使用Isaac Gym来强化学习mycobot抓取任务
2023-04-11 14:57:12 5344
5344 
什么是深度强化学习? 众所周知,人类擅长解决各种挑战性的问题,从低级的运动控制(如:步行、跑步、打网球)到高级的认知任务。
2023-07-01 10:29:501002 
Facebook近日推出ReAgent强化学习(reinforcement learning)工具包,首次通过收集离线反馈(offline feedback)来实现策略评估(policy evaluation)。
2019-10-19 09:38:411347 一:深度学习DeepLearning实战时间地点:1 月 15日— 1 月18 日二:深度强化学习核心技术实战时间地点: 1 月 27 日— 1 月30 日(第一天报到 授课三天;提前环境部署 电脑
2021-01-09 17:01:54
利用ML构建无线环境地图及其在无线通信中的应用•使用深度学习的收发机设计和信道解码基于ML的混合学习方法,用于信道估计、建模、预测和压缩 使用自动编码器等ML技术的端到端通信•无线电资源管理深度强化学习
2021-07-01 10:49:03
时间安排大纲具体内容实操案例三天关键点1.强化学习的发展历程2.马尔可夫决策过程3.动态规划4.无模型预测学习5.无模型控制学习6.价值函数逼近7.策略梯度方法8.深度强化学习-DQN算法系列9.
2022-04-21 14:57:39
一:深度学习DeepLearning实战时间地点:1 月 15日— 1 月18 日二:深度强化学习核心技术实战时间地点: 1 月 27 日— 1 月30 日(第一天报到 授课三天;提前环境部署 电脑
2021-01-10 13:42:26
,Deep Learning—迁移学习5,Deep Learning—深度强化学习6,深度学习的常用模型或者方法深度学习交流大群: 372526178 (资料共享,加群备注杨春娇邀请)
2018-09-05 10:22:34
不断变化的,因此深度学习是人工智能AI的重要组成部分。可以说人脑视觉系统和神经网络。2、目标检测、目标跟踪、图像增强、强化学习、模型压缩、视频理解、人脸技术、三维视觉、SLAM、GAN、GNN等。
2020-11-27 11:54:42
多智能体系统深度强化学习:挑战、解决方案和应用的回顾摘要介绍背景:强化学习前提贝尔曼方程RL方法深度强化学习:单智能体深度Q网络DQN变体深度强化学习:多智能体挑战与解决方案MADRL应用结论和研究
2021-07-12 08:44:43
强化学习的另一种策略(二)
2019-04-03 12:10:44
如何训练AI玩飞机大战游戏(创号版)
2019-07-01 12:27:34
强化学习在RoboCup带球任务中的应用_刘飞
2017-03-14 08:00:00 0
0 界声誉卓著。在此前接受CSDN采访时,杨强介绍了他目前的主要工作致力于一个将深度学习、强化学习和迁移学习有机结合的Reinforcement Transfer Learning(RTL)体系的研究。那么,这个技术框架对工业界的实际应用有什么用的实际意义?在本文中,CSDN结合杨强的另外一个身份国内人工智能创业
2017-10-09 18:23:180 请订阅2016年《程序员》 尽管监督式和非监督式学习的深度模型已经广泛被技术社区所采用,深度强化学习仍旧显得有些神秘。这篇文章将试图揭秘
2017-10-09 18:28:430 与监督机器学习不同,在强化学习中,研究人员通过让一个代理与环境交互来训练模型。当代理的行为产生期望的结果时,它得到正反馈。例如,代理人获得一个点数或赢得一场比赛的奖励。简单地说,研究人员加强了代理人的良好行为。
2018-07-13 09:33:0024320 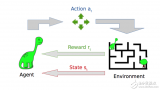
深度强化学习DRL自提出以来, 已在理论和应用方面均取得了显著的成果。尤其是谷歌DeepMind团队基于深度强化学习DRL研发的AlphaGo,将深度强化学习DRL成推上新的热点和高度,成为人工智能历史上一个新的里程碑。因此,深度强化学习DRL非常值得研究。
2018-06-29 18:36:0027596 萨顿在专访中(再次)科普了强化学习、深度强化学习,并谈到了这项技术的潜力,以及接下来的发展方向:预测学习
2017-12-27 09:07:1510857 针对路径规划算法收敛速度慢及效率低的问题,提出了一种基于分层强化学习及人工势场的多Agent路径规划算法。首先,将多Agent的运行环境虚拟为一个人工势能场,根据先验知识确定每点的势能值,它代表最优
2017-12-27 14:32:020 本文提出了一种LCS和LS-SVM相结合的多机器人强化学习方法,LS-SVM获得的最优学习策略作为LCS的初始规则集。LCS通过与环境的交互,能更快发现指导多机器人强化学习的规则,为强化学习系统
2018-01-09 14:43:490 在风储配置给定前提下,研究风电与储能系统如何有机合作的问题。核心在于风电与储能组成混合系统参与电力交易,通过合作提升其市场竞争的能力。针对现有研究的不足,在具有过程化样本的前提下,引入强化学习算法
2018-01-27 10:20:502 传统上,强化学习在人工智能领域占据着一个合适的地位。但强化学习在过去几年已开始在很多人工智能计划中发挥更大的作用。
2018-03-03 14:16:563924 让我们在强化学习社区感兴趣的问题上应用随机搜索。深度强化学习领域一直把大量时间和精力用于由OpenAI维护的、基于MuJoCo模拟器的一套基准测试中。这里,最优控制问题指的是让一个有腿机器人
2018-04-01 09:35:004193 
强化学习是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大,强化学习不同于连接主义学习中的监督学习,主要表现在教师信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价
2018-05-30 06:53:001234 当我们使用虚拟的计算机屏幕和随机选择的图像来模拟一个非常相似的测试时,我们发现,我们的“元强化学习智能体”(meta-RL agent)似乎是以类似于Harlow实验中的动物的方式在学习,甚至在被显示以前从未见过的全新图像时也是如此。
2018-05-16 09:03:394475 
自动驾驶汽车首先是人工智能问题,而强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物。今天人工智能头条给大家介绍强化学习在自动驾驶的一个应用案例,无需3D地图也无需规则,让汽车从零开始在二十分钟内学会自动驾驶。
2018-07-10 09:00:294676 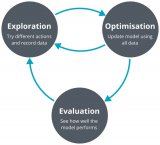
前段时间,OpenAI的游戏机器人在Dota2的比赛中赢了人类的5人小组,取得了团队胜利,是强化学习攻克的又一游戏里程碑。
2018-07-13 08:56:014439 
这些都是除了从零学习之外的强化学习方法。特别是元学习和零次学习体现了人在学习一种新技能时更有可能的做法,与纯强化学习有差别。一个元学习智能体会利用先验知识快速学习棋类游戏,尽管它不明白游戏规则
2018-07-14 08:42:287602 强化学习是人工智能基本的子领域之一,在强化学习的框架中,智能体通过与环境互动,来学习采取何种动作能使其在给定环境中的长期奖励最大化,就像在上述的棋盘游戏寓言中,你通过与棋盘的互动来学习。
2018-07-15 10:56:3717106 
这些具有一定难度的任务 OpenAI 自己也在研究,他们认为这是深度强化学习发展到新时代之后可以作为新标杆的算法测试任务,而且也欢迎其它机构与学校的研究人员一同研究这些任务,把深度强化学习的表现推上新的台阶。
2018-08-03 14:27:264305 结合 DL 与 RL 的深度强化学习(Deep Reinforcement Learning, DRL)迅速成为人工智能界的焦点。
2018-08-09 10:12:435789 深度强化学习的理论、自动驾驶技术的现状以及问题、深度强化学习在自动驾驶技术当中的应用及基于深度强化学习的礼让自动驾驶研究。
2018-08-18 10:19:574854 强化学习作为一种常用的训练智能体的方法,能够完成很多复杂的任务。在强化学习中,智能体的策略是通过将奖励函数最大化训练的。奖励在智能体之外,各个环境中的奖励各不相同。深度学习的成功大多是有密集并且有效的奖励函数,例如电子游戏中不断增加的“分数”。
2018-08-18 11:38:573363 而这时,强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
2018-08-21 09:18:2519123 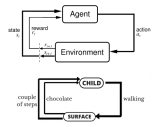
强化学习(RL)研究在过去几年取得了许多重大进展。强化学习的进步使得 AI 智能体能够在一些游戏上超过人类,值得关注的例子包括 DeepMind 攻破 Atari 游戏的 DQN,在围棋中获得瞩目的 AlphaGo 和 AlphaGo Zero,以及在 Dota2 对战人类职业玩家的Open AI Five。
2018-08-31 09:20:493498 强化学习是一种非常重要 AI 技术,它能使用奖励(或惩罚)来驱动智能体(agents)朝着特定目标前进,比如它训练的 AI 系统 AlphaGo 击败了顶尖围棋选手,它也是 DeepMind 的深度
2018-09-03 14:06:302653 直接的强化学习方法很有吸引力,它无需过多假设,而且能自动掌握很多技能。由于这种方法除了建立函数无需其他信息,所以很容易在改进后的环境中重新学习技能,例如更换了目标物体或机械手。
2018-09-05 08:54:159616 强化学习是一种训练主体最大化奖励的学习机制,对于目标条件下的强化学习来说可以将奖励函数设为当前状态与目标状态之间距离的反比函数,那么最大化奖励就对应着最小化与目标函数的距离。
2018-09-24 10:11:006779 按照以往的做法,如果研究人员要用强化学习算法对奖励进行剪枝,以此克服奖励范围各不相同的问题,他们首先会把大的奖励设为+1,小的奖励为-1,然后对预期奖励做归一化处理。虽然这种做法易于学习,但它也改变了智能体的目标。
2018-09-16 09:32:035336 之前接触的强化学习算法都是单个智能体的强化学习算法,但是也有很多重要的应用场景牵涉到多个智能体之间的交互。
2018-11-02 16:18:1521016 本文作者通过简单的方式构建了强化学习模型来训练无人车算法,可以为初学者提供快速入门的经验。
2018-11-12 14:47:394570 针对提高视觉图像特征与优化控制之间契合度的问题,本文提出一种基于深度强化学习的机械臂视觉抓取控制优化方法,可以自主地从与环境交互产生的视觉图像中不断学习特征提取,直接地将提取的特征应用于机械臂抓取
2018-12-19 15:23:5922 OpenAI 近期发布了一个新的训练环境 CoinRun,它提供了一个度量智能体将其学习经验活学活用到新情况的能力指标,而且还可以解决一项长期存在于强化学习中的疑难问题——即使是广受赞誉的强化算法在训练过程中也总是没有运用监督学习的技术。
2019-01-01 09:22:002122 
强化学习(RL)能通过奖励或惩罚使智能体实现目标,并将它们学习到的经验转移到新环境中。
2018-12-24 09:29:562949 了一种人工智能系统,即通过深度强化学习来学习走路,简单来说,就是教“一个四足机器人来穿越熟悉和不熟悉的地形”。
2019-01-03 09:50:133286 针对深度强化学习中卷积神经网络(CNN)层数过深导致的梯度消失问题,提出一种将密集连接卷积网络应用于强化学习的方法。首先,利用密集连接卷积网络中的跨层连接结构进行图像特征的有效提取;然后,在密集连接
2019-01-23 10:41:513 在一些情况下,我们会用策略函数(policy, 总得分,也就是搭建的网络在测试集上的精度(accuracy),通过强化学习(Reinforcement Learning)这种通用黑盒算法来优化。然而,因为强化学习本身具有数据利用率低的特点,这个优化的过程往往需要大量的计算资源。
2019-01-28 09:54:224705 Google AI 与 DeepMind 合作推出深度规划网络 (PlaNet),这是一个纯粹基于模型的智能体,能从图像输入中学习世界模型,完成多项规划任务,数据效率平均提升50倍,强化学习又一突破。
2019-02-17 09:30:283036 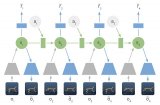
在传统的多智体学习过程当中,有研究者在对其他智能体建模 (也即“对手建模”, opponent modeling) 时使用了递归推理,但由于算法复杂和计算力所限,目前还尚未有人在多智体深度强化学习 (Multi-Agent Deep Reinforcement Learning) 的对手建模中使用递归推理。
2019-03-05 08:52:434556 ANYMAL与被植入了硬性程序的机器人不同,在深度强化学习的加持下,ANYMAL具有自我学习、自我升级的能力,因而能适应更多场景。
2019-03-21 10:07:346510 不可否认,深度学习的热度已经大大下降,赞美深度学习作为AI终极算法的推文少得多了,而且论文正在变得不那么“革命”,现在大家换了个词,叫:进化。
2019-04-29 08:56:203218 近日,Reddit一位网友根据近期OpenAI Five、AlphaStar的表现,提出“深度强化学习是否已经到达尽头”的问题。
2019-05-10 16:34:592313 近年来,深度强化学习(Deep reinforcement learning)方法在人工智能方面取得了瞩目的成就,从 Atari 游戏、到围棋、再到无限制扑克等领域,AI 的表现都大大超越了专业选手,这一进展引起了众多认知科学家的关注。
2019-05-30 17:29:352550 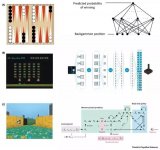
近年来,深度强化学习(Deep reinforcement learning)方法在人工智能方面取得了瞩目的成就
2019-06-03 14:36:052619 在谷歌最新的论文中,研究人员提出了“非政策强化学习”算法OPC,它是强化学习的一种变体,它能够评估哪种机器学习模型将产生最好的结果。数据显示,OPC比基线机器学习算法有着显著的提高,更加稳健可靠。
2019-06-22 11:17:083374 深度学习也增强了强化学习这一已存在的领域。
2019-07-11 16:06:461464 所以,Google这两篇强化学习应用于YouTube推荐论文的出现给大家带来了比较振奋人心的希望。首先,论文中宣称效果对比使用的Baseline就是YouTube推荐线上最新的深度学习模型;
2019-07-18 11:11:008388 
近几年来,强化学习在任务导向型对话系统中得到了广泛的应用,对话系统通常被统计建模成为一个 马尔科夫决策过程(Markov Decision Process)模型,通过随机优化的方法来学习对话策略。
2019-08-06 14:16:291836 深度学习DL是机器学习中一种基于对数据进行表征学习的方法。深度学习DL有监督和非监督之分,都已经得到广泛的研究和应用。
2020-01-30 09:53:005546 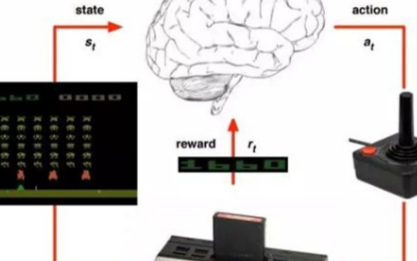
深度学习DL是机器学习中一种基于对数据进行表征学习的方法。深度学习DL有监督和非监督之分,都已经得到广泛的研究和应用。
2020-01-24 10:46:004734 惰性是人类的天性,然而惰性能让人类无需过于复杂的练习就能学习某项技能,对于人工智能而言,是否可有基于惰性的快速学习的方法?本文提出一种懒惰强化学习(Lazy reinforcement learning, LRL) 算法。
2020-01-16 17:40:00745 本文档的主要内容详细介绍的是深度强化学习的笔记资料免费下载。
2020-03-10 08:00:000 )的研究人员联合发表了一篇论文,详细介绍了他们构建的一个通过 AI 技术自学走路的机器人。该机器人结合了深度学习和强化学习两种不同类型的 AI 技术,具备直接放置于真实环境中进行训练的条件。
2020-03-17 15:15:301354 强化学习(RL)是现代人工智能领域中最热门的研究主题之一,其普及度还在不断增长。 让我们看一下开始学习RL需要了解的5件事。
2020-05-04 18:14:003117 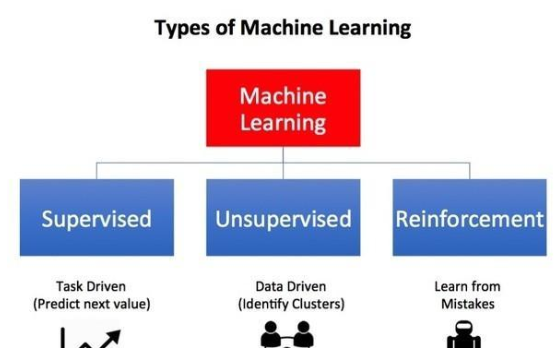
深度学习DL是机器学习中一种基于对数据进行表征学习的方法。深度学习DL有监督和非监督之分,都已经得到广泛的研究和应用。强化学习RL是通过对未知环境一边探索一边建立环境模型以及学习得到一个最优策略。强化学习是机器学习中一种快速、高效且不可替代的学习算法。
2020-05-16 09:20:403150 深度学习DL是机器学习中一种基于对数据进行表征学习的方法。深度学习DL有监督和非监督之分,都已经得到广泛的研究和应用。强化学习RL是通过对未知环境一边探索一边建立环境模型以及学习得到一个最优策略。强化学习是机器学习中一种快速、高效且不可替代的学习算法。
2020-06-13 11:39:405527 近期,有不少报道强化学习算法在 GO、Dota 2 和 Starcraft 2 等一系列游戏中打败了专业玩家的新闻。强化学习是一种机器学习类型,能够在电子游戏、机器人、自动驾驶等复杂应用中运用人工智能。
2020-07-27 08:50:15715 Viet Nguyen就是其中一个。这位来自德国的程序员表示自己只玩到了第9个关卡。因此,他决定利用强化学习AI算法来帮他完成未通关的遗憾。
2020-07-29 09:30:162429 训练最新 AI 系统需要惊人的计算资源,这意味着囊中羞涩的学术界实验室很难赶上富有的科技公司。但一种新的方法可以让科学家在单台计算机上训练先机的 AI。2018 年 OpenAI 报告每 3.4 个月训练最强大 AI 所需的处理能力会翻一番,其中深度强化学习对处理尤为苛刻。
2020-07-29 09:45:38581 不过,深度神经网络系统往往需要大量的训练数据,以及已知答案的带标签样本,才能正常地工作。并且,它们目前尚无法完全模仿人类学习和运用智慧的方式。
2020-08-28 14:21:065744 
强化学习属于机器学习中的一个子集,它使代理能够理解在特定环境中执行特定操作的相应结果。目前,相当一部分机器人就在使用强化学习掌握种种新能力。
2020-11-06 15:33:491552 深度强化学习是深度学习与强化学习相结合的产物,它集成了深度学习在视觉等感知问题上强大的理解能力,以及强化学习的决策能力,实现了...
2020-12-10 18:32:50374 RLax(发音为“ relax”)是建立在JAX之上的库,它公开了用于实施强化学习智能体的有用构建块。。报道:深度强化学习实验室作者:DeepRL ...
2020-12-10 18:43:23499 本文主要介绍深度强化学习在任务型对话上的应用,两者的结合点主要是将深度强化学习应用于任务型对话的策略学习上来源:腾讯技术工程微信号
2020-12-10 19:02:45781 强化学习( Reinforcement learning,RL)作为机器学习领域中与监督学习、无监督学习并列的第三种学习范式,通过与环境进行交互来学习,最终将累积收益最大化。常用的强化学习算法分为
2021-04-08 11:41:5811 深度强化学习(DRL)作为机器学习的重要分攴,在 Alphago击败人类后受到了广泛关注。DRL以种试错机制与环境进行交互,并通过最大化累积奖赏最终得到最优策略。强化学习可分为无模型强化学习和模型
2021-04-12 11:01:529 当机器人遇见强化学习,会碰出怎样的火花? 一名叫 Cassie 的机器人,给出了生动演绎。 最近,24 岁的中国南昌小伙李钟毓和其所在团队,用强化学习教 Cassie 走路 ,目前它已学会蹲伏走路
2021-04-13 09:35:092164 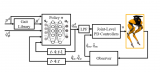
利用深度强化学习技术实现路口信号控制是智能交通领域的硏究热点。现有硏究大多利用强化学习来全面刻画交通状态以及设计有效强化学习算法以解决信号配时问题,但这些研究往往忽略了信号灯状态对动作选择的影响以及
2021-04-23 15:30:5321 目前壮语智能信息处理研究处于起步阶段,缺乏自动词性标注方法。针对壮语标注语料匮乏、人工标注费时费力而机器标注性能较差的现状,提出一种基于强化学习的壮语词性标注方法。依据壮语的文法特点和中文宾州
2021-05-14 11:29:3514 压边为改善板料拉深制造的成品质量,釆用深度强化学习的方法进行拉深过程旳压边力优化控制。提岀一种基于深度强化学习与有限元仿真集成的压边力控制模型,结合深度神经网络的感知能力与强化学习的决策能力,进行
2021-05-27 10:32:390 一种新型的多智能体深度强化学习算法
2021-06-23 10:42:4736 基于深度强化学习的无人机控制律设计方法
2021-06-23 14:59:1046 基于强化学习的虚拟场景角色乒乓球训练
2021-06-27 11:34:3362 使用Matlab进行强化学习电子版资源下载
2021-07-16 11:17:090 多Agent 深度强化学习综述 来源:《自动化学报》,作者梁星星等 摘 要 近年来,深度强化学习(Deep reinforcement learning,DRL) 在诸多复杂序贯决策问题中取得巨大
2022-01-18 10:08:011226 
本文主要内容是如何用Oenflow去复现强化学习玩 Flappy Bird 小游戏这篇论文的算法关键部分,还有记录复现过程中一些踩过的坑。
2022-01-26 18:19:342 来源:DeepHub IMBA 强化学习的基础知识和概念简介(无模型、在线学习、离线强化学习等) 机器学习(ML)分为三个分支:监督学习、无监督学习和强化学习。 监督学习(SL) : 关注在给
2022-12-20 14:00:02828 德赢Vwin官网
网站提供《ESP32上的深度强化学习.zip》资料免费下载
2022-12-27 10:31:450 作者:Siddhartha Pramanik 来源:DeepHub IMBA 目前流行的强化学习算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。这些算法
2023-02-03 20:15:06747 本文介绍了强化学习与智能驾驶决策规划。智能驾驶中的决策规划模块负责将感知模块所得到的环境信息转化成具体的驾驶策略,从而指引车辆安全、稳定的行驶。真实的驾驶场景往往具有高度的复杂性及不确定性。如何制定
2023-02-08 14:05:161441 强化学习(RL)是人工智能的一个子领域,专注于决策过程。与其他形式的机器学习相比,强化学习模型通过与环境交互并以奖励或惩罚的形式接收反馈来学习。
2023-06-09 09:23:23355 ,可以节省至多 95% 的训练开销。 深度强化学习模型的训练通常需要很高的计算成本,因此对深度强化学习模型进行稀疏化处理具有加快训练速度和拓展模型部署的巨大潜力。 然而现有的生成小型模型的方法主要基于知识蒸馏,即通过迭
2023-06-11 21:40:02356 
机械臂抓取摆放及堆叠物体是智能工厂流水线上常见的工序,可以有效的提升生产效率,本文针对机械臂的抓取摆放、抓取堆叠等常见任务,结合深度强化学习及视觉反馈,采用AprilTag视觉标签、后视经验回放机制
2023-06-12 11:25:221221 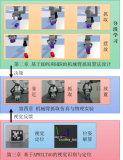
来源:DeepHubIMBA强化学习的基础知识和概念简介(无模型、在线学习、离线强化学习等)机器学习(ML)分为三个分支:监督学习、无监督学习和强化学习。监督学习(SL):关注在给定标记训练数据
2023-01-05 14:54:05419 
作者:SiddharthaPramanik来源:DeepHubIMBA目前流行的强化学习算法包括Q-learning、SARSA、DDPG、A2C、PPO、DQN和TRPO。这些算法已被用于在游戏
2023-02-06 15:06:38665 德赢Vwin官网
网站提供《人工智能强化学习开源分享.zip》资料免费下载
2023-06-20 09:27:281 摘要:基于强化学习的目标检测算法在检测过程中通常采用预定义搜索行为,其产生的候选区域形状和尺寸变化单一,导致目标检测精确度较低。为此,在基于深度强化学习的视觉目标检测算法基础上,提出联合回归与深度
2023-07-19 14:35:020 讯维模拟矩阵在深度强化学习智能控制系统中的应用主要是通过构建一个包含多种环境信息和动作空间的模拟矩阵,来模拟和预测深度强化学习智能控制系统在不同环境下的表现和效果,从而优化控制策略和提高系统的性能
2023-09-04 14:26:36296 
扩散模型(diffusion model)在 CV 领域甚至 NLP 领域都已经有了令人印象深刻的表现。最近的一些工作开始将 diffusion model 用于强化学习(RL)中来解决序列决策问题
2023-10-02 10:45:02403 
强化学习是机器学习的方式之一,它与监督学习、无监督学习并列,是三种机器学习训练方法之一。 在围棋上击败世界第一李世石的 AlphaGo、在《星际争霸2》中以 10:1 击败了人类顶级职业玩家
2023-10-30 11:36:401051 
 德赢Vwin官网
App
德赢Vwin官网
App









 工商网监
工商网监
评论