 德赢Vwin官网
App
德赢Vwin官网
App


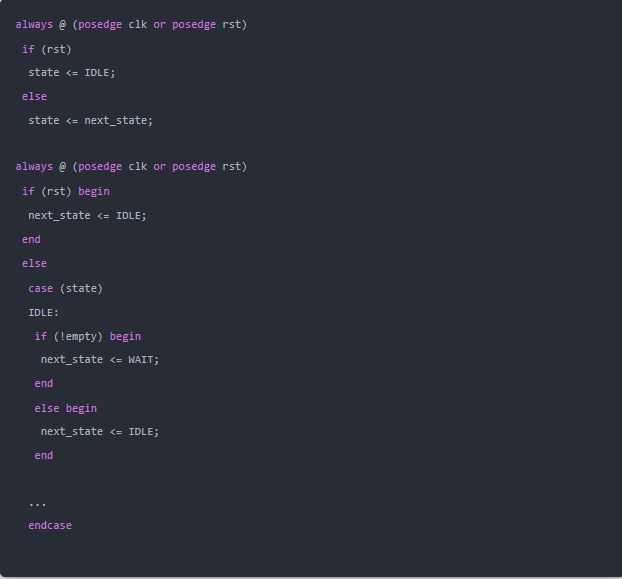
用三段式描述状态机的好处,国内外各位大牛都已经说的很多了,大致可归为以下三点:
1.将组合逻辑和时序逻辑分开,利于综合器分析优化和程序维护;
2.更符合设计的思维习惯;
3.代码少,比一段式状态机更简洁。
对于第一点,我非常认可,后两点在Clifford E. Cummings著的(Synthesizable Finite State Machine Design Techniques Using theNew SystemVerilog 3.0 Enhancements和The Fundamentals ofEfficient Synthesizable Finite State Machine Design using NC-Verilog andBuildGates)中多次提到,我并不完全赞同,下面谈谈我的一些看法。
先谈谈第二点关于思维习惯。我发现有些人会有这样一种习惯,先用一段式状态机实现功能,仿真ok后,再将其转成三段式,他们对这种开发方式的解释是一段式更直观,可以更便捷的构建功能框架,但是大家都说三段式性能会更好,所以最后又在搭好的逻辑框架下,将一段式转化为了三段式。这从一个侧面说明了,对一部人来说一段式更符合他们的思维习惯,但当已经习惯了一段式的思维方式后,再要换用三段式时,可就不这么容易了,一段式和三段式的写法之间存在着思维陷阱,特权同学也曾经不小心在此失足过。
举一个例子,初始状态是wr_st,q和p输出都为0,当计数器count计数到指定的数值10后,输出结束信号end,状态机接收到end有效后跳转为 rd_st,同时输出q变为1,在rd_st状态,如jump有效则跳转到erase_st,如end有效p输出0否则输出1,用一段式实现起来很简单,如下所示。
assign end = (count == 10);
always @(posedge clk)
begin
case(state)
wr_st: if(end) begin
q 《= 1;
state《= rd_st;
end
else begin
q 《= 0;
state《= wr_st;
end
rd_st: if(jump) begin
p 《=1;
state《= erase_st;
end
elseif(end) begin
p 《= 0;
state《= rd_st;
end
else begin
p 《= 1;
state《= rd_st;
end
。..
endcase
end
状态机一
输出波形如下所示。
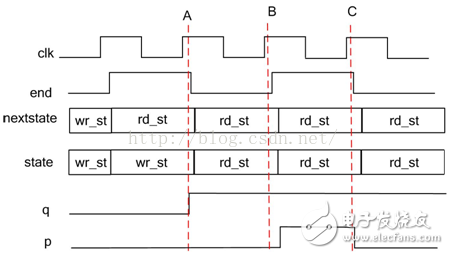
图一
换用三段式描述时,有些人会写成这样。
always @(posedge clk or negedge rst)
begin
if(!rst) state 《= wr_st;
else state 《=nextstate;
end
always @(*)
begin
case(state)
wr_st: if(end) nextstate = rd_st;
else nextstate = wr_st;
rd_st: if(jump) nextstate = erase_st
else nextstate = rd_st;
。..
end
endcase
always @(posedge clk)
begin
case(nextstate)
wr_st: if(end) q 《= 1;
else q《= 0;
rd_st: if(end) p 《= 0;
else p 《= 1;
。..
endcase
end
状态机二
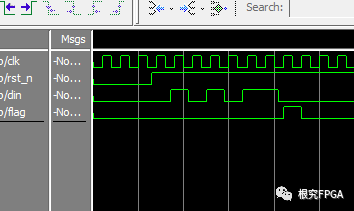
看似代码好像没有什么问题,但从输出波形可以看出,q没有正确输出。
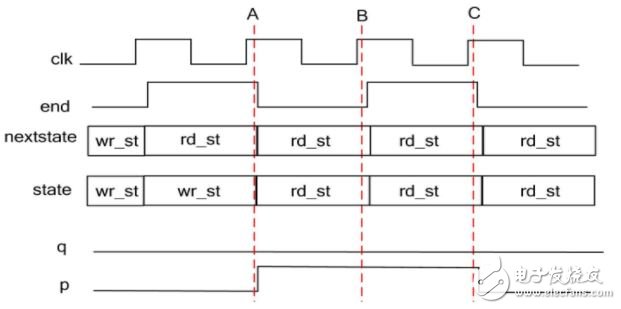
图二
上图中状态转移正确,但是q输出错误,nextstate由组合逻辑输出,当end有效后,nextstate立刻变为rd_st,导致A时刻q没有变化,在将一段式改为三段式的过程中,我们仍保留了一段式的思维习惯,想当然的利用了end信号去控制状态跳转,同时又控制了q的输出,这种思维误区由以下两点对三段式状态机的认知缺陷构成。
1.书本网上大部分状态机例程的第三段都是基于nextstate输出的,很少看到有基于state输出的,这就形成了一种思维定势,认为三段式的第三段只能基于nextstate描述。
2.当三段式状态机的输出基于nextstate描述时,无法用同一个输入信号即触发当前状态跳转,又控制当前状态输出正确逻辑,上述例子中A时刻q的错误输出印证了这一点,end可以触发状态从wr_st跳转到rd_st,但无法同时让q输出1。
有两种解决办法。
第一种解决办法是增加状态,将wr_st拆分为wr_st0和wr_st1两个状态,end信号只控制状态跳转,q的输出跟随wr_st0和wr_st1变化,第一段不变,如下所示
always @(*)
begin
case(state)
wr_st0: if(end) nextstate = wr_st1;
else nextstate = wr_st0;
wr_st1: nextstate= rd_st;
rd_st: if(jump) nextstate = erase_st;
else nextstate = rd_st;
。..
end
endcase
always @(posedge clk)
begin
case(nextstate)
wr_st0: q《= 0;
wr_st1: q《= 1;
rd_st: if(end) p 《= 0;
else p 《= 1;
。..
endcase
end
状态机三
更改后波形输出正确,如图一所示。有些人会觉得这种方式没有一段式直观,数据手册标明的协议只有写和读两个状态,为什么用三段式状态机描述时还要增加一个状态呢?反而有一种拼凑时序的感觉;另一些人会觉得这种思维方式很自然,协议里只有两个状态,但是每个状态里又会有不同的输出,根据输入和输出的不同可以将一个状态解剖为多个细分状态,状态分的越细,越利于综合工具分析优化,但是状态太多了也不利于人员的查看维护。将这个问题延展开,目前网站书籍中讲解状态机的例子都以“状态多,输出少”为主,这种类型的状态机,不用太多考虑状态划分问题,直接用moor型就ok了,不过,现实工作中我们还会遇到很多“状态少,输出多”的情况,那该如何划分状态呢?
一帮人会觉得状态少更直观,使用尽量少的状态,把所有跟当前状态相关的输出都写在同一个状态里,这种习惯会倾向于写成一段式或者mealy型;
一帮人觉得如果一个状态里的输出太多了不利于理解,会使用尽量多的状态,每一个状态只对应一种输出,这种习惯会将状态机倾向写成moor型。
如换用上文的例程,主张状态少的帮派会写成一段式的状态机一,或写成错误的状态机二,主张多状态的帮派会写成状态机三,从性能方面考虑,后者将状态细分的更清楚,综合工具会更容易优化分析,获得更好的性能,但是综合工具altera和xilinx每年都在更新,分析能力也越来越强,越来越聪明,减少开发者的经验门槛,按这种趋势,前者和后者的性能差异也会逐年缩小。从维护升级的方面考虑,前者和后者的输出都一样,但是前者的状态少,代码会更少些,更利于查看,对代码理解上面,本来就存在两种不同的思维习惯,只能智者见智了。
回到本例中,第二种解决办法是,仅将状态机二的第三段的nextstate换成state,其他两段不变,如下所示。
always @(posedge clk)
begin
case(state)
wr_st: if(end) q 《= 1;
else q《= 0;
rd_st: if(end) p 《= 0;
else p《= 1;
。..
endcase
end
输出波形和一段式相同,如图一所示,三段式状态机的第三段并没有规定一定要基于nextstate输出,只是主流资料在介绍三段式状态机时,多用moor型为例,moor型的特点是输出仅由状态决定,当状态变化时,输出立刻变化,如要实现输出紧跟着状态变化,第三段中就必须要基于nextstate输出才可以,对比图一和图二B时刻,使用state时,当前状态已经变为rd_st,输出p滞后了一个时钟才输出,而使用nextstate时,当前状态变为 rd_st的同时输出p就变化了,再比较图一和图二的C时刻,在同一个状态下,end有效后,两者的p输出都一样,所以可得出,第三段使用nextstate和state的区别在于,当状态跳转时,基于nextstate的输出是立刻变化的,而基于state输出会延迟一个周期,其他情况都一样,应该根据自己的时序要求,选择用nextstate还是state。
这里提到的三段式的思维陷阱,特权同学曾经也不小心犯过,所著的《深入浅出玩转FPGA》的p40,漫谈状态机设计一节中举了sram的例子比较一段式和三段式的区别,一段式是可以按照程序正常运行的,但是三段式的输出在读取的状态下会和一段式略有不同,当cstate进入RD_S1时,如果此时wr_req有效,cmd不会输出3`b101,而是3`b111,问题在于使用了 wr_req同时控制了RD_S1的跳转和cmd输出,RD_S2也存在同样的问题,如下所示。
case(cstate)
。..
RD_S1: if(wr_req) nstate 《=WR_S2;
else nstate 《= RD_S2;
RD_S2: if(wr_req) nstate 《=WR_S1;
else nstate 《= IDLE;
。..
endcase
。..
case(nstate)
。..
WR_S2: cmd 《= 3‘b111;
RD_S1: if(wr_req) cmd 《=3’b101;
else cmd 《= 3‘b110;
RD_S2: if(wr_req) cmd 《=3’b011;
else cmd 《= 3‘b111;
。..
endcase
再回到开篇,谈谈第三点关于代码量,Clifford E. Cummings在文中提到一段式状态机会比三段式状态机会多20%到80%的代码量,并举例证明。但是举得例子都有一个特点“状态多,输出少”,比如有 10种状态,但是输出种类只有5种,很多的状态都是相同的输出,这在第三段式描述时就可以利用case的简写语法减少代码量,如下所示
case (next)
S0, S2, S4, S5 : ; // defaultoutputs
S7 : y3《= 1’b1;
S1 : y2《= 1‘b1;
S3 :begin
y1《= 1’b1;
y2《= 1‘b1;
end
S8 :begin
y2《= 1’b1;
y3《= 1‘b1;
end
S6,S9 : begin
y1《= 1’b1;
y2《= 1‘b1;
y3《= 1’b1;
end
endcase
但是实际的状态机中,还有很多是“状态少,输出多”的情况,每种状态都会有不同的输出,这就无法利用上述的case的简写语法了,再试着比较一下,一段式和三段式的输出逻辑代码量几乎一样,状态转移部分也差不多,但是在输入判断代码量方面,一段式只用判断一次可完成状态转移和输出,对于mealy型,第二段和第三段都要判断,这就肯定比一段式多了,对于moor型,第二段需要判断一次,第三段虽然不用判断但是为了实现相同的功能肯定要将状态扩展,相比一段式增加了不少的代码量。所以不能一概而论一段式的代码量就一定比三段式多,要视具体情况而定。











 工商网监
工商网监
评论