 德赢Vwin官网
App
德赢Vwin官网
App


有想法把最近看到关于FPGA相关的(名词)概念做个总结,解释内容主要来自其他博客,我只加部分个人理解,做个拾荒者,捡其重点,作为摘录,文末罗列参考资料。
1、异步复位、同步释放
1.1.解释
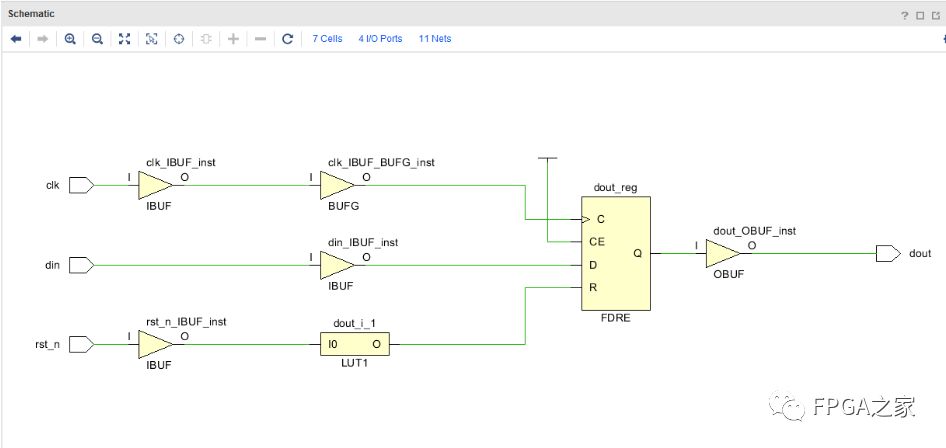
同步复位:需要时钟参与,一般只有时钟上升沿到来复位信号才有效;
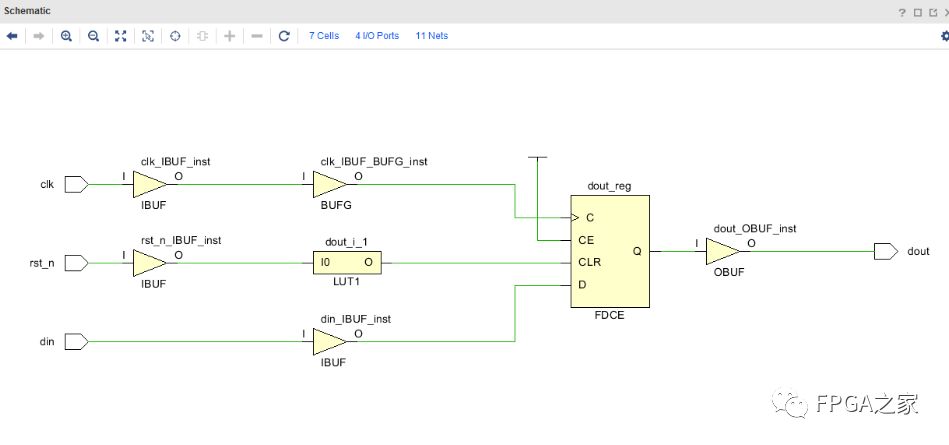
异步复位:不需要时钟参与,只要复位信号一有效就立即进行复位操作;
1.2.优缺点
同步复位:防止复位信号的毛刺引起误复位操作,利于静态时序分析;较异步复位更消耗逻辑资源,复位信号脉冲宽度必须大于时钟周期,同步复位依赖于时钟;
异步复位:无需额外的逻辑资源,复位信号不依赖于时钟;容易受毛刺影响,如果复位释放恰好在时钟有效沿附近容易使寄存器输出亚稳态;
1.3.CODE
同步复位:

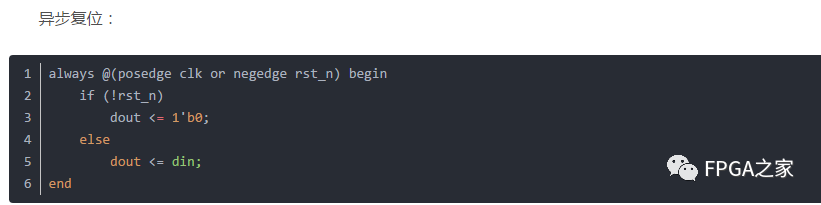
异步复位,同步释放(Synchronized Asynchronous Reset):目的为了防止复位信号在撤除时产生亚稳态。
异步复位:将复位信号rst_n接入到DFF的清零端,不存在复位信号必须要检测到大于一个时钟周期才能被检测到的局限,只要rst_n则将rst_s1,rst_s2赋0。
同步释放:当rst_n重新拉回高电平,进行removal,时钟参与。
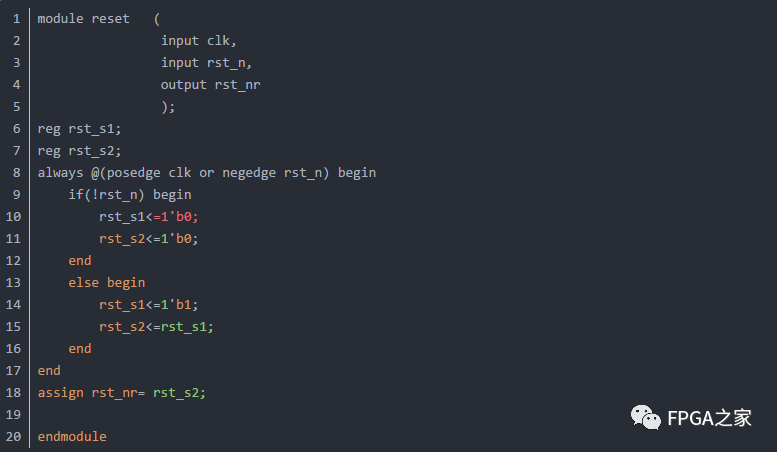
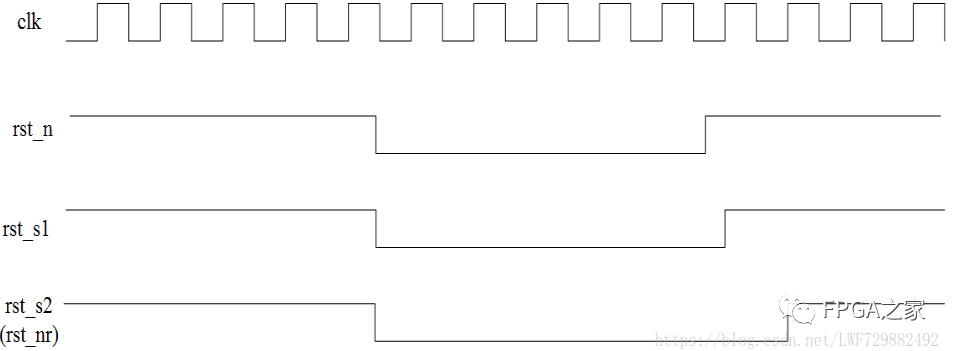
或:异步复位、同步释放(考虑上电延迟)
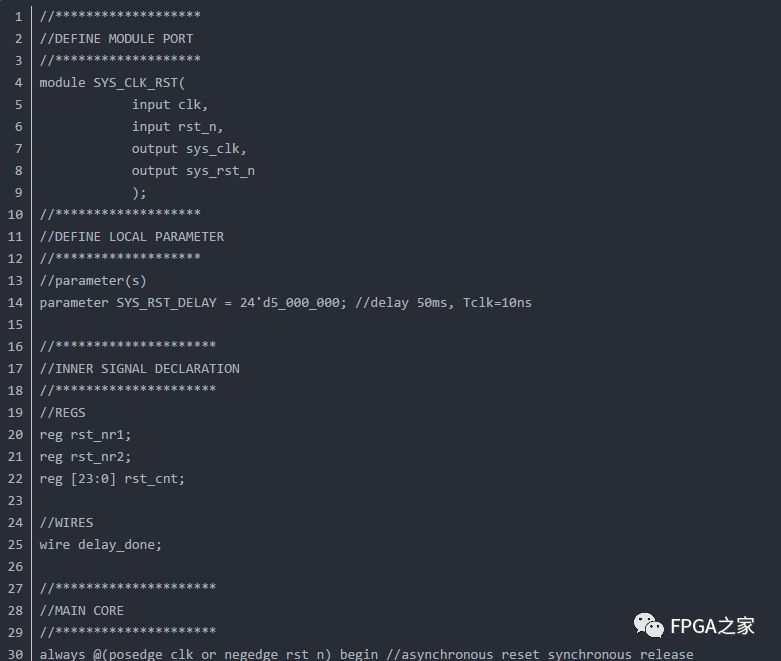
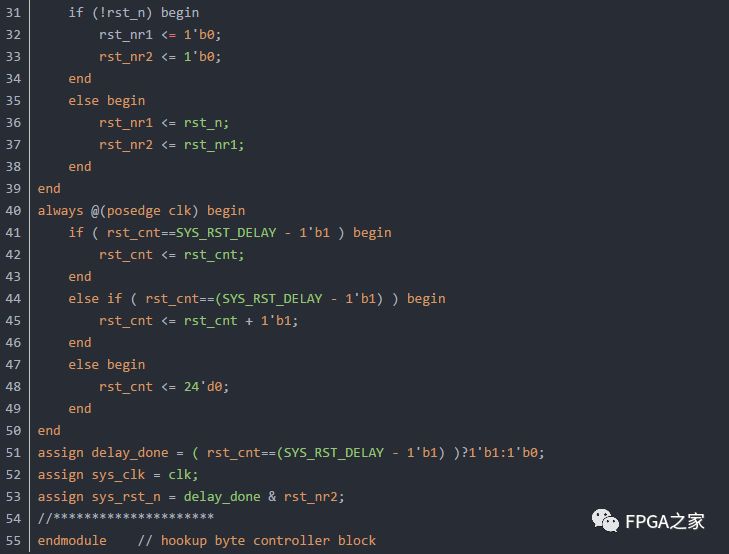
2、触发器与锁存器
2.1.解释
触发器Flip-Flop:收到输入脉冲,触发器输出根据赋值规则作出改变,保持此状态知道下一个触发。。。对时钟边沿敏感,其状态只在时钟的上升沿或者下降沿的瞬间改变;
锁存器Latch:两输入,EN和DATA_IN,当电平EN有效时,锁存器处于使能状态,输出数据Q随输入数据DATA_IN变化,否则数据被锁存;
2.2.区别
latch跟它所有的输入信号有关,当输入信号变化时,latch就变化,没有时钟触发;flip_flop受时钟控制,只有时钟沿触发时才采样当前输入,产生输出。
1)latch由电平触发,非同步控制。在使能信号有效时latch等效于通路,使能信号无效时latch保持输出状态;flip_flop由时钟沿触发,同步控制;
2)latch对输入电平敏感,受布线延迟影响较大,很难保证输出没有毛刺产生;flip_flop不易产生毛刺;
3)latch消耗的门资源比flip_flop少,但是其静态时序分析更为复杂;
2.3.CODE
针对网上博客所说,容易生成锁存器的四种情况:1)if语句结束无else;2)case语句结束无default;3)输出变量无赋初值;4)always@ (敏感信号)。我尝试过1),2)两种情况,遗憾的是,在Vivado17.2中综合后查看Schematic并没有看到有锁存器,就下边这段而言,case有无default,Schematic上看到的都是由FDCE(D触发器)和LUT(查找表)等元素组成,如图1所示。
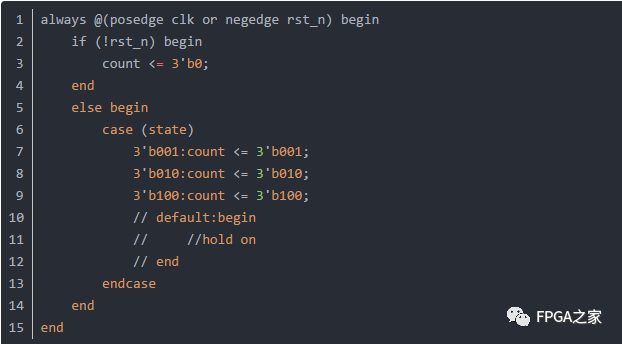
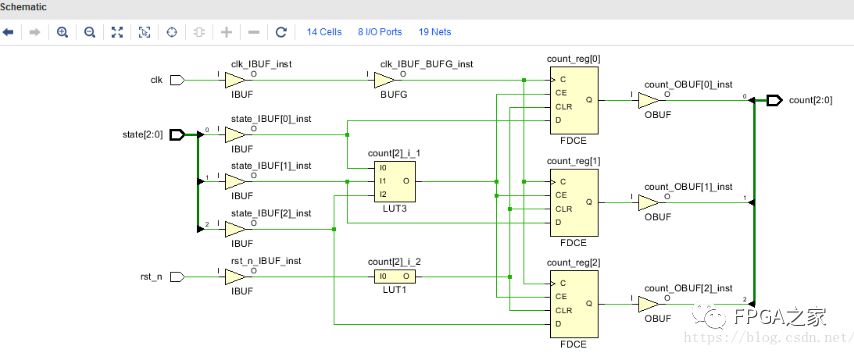
图1 case有无default后的Schematic
有博主是通过QUARTUS II中的Technology Map View查看门级电路,确是论证了上述四种情况,因为我也没用过QUARTUS II所以不进一步实验了,不过,综合后如果出现锁存器,Vivado17.2会在“Messege”窗口警告提示有latch。
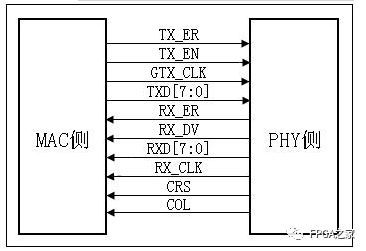
这儿所说的以太网接口只是其中三种,GMII,RGMII,SGMII,也是实验室所用的三种。首先说明一下MII(Media Independent Interface),不用考虑媒体材料是铜轴、电缆还是光纤,媒体处理的相关工作都有MAC芯片或者PHY来完成,MII支持10/100兆接口速率,而GMII(Gigabit MII)支持1000兆,同时往下兼容10/100兆速率。
3.1.GMII接口
GMII(Gigabit Media Independent Interface),数据位宽8bit,发送参考时钟和接收参考时钟均为125M,上升沿对数据采样,125M*8bit=1000Mbps。
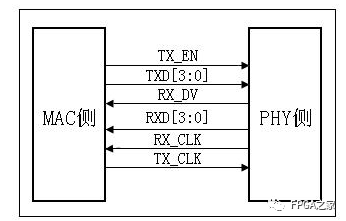
3.2.RGMII接口
RGMII(Reduced Gigabit Media Independent Interface),数据位宽4bit,发送参考时钟和接收参考时钟均为125M,上升沿发送GMII接口中的TXD[3:0]/RXD[3:0];在下降沿发送GMII接口中的TXD[7:4]/RXD[7:4]。这样速率就是125M*4bit*2=1000Mbps。向下兼容,取参考时钟为2.5M/25M,则接口速率为10/100Mbps。
拓展:DDR3也是上升沿下降沿采样,主时钟为400M,用户时钟为100M,突发长度为8,数据位宽为256bit,存储位宽为32bit,则MIG IP核的用户接口和内部存储接口速率匹配:100M*256bit=400M*32bit*2
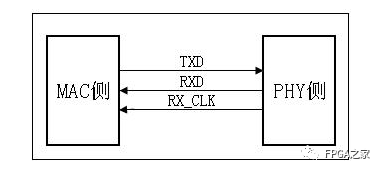
3.3.SGMII接口
SGMII(Serial Gigabit Media Independent Interface),既然是串行,那么数据位宽1bit,收发各有一对差分信号线,工作时钟由PHY提供,频率为625M,时钟的上升沿和下降沿均采样,考虑到IP核对串行数据进行了8b/10b编码,所以有效数据传输速率为625M*1bit*2*8b/10b=1000Mbps。
拓展:关于这个8/10b编码,最早由IBM发明应用,在pcie、hdmi及USB接口中均有体现,8/10b编码是高速串行总线常用的编码方式,为了保证直流平衡(数据流中出现的0/1数量基本一致,连续的0/1不超过5个)。。。hdmi中最小化传输差分信号的8/10b编码的前8位由原始数据经运算获得,第9位是“运算方式位”,表示前边8位是异或还是异或非等方式进行编码,第10位是为了保证直流平衡。
4、FPGA设计思想与技巧//2018-6-20 1640
4.1.乒乓操作
在第一个缓冲周期,将输入数据缓存到“数据缓冲模块1”;
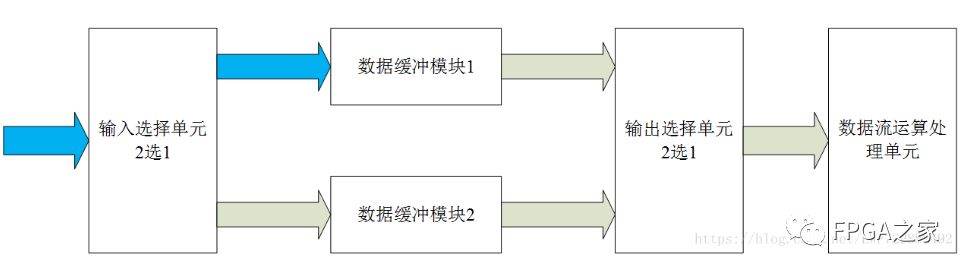
在第二个缓冲周期,通过“输入选择单元”切换,将输入数据流缓存到“数据缓冲模块2”中,同时将“数据缓冲模块1”缓存的第一个周期数据通过“输出选择单元”的选择,送到”数据流运算处理模块“进行数据处理;
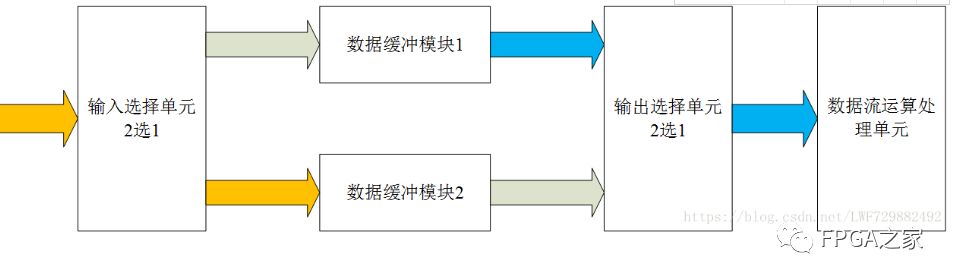
在第三个缓冲周期,再次通过“输入选择单元”切换,将输入数据流缓存到“数据缓冲模块1”中,同时将”数据缓冲模块2“缓存的第二个周期数据通过”输出选择单元“的选择,送到”数据流运算处理模块“进行数据处理;
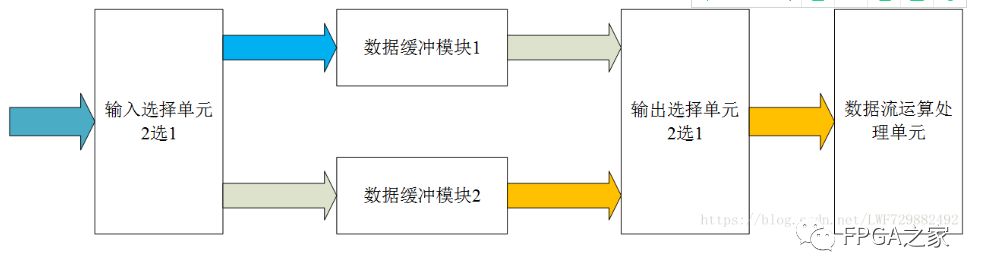
如此循环。。。
4.2.串并转换
串并转换的实现根据数据的排序和数量要求,可以选用寄存器、RAM等实现。乒乓操作就是通过DPRAM实现数据流的串并转换,由于使用DPRAM,数据缓冲区可以设置很大,,,对于数量较小的设计采用寄存器,如:temp<={ temp, srl_in }
4.3.流水操作
一种处理流程和顺序操作的设计思想,多使用寄存器以换取面积和速度
4.4.数据接口同步化
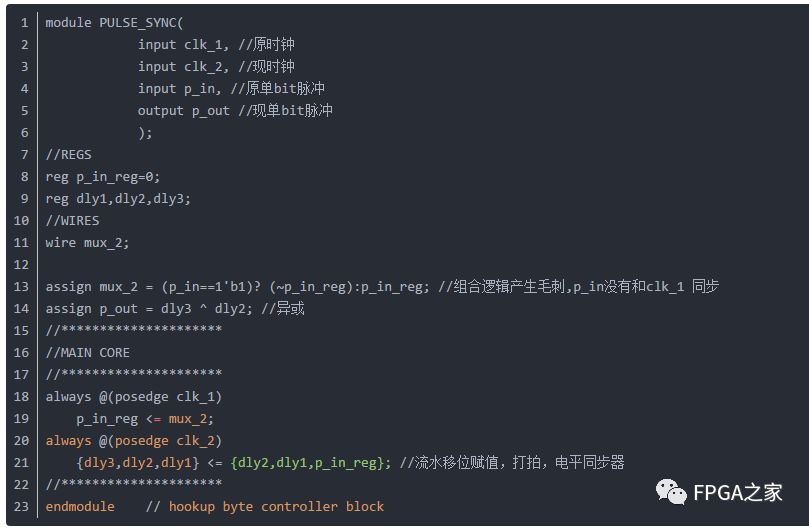
这里的数据可以是单bit数据也可以是多位宽数据,多位宽数据的话例化异步FIFO即可,这里主要讨论的是高频采低频的单bit(控制信号,脉冲使能信号等)。在文档“Crossing the abyss: Asynchronous signals in a synchronous world”中提及三种方法:1,.电平同步器(打拍,双锁存器法);2.边沿同步器;3.脉冲同步器(推荐,但是工程中觉得要例化这个模块很麻烦,还不如直接打两拍来得快),下边給出网上的脉冲同步器源代码,实测仿真可行。//Edited by LIUWF 设计思想:原时钟域下将原脉冲转为电平,然后在现时钟域下将输入电平打两拍,再异或处理得到现时钟域下的脉冲//
5、接口、总线与协议//2018-6-21 1542
在口头表达上,我总是把PCIe接口/总线/协议混为一谈,没有细致地作区分。昨晚跟室友讨论到这个点,在接口和协议部分达成了“共识”,当然,在总线部分也有一些小分歧,下边就这三种简练的説一下。
5.1.接口
接口理解为一类设备口。比如USB口、网口、PCIe口以及SATA口等
5.2.总线
总线这部分我理解是高速(差分)通道,IP核实现数据的串并转换,其实PCIe,MAC,SATA等都是基于Serdes接口传输的,换言之,底层都是Serdes串行高速信号传输,但是到IP层根据不同的应用场景可以是PCIe,MAC或者SATA。
5.3.协议
协议和接口一样比较好理解:传输数据数据的规则。比如PCIe每种TLP包有特定的包头封装规则;MAC的数据头部字段是0x55d5;
审核编辑:汤梓红










 工商网监
工商网监
评论