 德赢Vwin官网
App
德赢Vwin官网
App


摘要:P4语言极大地改变了网络领域,因为它可以快速描述和实现新的网络应用程序。尽管可以使用P4语言描述各种各样的应用程序,但是当前的可编程开关体系结构对P4程序施加了很大的限制。为了解决这个缺点,人们已经探索了将FPGA作为P4应用的潜在目标。P4应用程序使用三种抽象来描述:数据包解析器,匹配操作表和数据包逆解析器,后者使用匹配操作表的结果重新组合输出数据包。尽管FPGA上的数据包解析器和匹配表的实现已在文献中得到了广泛报道,但对于数据包逆解析器并没有提出一般的设计原理。
实际上,在FPGA上实现高速高效的逆解析器仍然是一个悬而未决的问题,因为它需要大量的互连,并且必须针对P4程序量身定制该体系结构。
因此,在一些在FPGA上实现P4应用程序的工作中,逆解析器消耗了大量的芯片资源。因此,在本文中,我们通过介绍FPGA上高效和快速的逆解析器的设计原理来解决这个问题。
作为一个神器,我们将介绍一种可通过P4程序生成高效的,可诊断的逆解析器架构的工具。我们的设计已通过基于cocotb的框架进行了验证和仿真。最终的架构在Xilinx Ultrascale + FPGA上实现,并支持200 Gbps以上的吞吐量,同时与其他解决方案相比将资源使用量减少了近10倍。
CCS概念:
• 硬件→可重新配置的逻辑应用程序;
• 计算机系统组织→可重构计算;高级语言架构;
• 网络→编程接口。
01
INTRODUCTION
P4域特定语言(DSL)[6]重塑了网络域,因为它允许描述具有很大灵活性的自定义数据包转发应用程序。使用FPGA卸载网络任务的兴趣日益浓厚。例如,微软已经在其数据中心部署了FPGA,以实现Azure服务器的数据平面[8]。网络内计算是最近考虑使用FPGA的另一种途径[20]。
另外,最近的一些工作利用FPGA可重配置性来创建可编程数据平面并实现P4应用[5、13、21]。 如图1所示,P4应用程序包含三个抽象:数据包解析器,处理阶段(匹配动作表)和数据包逆解析器(第2.2节)。尽管已经广泛探索了FPGA上高效数据包解析器的设计[3、5、19],但很少有精力致力于高效数据包逆解析器的实现。首先,据我们所知,仅一篇论文涵盖了该主题[7]。然而,Cabal等人[7]仅报告了100 Gbps数据包逆解析器的FPGA资源消耗,而未涵盖设计原理和微体系结构细节。
第二,如Luinaud等[16]观察到,数据包逆分解器可能会消耗超过80%的资源来实现一个完整的流水线,这会危害FPGA来实现更复杂的P4应用程序的能力。
本文介绍了一种开源代码解决方案,可在FPGA上生成高效且高速的数据包逆解析器。它为FPGA数据包逆解析器的设计原理奠定了基础。它包括一个体系结构和一个编译器,可从P4程序生成一个逆解析器。
用Python描述了逆解析器编译器(第4节),并为提出的逆解析器体系结构生成了可综合的VHDL代码。
生成的架构利用了FPGA固有的可配置性,从而避免了无法在FPGA上有效实现的硬件构造,例如交叉开关或桶形移位器[1,25]。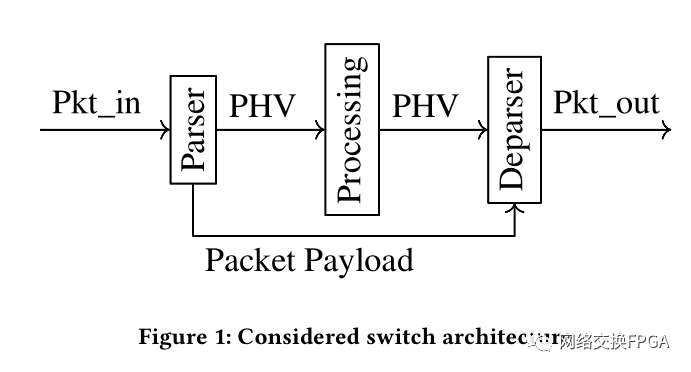
仿真环境基于cocotb [11],它允许使用几个现成的Python包(例如Scapy)来生成测试用例。另外,可以将测试中的设计与虚拟网络接口[12]连接起来。结果,可以使用P4行为参考模型来进行行为验证[17]。
已针对各种数据包头评估了生成的体系结构。评估显示,与最新解决方案(第5节)相比,生成的逆解析器支持200 Gbps以上的数据包吞吐量,同时将资源使用量减少10倍以上。
本文的贡献如下:
• 利用FPGA可配置性(§3)的逆解析器架构;
• 开源P4-to-VHDL数据包逆解析器编译器(第4节);
• 基于cocotb的仿真环境,可简化逆解析器验证(第5节)。
02
数据包处理
本节介绍P4语言以及如何组织P4程序组件来描述数据包处理。
>2.1 P4语言
P4 [6]是命令性DSL,用于描述可编程数据平面上的自定义数据包处理。
· 2.1.1 P4程序概述
构成P4程序的组件有四个:标头,解析器,控制和switch。报头是由特定宽度的字段和有效位组成的结构。标头的结构用于定义可以由P4程序处理的标头集。解析器块表示顺序和提取包头的方式。控制块描述了对标头执行的操作。
·2.1.2 控制操作
在控制块中,可以执行多种操作类型来修改标头。逆解析器需要关注两个特定的操作setValid和setInvalid,这两个操作可分别用于将标头有效性位设置为有效或无效。
在P4中,控制块还实现了解析逻辑。这些块由一系列的emit语句组成。首先,这些语句的顺序决定了标题的发出顺序。
其次,仅在设置了有效位的情况下才发送头。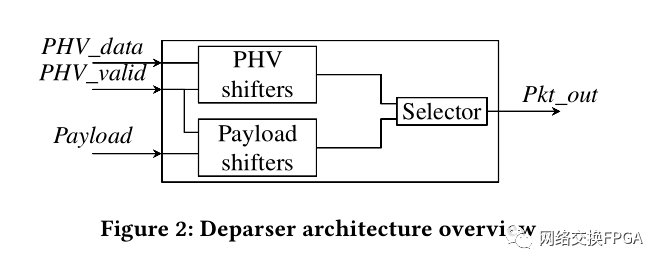
由于发出语句的顺序决定了报头的发出顺序,并且由于可以由先前的控制块更改有效性位,因此逆解析器必须能够在运行时插入或删除报头。
>2.2 P4程序组件
本文考虑了Benáček等人提出的交换结构[5]由三部分组成:解析器,处理部分和逆解析器,如图1所示。
解析器。
解析器将数据包作为输入,并生成数据包头矢量(PHV)和数据包有效负载。在我们的设计中,我们假设PHV由两部分组成:包含标头数据的PHV_data总线和指示每个标头组件有效性位的位图矢量PHV_valid总线。我们还假设数据包有效负载是通过流总线发送的,第一个字节位于位置0。
处理过程。
处理部分从解析器中获取PHV作为输入,并输出修改后的PHV,并将其转发给逆解析器。PHV上的操作可以是标头数据修改或标头有效性位更改。
逆解析器。
逆解析器模块将来自处理部分的PHV和来自解析器的有效负载作为输入。它输出要在流式总线上发送的数据包。
03
Deparser架构原则
在本节中,我们介绍Deparser架构原则。首先,我们介绍一个Deparser抽象机。其次,我们介绍了Deparser I / O信号。第三,我们介绍了拟议的Deparser的微体系结构。我们所有的设计选择都使用FPGA固有的可配置性,并为Deparser编译器提供可配置的模块。
>3.1 Deparser抽象机
Deparser抽象机如图2所示。在此体系结构中,我们假设PHV已缓冲并与PHV有效向量一起到达了Deparser。
算法1展示了PHV移位器模块的伪代码,而算法2展示了有效载荷移位器。
在FPGA上实现逆解析器的主要限制因素是头插入所需的大量互连和桶形移位器。为了限制这些块的使用,我们基于标头和有效载荷构造了一个新数据包。因此,由于可以在编译时完全推断出P4解析逻辑,并且由于FPGA是可重新配置的,因此我们为指定的P4程序定制了逆解析器架构,以减轻这些限制因素。
现在,我们介绍了Deparser的输入和输出。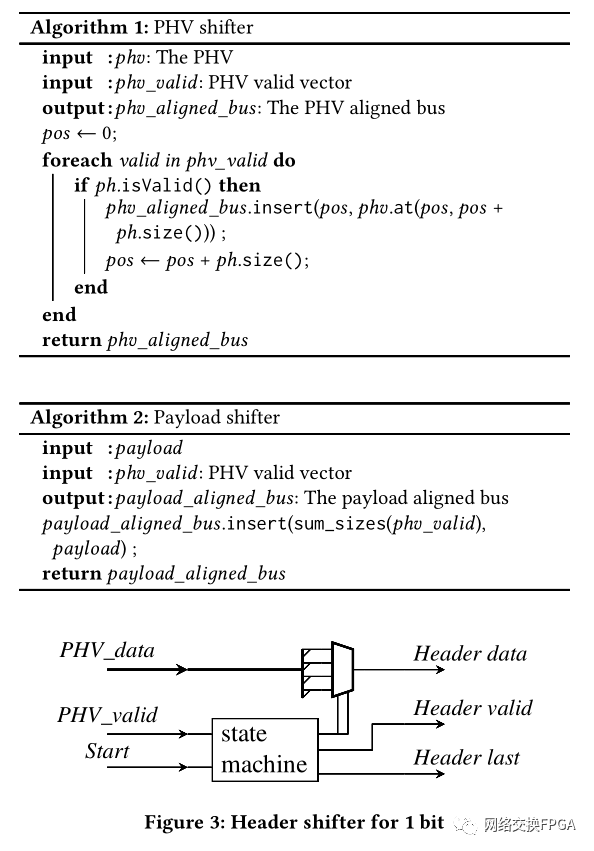
>3.2 输入和输出
该逆解析器具有3个输入和1个输出。输出Pkt_out和输入有效负载是AXI4流总线[2]。这两个总线的数据宽度是一个编译时间参数。两个输入PHV_data和PHV_valid分别包含标题数据和要解析的有效性位。在编译P4应用程序时,将确定PHV_data和PHV_valid的宽度。
>3.3 微体系结构细节
在内部,逆解析器是围绕三个块构建的:PHV移位器,有效负载移位器和选择器。PHV移位器获取PHV_data和PHV_valid作为输入,并输出要发送的头帧。
有效载荷移位器接收有效载荷和PHV_valid作为输入,并生成有效载荷数据帧。有效负载移位器和PHV移位器都输入到选择器。选择器根据有效负载移位器和PHV移位器接收到的状态生成Pkt_out帧。 ·
3.3.1 PHV移位器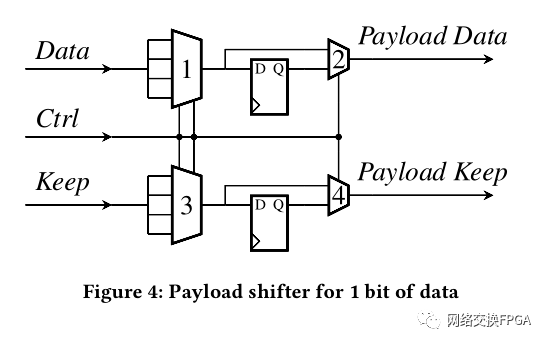
PHV移位器将PHV位移位以构建数据包。它由图3所示的标头移位器组成。标头移位器的最大数量等于Pkt_out总线宽度。
标头移位器具有三个输入:PHV_data,PHV_valid和启动信号。它输出:标头数据,有效的标头和最后的标头。PHV_valid和启动输入连接到状态机模块。状态机模块驱动标题有效和标题最后输出。PHV_data输入连接到驱动头数据输出的多路复用器。多路复用器根据状态机模块的一个输出选择PHV_data的位之一。状态机是从逆解析器图(§4)以及多路复用器的输入数量中得出的。
· 3.3.2有效负载转换器
有效负载移位器将有效负载与发出的标题对齐。有效负载移位器的基本模块如图4所示。它以数据,Ctrl和Keep作为输入,并输出有效负载数据和有效负载保持信号。数据总线和Keep总线分别连接到Deparser的有效负载输入总线的AXI tdata和tkeep信号。该总线的每个字节都连接到图4中多路复用器1的一个输入。
Keep信号的每个位都连接到多路复用器3的一个输入。Ctrl信号确定应选择多路复用器1和3的哪个输入。最后,可以注册多路复用器1和3的输出,以将数据输出延迟一个周期。多路复用器2和4选择当前值或延迟值。Ctrl总线的值由在编译时生成的较小且恒定的关联内存设置。
· 3.3.3 选择器
该模块在有效负载移位器和PHV移位器之间选择正确的输出数据,并生成AXI4流输出信号数据包数据,数据包保留和数据包最后。选择器将有效负载移位器的输出和PHV移位器的输出作为输入,如图5所示。
分组数据和分组保持信号由块数据选择分配。该块被复制以分配所有分组数据位。
根据输入信号“具有有效负载”指示的有效负载的存在,“最后一个包”信号是“ PHV最后”或“有效负载最后”。
· 3.3.4 FPGA上的多路复用器
所呈现的不同构造块高度依赖于FPGA上的多路复用器实现。我们选择使用多路复用器,因为它们已在FPGA上有效实现。实际上,一个16:1的多路复用器在Xilinx FPGA上消耗了一个切片[23]。虽然拥有一个非常大的多路复用器会变得很昂贵,但我们知道每个多路复用器的输入数量将由编译器减少到最少(第4.2.2节)。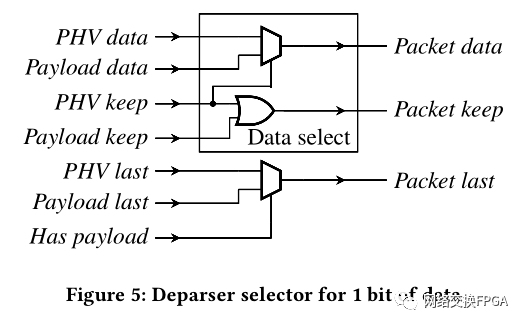
04
生成逆解析器
逆解析器可以表示为有向无环图(DAG)。为了生成Deparser DAG,使用p4c-bm2-ss编译器将P4程序编译为JSON文件[18]。生成的JSON文件然后用于生成一个Deparser DAG。可以优化此DAG,但是此优化留给以后的工作。本节的其余部分介绍了从Deparser DAG生成不同的Deparser模块的过程。
>4.1 Deparser DAG
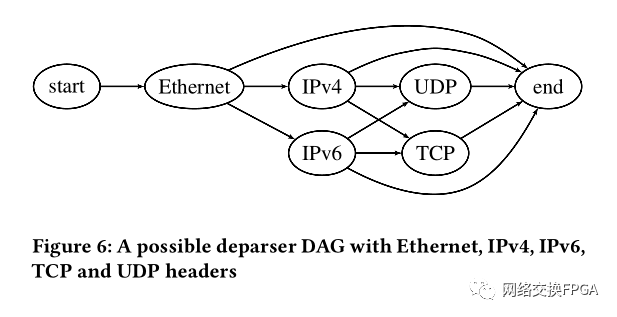
用于以太网,IPv4,IPv6,TCP和UDP数据包的Deparser DAG的示例如图6所示。DAG的每个节点(不包括开头和结尾)均表示一个报头。DAG的每个箭头表示可能要发出的下一个报头。起始和结束之间的每个路径代表可能发出的一组报头。
表1列出了所有可能的路径。
为了从DAG获得逆解析器,有两个部分。第一部分对deparser图进行变换,以生成PHV移位器。第二部分使用deparser图生成净荷移位器。
>4.2 PHV移位器的生成
为了生成PHV移位器的标题移位器,我们构建了deparser图的sub-DAG。每个子DAG代表一个报头移位器块(第3.3.1节)。由于大多数网络协议都是按字节对齐的[5],因此我们为每个输出字节构建一个sub-DAG。这允许合并PHV移位器状态机,因此降低了逆解析器的体系结构复杂性。
· 4.2.1子DAG的生成
在子DAG中,每个节点都包含标题和要提取的字节。每个边缘都指示要到达相应下一节点的报头有效性条件。我们提出了算法3来生成子DAG。
所提出的算法通过遍历De
parser图来遍历所有可能的标头发射序列。我们将序列的每个字节分配给一个子DAG。当子DAG第一次处理来自特定标头的字节时,我们将边缘条件设置为此标头。图7显示了使用算法3使用图6的deparserDAG和128位输出总线生成的子DAG。
· 4.2.2 Sub-DAG转换
子DAG转换分为两个部分:标头移位器多路复用器生成和状态机生成。生成的多路复用器的输入数量等于子DAG中的节点数量。状态机是从子DAG派生的,其中每个节点代表一个状态,每个边沿代表一个过渡。头字节位置被转换为多路复用器的输入位置。
>4.3有效载荷移位器关联内存的创建
有效载荷移位器体系结构在第3.3.2节中介绍。我们使用该图生成驱动Ctrl信号的关联内存。使用deparser图可以分两步生成此内存。首先,我们通过查看Deparser图表中开始和结束之间的所有可能路径来确定可能的有效标头的设置PH。集合PH中的每个元素ph由PHV_valid总线值和所有标头宽度的总和组成。

建立集合PH后,对于每个可能的元素ph∈PH,我们为Ctrl分配一个值。对于每个可能的PHV_valid值,我们计算有效负载的偏移量。使用等式Offset = phw(mod w)获得偏移,其中w是总线宽度,而phw表示发出的标头的总位数。最后,我们为位于偏移值以下的每个有效负载移位器设置连接到图4的多路复用器2和4的Ctrl位的值。
05
结果
本节介绍了这项工作的结果。首先,我们描述实验设置。然后,我们介绍了编译器参数对生成的体系结构的影响。最后,我们将实现结果与以前的工作进行比较。
>5.1实验设置
我们为以下三个协议栈生成了逆解析器:
•T1:以太网,IPv4 / IPv6,TCP / UDP
•T2:以太网,IPv4 / IPv6,TCP / UDP,ICMP / ICMPv6
•T3:以太网,2×VLAN,2×MPLS,IPv4 / IPv6, TCP / UDP,ICMP / ICMPv6
为了验证我们的工作,我们基于cocotb框架[11]开发了一个仿真平台。我们为AXI4-stream总线开发了cocotb驱动程序和监视器,从而使我们能够快速评估不同的Deparser配置。Xilinx Vivado 2019.1用于合成和布局布线。为了实现可重复性,我们的代码是开放的1。
>5.2编译器参数的影响
为了评估图形复杂度的影响,我们从非优化的deparserDAG和逆解析器DAG(被视为优化的逆解析器DAG)生成并合成了逆解析器。使用解析器DAG作为逆解析器DAG是在P4 14 [9]中提出的实现。表2列出了针对Xilinx xcvu3p-3 FPGA时,每个综合运行的Block RAM(BRAM),查找表(LUT)和触发器(FF)的使用情况。结果表明,两个因素主导着资源的使用:复杂度和数据总线宽度。
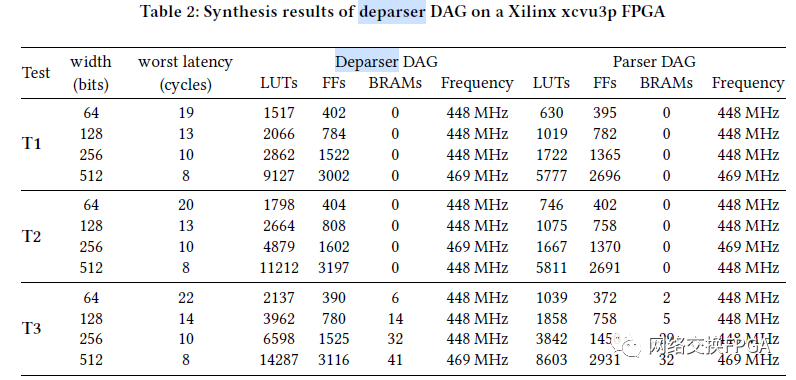
图的复杂度。
图形的复杂性受逆解析器代码和图形简化程度的影响。由于简化的Deparser DAG具有较少的边,因此可减少其PHV_shifter的状态机和有效负载移位器的关联内存的大小。另外,每个子DAG需要更少的节点。结果,减少了PHV移位器复用器的输入数量。例如,在T1中,有5个标头。对于未优化的解析器DAG,这将导致总共32条路径,而简化的逆解析器图仅包含7条路径。
总线宽度。除了图形复杂度之外,总线宽度还会影响资源消耗。提出的设计具有6个时钟周期的延迟。而且,输出数据包的等待时间是要发射的总报头长度和总线宽度的函数。如表2所示,对于大型公交车,与较小型公交车相比,最坏情况的等待时间减少了。标头发射的最坏情况延迟可以通过以上公式计算。
同样,增加总线宽度会增加LUT和FF的使用率。对于64位至256位不等的数据总线,资源使用量会略有增加,但是对于512位总线而言,这种增加变得非常重要。有两个因素可以解释这种较高的复杂性。首先,多路复用器的最小数量以每个输出位1个多路复用器的速率增加。其次,对于较大的总线,由于标头对齐,因此对于每个输出帧,可以将更多标头附加到总线上。
因此,PHV移位器的可能输入的重用较少。
>5.3实现结果
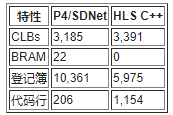
我们还为三个协议栈(具有512位数据总线)实现了非优化的Deparser DAG。我们将Deparser实施结果与Xilinx SDNet 2017.4 [24]和Benáček等人生成的Deparser进行了比较[5]。这些实现的结果显示在表3中。我们的Deparser支持的吞吐量比Benáček等人提出的Deparser大20 Gpbs[5],同时将资源使用量减少5倍。
与Xilinx SDNet [24]生成的逆解析器相比,在最坏的情况下,我们的逆解析器支持的吞吐量低60 Gbps,但我们的逆解析器使用的资源却少了近10倍。
比较实施和综合结果时,资源消耗保持稳定。在T1和T2的情况下,布局布线后的性能几乎相同。但是,可以通过对多路复用器进行流水线化来提高最大时钟频率,而不会显着影响资源消耗。实际上,生成的体系结构每个切片消耗少于一个FF,而典型的切片则具有八个FF。结果,未使用的FF可以用于流水线复用器,因为它们不太可能由其他模块驱动。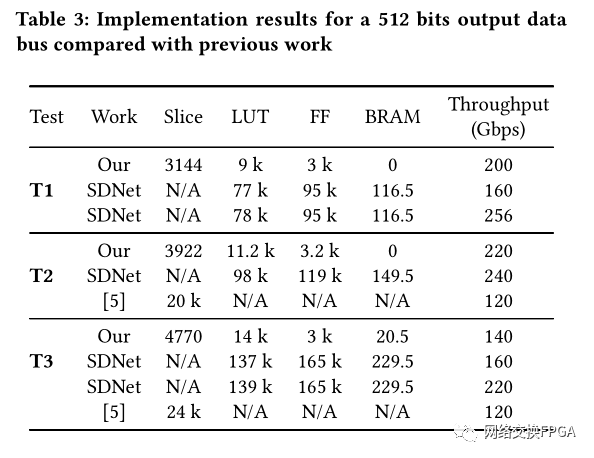
06
相关工作
Wang等提出了P4FPGA [22]。P4FPGA是面向中等性能FPGA(10 Gbps)的开源且与供应商无关的P4-to-FPGA编译器。Ibanez等[14]建议将Xilinx SDNet P4编译器[24]集成到现成的NetFPGA板[15]中。
这项工作暴露了SDNet在实现逆解析器逻辑方面的局限性,事实证明这是所生成管道中资源消耗最大的模块[16]。确实,根据我们的实验,我们观察到Xilinx SDNet无法优化分解图中的不可达路径。
Benáček等 [5]提出了自动生成基于P4的数据包解析器和VHDL的逆解析器。这项工作扩展到了逆解析器之前对数据包解析器的研究[4]。但是,由于优化是从数据包解析器的设计中得出的,因此没有涵盖该逆解析器的体系结构和设计原理。其他数据包解析器研究包括[3,10,19]。. Gibb等 [10]介绍了数据包解析器的一般设计原理,但未涵盖数据包逆解析器的情况。另外,Attig和Brebner [3]提出了一种语言来代表解析器,并带有架构和编译器,以在FPGA上实现它们。另外,圣地亚哥·达席尔瓦(Santiago da Silva)等人。[19]提议使用图优化,类似于我们的工作,以简化解析器管道。
07
结论
P4改变了网络格局,因为它允许表达自定义数据包处理。近年来,有几篇著作将P4程序映射到FPGA。但是,这些工作大部分都集中在实现数据包解析器或match action阶段。迄今为止,尚未提出关于FPGA的通用数据包逆解析原理。
确实,先前关于生成解析逻辑的工作的幼稚方法已经使该模块的硬件实现在FPGA上非常昂贵。在这项工作中,我们通过介绍一套在FPGA上实现数据包逆解析器的设计原则来解决这个问题。在我们的工作中,我们提出了一种与FPGA微体系结构紧密耦合的体系结构,以利用FPGA固有的可配置性。
我们还演示了简化逆解析器图以减少资源消耗的重要性。我们的结果表明,我们提出的去解析器体系结构跨越了100 Gbps的吞吐量边界,同时将资源消耗减少了一个数量级。最后,为了实现可复制性,我们开源了我们的框架和基于cocotb的集成仿真环境。
审核编辑:刘清










 工商网监
工商网监
评论