统只有一个,它们三者之间的关系如下图所示。
文件描述符的意义
首先,为什么不把文件位置干脆存放在索引节点中,而要多此一举,设一个新的数据结构呢?我们知道,Linux中的文件是能够共享的,假如把文件位置存放在索引节点中,则如果有两个或更多个进程同时打开同一个文件时,它们将去访问同一个索引节点,于是一个进程的LSEEK操作将影响到另一个进程的读操作,这显然是不允许也是不可想象的。
另一个想法是既然进程是通过文件描述符访问文件的,为什么不用一个与文件描述符数组相平行的数组来保存每个打开文件的文件位置?这个想法也是不能实现的,原因就在于在生成一个新进程时,子进程要共享父进程的所有信息,包括文件描述符数组。
我们知道,一个文件不仅可以被不同的进程分别打开,而且也可以被同一个进程先后多次打开。一个进程如果先后多次打开同一个文件,则每一次打开都要分配一个新的文件描述符,并且指向一个新的file结构,尽管它们都指向同一个索引节点,但是,如果一个子进程不和父进程共享同一个file结构,而是也如上面一样,分配一个新的file结构,会出现什么情况了?让我们来看一个例子:
假设有一个输出重定位到某文件A的shell script(shell脚本),我们知道,shell是作为一个进程运行的,当它生成第一个子进程时,将以0作为A的文件位置开始输出,假设输出了2K的数据,则现在文件位置为2K。然后,shell继续读取脚本,生成另一个子进程,它要共享shell的file结构,也就是共享文件位置,所以第二个进程的文件位置是2K,将接着第一个进程输出内容的后面输出。如果shell不和子进程共享文件位置,则第二个进程就有可能重写第一个进程的输出了,这显然不是希望得到的结果。
查看文件描述符
lsof(list open files)是一个查看当前系统文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,该文件描述符提供了大量关于这个应用程序本身的信息。
lsof打开的文件可以是:
- 普通文件
- 目录
- 网络文件系统的文件
- 字符或设备文件
- (函数)共享库
- 管道,命名管道
- 符号链接
- 网络文件(例如:NFS file、网络socket,unix域名socket)
- 还有其它类型的文件,等等
我们用java 新写一段代码:
public static void main(String[] args) throws Exception {
String s ="/tmp/file.test";
FileOutputStream fileOutputStream = new FileOutputStream(new File(s));
System.in.read();
}
运行上述代码,并用jps找到其对应的pid
利用lsof -i 命令来查看:
...
java 36562 lizhipeng mem REG 253,0 142144 50547 /usr/lib64/libpthread-2.17.so
java 36562 lizhipeng mem REG 253,0 163312 42066 /usr/lib64/ld-2.17.so
java 36562 lizhipeng mem REG 253,0 32768 51151094 /tmp/hsperfdata_lizhipeng/36562
java 36562 lizhipeng 0u CHR 136,4 0t0 7 /dev/pts/4
java 36562 lizhipeng 1u CHR 136,4 0t0 7 /dev/pts/4
java 36562 lizhipeng 2u CHR 136,4 0t0 7 /dev/pts/4
java 36562 lizhipeng 3r REG 253,0 73861866 33613070 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64/jre/lib/rt.jar
java 36562 lizhipeng 4r REG 253,0 1027597 33613060 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64/jre/lib/jfr.jar
java 36562 lizhipeng 5w REG 253,0 0 33671497 /tmp/file.test
PCB 进程控制块
为了描述控制进程的运行,系统中存放进程的管理和控制信息的数据结构称为进程控制块(PCB Process Control Block),它是进程实体的一部分,是操作系统中最重要的记录性数据结构。它是进程管理和控制的最重要的数据结构,每一个进程均有一个PCB,在创建进程时,建立PCB,伴随进程运行的全过程,直到进程撤消而撤消。 在linux中 PCB 用task_struct 数据结构来表示
PCB
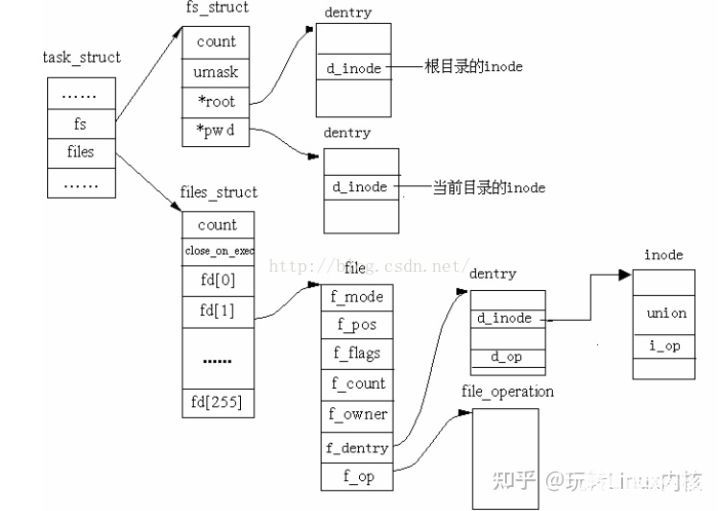
fs_struct
1、与进程相关的文件
首先,文件必须由进程打开,每个进程都有它自己当前的工作目录和它自己的根目录。task_struct的fs字段指向进程的fs_struct结构,files字段指向进程的files_struct结构。
struct fs_struct {
atomic_t count;
rwlock_t lock;
int umask;
struct dentry * root, * pwd, * altroot;
struct vfsmount * rootmnt, * pwdmnt, * altrootmnt;
};
- count:共享这个表的进程个数
- lock:用于表中字段的读/写自旋锁
- umask:当打开文件设置文件权限时所使用的位掩码
- root:根目录的目录项
- pwd:当前工作目录的目录项
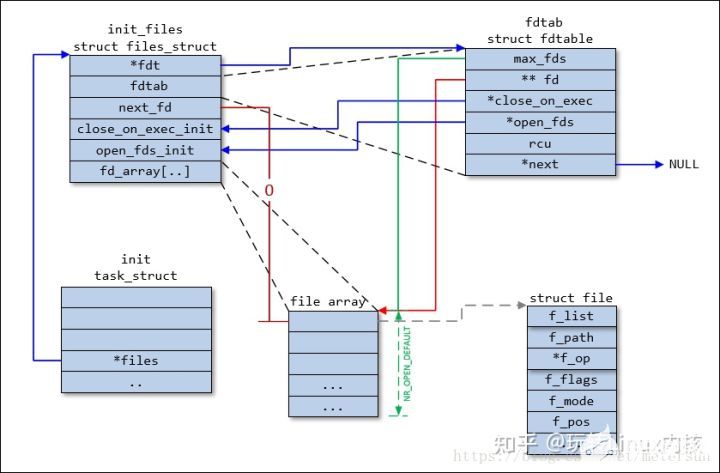
files_struct
每个进程用一个 files_struct 结构来记录文件描述符的使用情况, 这个 files_struct结构称为用户打开文件表, 它是进程的私有数据。 files_struct 结构在include/linux/sched.h 中定义如下:
struct files_struct {
atomic_t count;
struct fdtable *fdt;
struct fdtable fdtab;
int next_fd;
struct embedded_fd_set close_on_exec_init;
struct embedded_fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
};
ulimit
ulimit命令可以查看当前shell下的文件描述符的数量。
ulimit 用于限制 shell 启动进程所占用的资源,支持以下各种类型的限制:所创建的内核文件的大小、进程数据块的大小、Shell 进程创建文件的大小、内存锁住的大小、常驻内存集的大小、打开文件描述符的数量、分配堆栈的最大大小、CPU 时间、单个用户的最大线程数、Shell 进程所能使用的最大虚拟内存。同时,它支持硬资源和软资源的限制。
作为临时限制,ulimit 可以作用于通过使用其命令登录的 shell 会话,在会话终止时便结束限制,并不影响于其他 shell 会话。而对于长期的固定限制,ulimit 命令语句又可以被添加到由登录 shell 读取的文件中,作用于特定的 shell 用户。
语法:
ulimit (选项)
选项:
-a:显示目前资源限制的设定;
-c :设定core文件的最大值,单位为区块;
-d <数据节区大小>:程序数据节区的最大值,单位为KB;
-f <文件大小>:shell所能建立的最大文件,单位为区块;
-H:设定资源的硬性限制,也就是管理员所设下的限制;
-m <内存大小>:指定可使用内存的上限,单位为KB;
-n <文件数目>:指定同一时间最多可开启的文件数;
-p <缓冲区大小>:指定管道缓冲区的大小,单位512字节;
-s <堆叠大小>:指定堆叠的上限,单位为KB;
-S:设定资源的弹性限制;
-t :指定CPU使用时间的上限,单位为秒;
-u <程序数目>:用户最多可开启的程序数目;
-v <虚拟内存大小>:指定可使用的虚拟内存上限,单位为KB。
实例:
来看一下具体的用法:
[root@Centos ~]# ulimit -a
core file size (blocks, -c) 0 #core文件的最大值为100 blocks。
data seg size (kbytes, -d) unlimited #进程的数据段可以任意大。
scheduling priority (-e) 0
file size (blocks, -f) unlimited #文件可以任意大。
pending signals (-i) 3794 #最多有98304个待处理的信号。
max locked memory (kbytes, -l) 64 #一个任务锁住的物理内存的最大值为32KB。
max memory size (kbytes, -m) unlimited #一个任务的常驻物理内存的最大值。
open files (-n) 1024 #一个任务最多可以同时打开1024的文件。
pipe size (512 bytes, -p) 8 #管道的最大空间为4096字节。
POSIX message queues (bytes, -q) 819200 #POSIX的消息队列的最大值为819200字节。
real-time priority (-r) 0
stack size (kbytes, -s) 10240 #进程的栈的最大值为10240字节。
cpu time (seconds, -t) unlimited #进程使用的CPU时间。
max user processes (-u) 1024 #当前用户同时打开的进程(包括线程)的最大个数为98304。
virtual memory (kbytes, -v) unlimited #没有限制进程的最大地址空间。
file locks (-x) unlimited #所能锁住的文件的最大个数没有限制。
Linux默认的文件打开数是1024,现在设置打开数为2048.
[root@Centos ~]# ulimit -n --查看打开数为1024
1024
[root@Centos ~]# ulimit -n 2048 --设置打开数为2048
[root@Centos ~]# ulimit -n --再次查看
2048
特殊文件类型
- Linux设备驱动程序工作原理
系统调用是操作系统内核和应用程序之间的接口,设备驱动程序是操作系统内核和机器硬件之间的接口。设备驱动程序为应用程序屏蔽了硬件的细节,这样在应用程序看来,硬件设备只是一个设备文件, 应用程序可以象操作普通文件一样对硬件设备进行操作。设备驱动程序是内核的一部分,运行在核心态,它完成以下的功能:
1.对设备初始化和释放.
2.把数据从内核传送到硬件和从硬件读取数据.
3.读取应用程序传送给设备文件的数据和回送应用程序请求的数据.
4.检测和处理设备出现的错误.
在Linux操作系统下有三类主要的设备文件类型:字符设备、块设备和网络接口。 字符设备和块设备的主要区别是:在对字符设备发出读/写请求时,实际的硬件I/O一般就紧接着发生了块设备则不然,它利用一块系统内存作缓冲区,当用户进程对设备请求能满足用户的要求,就返回请求的数据,如果不能,就调用请求函数来进行实际的I/O操作。这也就是进程管理的Page cache的作用,块设备是主要针对磁盘等慢速设备设计的,以免耗费过多的CPU时间来等待。
换句话说, 当发生块设备的IO的时候, 操作系统实际是先写到Page cache上,而 pageCashe 会有一个映射规则,映射到某个块设备的具体地址,在发生操作以系统的IO的时候,比如说 写某个文件 当我们点击保存的时候,实际是写到了Page cache上, 此时操作系统将当前pageCash标记为脏页,之后如何将脏页刷新会磁盘就要看各个操作系统策略了。
字符设备、块设备
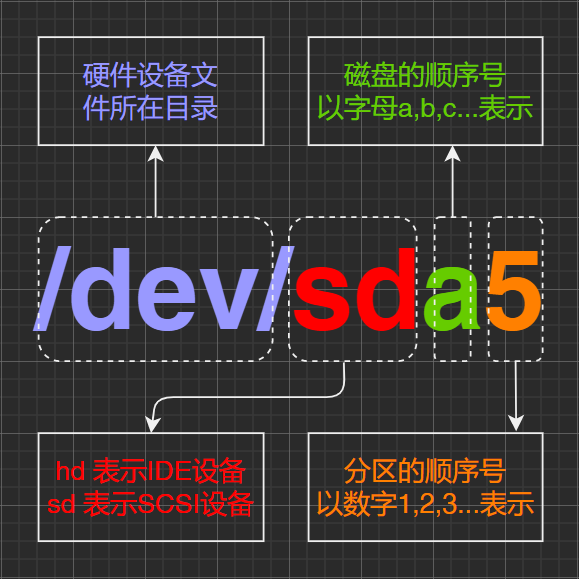
每个设备文件都有其文件属性(c/b),表示是字符设备还是块设备, 另外每个文件都有两个设备号,第一个是主设备号,标识驱动程序,第二个是从设备号,标识使用同一个设备驱动程序的不同的硬件设备,比如有两个软盘,就可以用 从设备号来区分他们。设备文件的的主设备号必须与设备驱动程序在登记时申请的主设备号一致,否则用户进程将无法访问到驱动程序。
我可以通过 ls 来看一下
命令:ls -alti
输出详解:
# ===================
10605 (inode 编号)
brw-rw----. b 块设备, c 字符设备
1
root (所属用户)
cdrom (用户组)
11,(主设备号)
0(次设备号)
10月 12 17:41
sr0 设备名称
# ===================
ex:
10445 brw-rw----. 1 root disk 8, 1 10月 12 17:41 sda1
10446 brw-rw----. 1 root disk 8, 2 10月 12 17:41 sda2
10444 brw-rw----. 1 root disk 8, 0 10月 12 17:41 sda
10449 brw-rw----. 1 root disk 8, 16 10月 12 17:41 sdb
8535 crw-------. 1 root root 247, 1 10月 12 17:41 usbmon1
10104 crw-------. 1 root root 246, 0 10月 12 17:41 hidraw0
8550 crw-------. 1 root root 247, 2 10月 12 17:41 usbmon2
- 文件操作的关键结构
由于用户进程是通过设备文件同硬件打交道,对设备文件的操作方式不外乎就是一些系统调用,如 open,read,write,close…, 注意,不是fopen, fread,但是如何把系统调用和驱动程序关联起来呢?这需要了解一个非常关键的数据结构 file_operations:
struct file_operations {
int (*seek) (struct inode * ,struct file *, off_t ,int);
int (*read) (struct inode * ,struct file *, char ,int);
int (*write) (struct inode * ,struct file *, off_t ,int);
int (*readdir) (struct inode * ,struct file *, struct dirent * ,int);
int (*select) (struct inode * ,struct file *, int ,select_table *);
int (*ioctl) (struct inode * ,struct file *, unsined int ,unsigned long);
int (*mmap) (struct inode * ,struct file *, struct vm_area_struct *);
int (*open) (struct inode * ,struct file *);
int (*release) (struct inode * ,struct file *);
int (*fsync) (struct inode * ,struct file *);
int (*fasync) (struct inode * ,struct file *,int);
int (*check_media_change) (struct inode * ,struct file *);
int (*revalidate) (dev_t dev);
}
这个结构的每一个成员的名字都对应着一个系统调用。用户进程利用系统调用在对设备文件进行诸如read/write操作时,系统调用通过设备文件的主设备号找到相应的设备驱动程序,然后读取这个数据结构相应的函数指针,接着把控制权交给该函数。这是linux的设备驱动程序工作的基本原理 这里不再详细阐述。
链接文件
软连接文件,详情请看上文 文件链接
管道文件
- 什么是管道?
管道,英文为pipe。这是一个我们在学习Linux命令行的时候就会引入的一个很重要的概念。它的发明人是道格拉斯.麦克罗伊,这位也是UNIX上早期shell的发明人。他在发明了shell之后,发现系统操作执行命令的时候,经常有需求要将一个程序的输出交给另一个程序进行处理,这种操作可以使用输入输出重定向加文件搞定,比如:
[lizhipeng@CentOS7 ~]$ ls /etc/ > etc.txt
[lizhipeng@CentOS7 ~]$ wc -l etc.txt
但是这样未免显得太麻烦了。所以,管道的概念应运而生。目前在任何一个shell中,都可以使用“|”连接两个命令,shell会将前后两个进程的输入输出用一个管道相连,以便达到进程间通信的目的:
[lizhipeng@CentOS7 ~]$ ls -l /etc/ | wc -l
对比以上两种方法,我们也可以理解为,管道本质上就是一个文件,前面的进程以写方式打开文件,后面的进程以读方式打开。这样前面写完后面读,于是就实现了通信。实际上管道的设计也是遵循UNIX的“一切皆文件”设计原则的,它本质上就是一个文件。Linux系统直接把管道实现成了一种文件系统,借助VFS给应用程序提供操作接口。
虽然实现形态上是文件,但是管道本身并不占用磁盘或者其他外部存储的空间。在Linux的实现上,它占用的是内存空间。所以,Linux上的管道就是一个操作方式为文件的内存缓冲区。
Linux上的管道分两种类型:
- 匿名管道
- 命名管道
这两种管道也叫做有名或无名管道。匿名管道最常见的形态就是我们在shell操作中最常用的”|”。它的特点是只能在父子进程中使用,父进程在产生子进程前必须打开一个管道文件,然后fork产生子进程,这样子进程通过拷贝父进程的进程地址空间获得同一个管道文件的描述符,以达到使用同一个管道通信的目的。此时除了父子进程外,没人知道这个管道文件的描述符,所以通过这个管道中的信息无法传递给其他进程。这保证了传输数据的安全性,当然也降低了管道了通用性,于是系统还提供了命名管道。
我们可以使用mkfifo或mknod命令来创建一个命名管道,这跟创建一个文件没有什么区别:
[lizhipeng@CentOS7 ~]$ mkfifo pip
[lizhipeng@CentOS7 ~]$ ls
prw-rw-r--. 1 lizhipeng lizhipeng 0 11月 17 13:24 pip
可以看到创建出来的文件类型比较特殊,是p类型。表示这是一个管道文件。有了这个管道文件,系统中就有了对一个管道的全局名称,于是任何两个不相关的进程都可以通过这个管道文件进行通信了。比如我们现在让一个进程写这个管道文件:
[lizhipeng@CentOS7 ~]$ echo xxxxxxxxxxxxxx > pip
此时这个写操作会阻塞,因为管道另一端没有人读。这是内核对管道文件定义的默认行为。此时如果有进程读这个管道,那么这个写操作的阻塞才会解除:
[lizhipeng@CentOS7 ~]$ cat pip
xxxxxxxxxxxxxx
大家可以观察到,当我们cat完这个文件之后,另一端的echo命令也返回了。这就是命名管道
接下来我们来看一下匿名管道,我们需要用到 shell 的代码块 命令如下
[lizhipeng@CentOS7 ~]$ { echo $BASHPID; read x ; } | { cat ; echo $BASHPID; read y; }
37057
{} 花括号的代码会先执行,遇到管道后,会开启另外一个进程,两个进程实现通讯。此时父进程输出了父进程的pid
且阻塞在了read x 这个代码块中,此时我们可以通过结果拿到父进程的 pid 37057
我们通过pstree来验证一下我们的关系
[lizhipeng@CentOS7 ~]$ pstree -p
...
─sshd(36387)───bash(36388)─┬─bash(37057+
│ │ └─bash(37058+
│ └─sshd(36713)───sshd(36717)───bash(36718)───pstree(370+
...
我们看到了 37057 进程生出了 37058的子进程。我们来看一下管道的文件描述符:
[lizhipeng@CentOS7 fd]$ ls -alt /proc/37057/fd
总用量 0
lrwx------. 1 lizhipeng lizhipeng 64 11月 17 13:33 0 -> /dev/pts/4
l-wx------. 1 lizhipeng lizhipeng 64 11月 17 13:33 1 -> pipe:[253711]
lrwx------. 1 lizhipeng lizhipeng 64 11月 17 13:33 2 -> /dev/pts/4
lrwx------. 1 lizhipeng lizhipeng 64 11月 17 13:33 255 -> /dev/pts/4
dr-x------. 2 lizhipeng lizhipeng 0 11月 17 13:33 .
dr-xr-xr-x. 9 lizhipeng lizhipeng 0 11月 17 13:30 ..
[lizhipeng@CentOS7 fd]$ ls -alt /proc/37058/fd
总用量 0
lr-x------. 1 lizhipeng lizhipeng 64 11月 17 13:34 0 -> pipe:[253711]
lrwx------. 1 lizhipeng lizhipeng 64 11月 17 13:34 1 -> /dev/pts/4
lrwx------. 1 lizhipeng lizhipeng 64 11月 17 13:34 2 -> /dev/pts/4
lrwx------. 1 lizhipeng lizhipeng 64 11月 17 13:34 255 -> /dev/pts/4
dr-x------. 2 lizhipeng lizhipeng 0 11月 17 13:34 .
dr-xr-xr-x. 9 lizhipeng lizhipeng 0 11月 17 13:30 ..
由此我们可以看到,37057 通过重定向 1 号文件描述符来讲管道 重定向到了 37058 的0号描述符。
这就是匿名管道。
















 工商网监
工商网监
评论