 德赢Vwin官网 App
德赢Vwin官网 App

自动驾驶领域在近两年被大家所熟悉,主要的市场诱导因素是Tesla在辅助智能驾驶和采用全视觉技术的影子模式为主的FAD(Full Auto Drive)的成功。我们认为,自动驾驶领域将是未来人工智能商业化落地非常重要的一个场景,并且能带来百亿级以上规模的企业的可能性非常之高。构建下一代人工智能基础设施的架构与工业化成功成为一个新的热点和行业内的必争高地。
作者简介:
作者为黑芝麻智能技术专家,系CCF高性能专委会委员、AAAI终身会员、中国智能计算产业联盟核心会员、上海市人工智能专家委员会委员、中国信通院大模型标准制定委员会委员、国内DSA领域的早期推广者与践行者、中国最早将分布式深度学习系统进行商业化落地并取得一定的社会效益。
文章速览:
DSA成为下一代AI计算平台的主流架构,加速异构计算
DSA-oriented Unified AI stack作为统一的 AI 基础软件设施,解决碎片化问题
黑芝麻智能华山系列芯片采用多核异构架构
建设易用的以CXE为基础的人工智能软件基础设施是AI落地的关键
打造非欧数据形式的融合算法模型是自动驾驶技术稳定产业化的基础
从事自动驾驶解决方案和车载智能芯片的企业都看到了一个巨大的机会,那就是自动驾驶场景将产生海量的、复杂的、多样的、高价值的数据。在当今数据即财富的时代,这一点给所有人带来了无限的想象空间。怎么把数据变现成价值、如何将数据变现并实现商业化,成为所有人的命题。而人工智能技术是普遍被学术界和产业界都认可的用来解决这个问题的一个技术。所以,构建下一代人工智能基础设施的架构与工业化成功成为一个新的热点,成为行业内的必争高地。
下一代人工智能基础设施的特征
下一代人工智能基础设施的重要特征,特别是面向自动驾驶或者机器智能领域,主要体现在:
1. Heterogeneous DSA(DSA: Domain SpecificArchitecture,下同)成为下一代AI计算平台的主流架构,加速异构计算
2. DSA-oriented Unified AI stack成为下一代AI的基础软件设施,解决碎片化问题
3. 更广泛算法网络的统一与支持
DSA成为AI计算的主流架构
在过去的四十年的体系结构发展中,架构师们通过利用各种技术来提升单芯片算力、优化架构,但最终的效果不尽如人意,特别是在更多复杂应用场景的大数据时代和智能应用环境下,通用计算架构受到了前所未有的挑战:
1、技术上,登纳德定律失效导致了功耗的优化成为限制;摩尔定律失效使得芯片晶体管的提升受到限制;
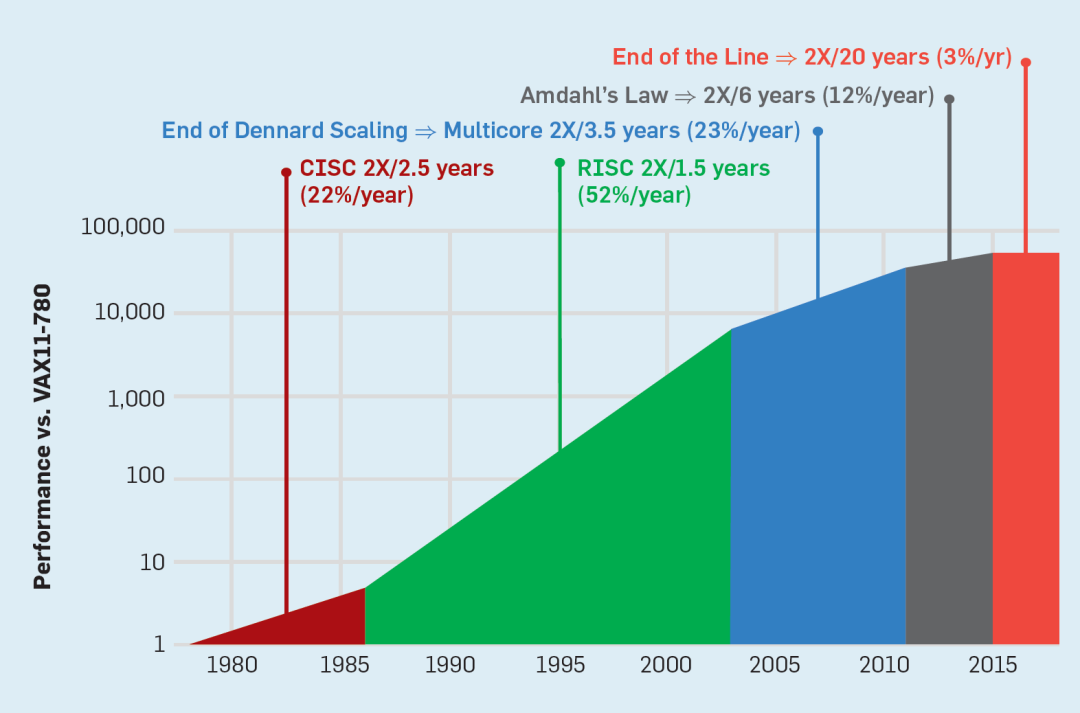
随着晶体管密度的增加,每个晶体管的能耗将降低,因此硅芯片上每平方毫米上的能耗几乎保持恒定。由于每平方毫米硅芯片的计算能力随着技术的迭代而不断增强,计算机将变得更加节能。然而,登纳德缩放定律从2007年开始大幅放缓,2012年左右接近失效(如下图):
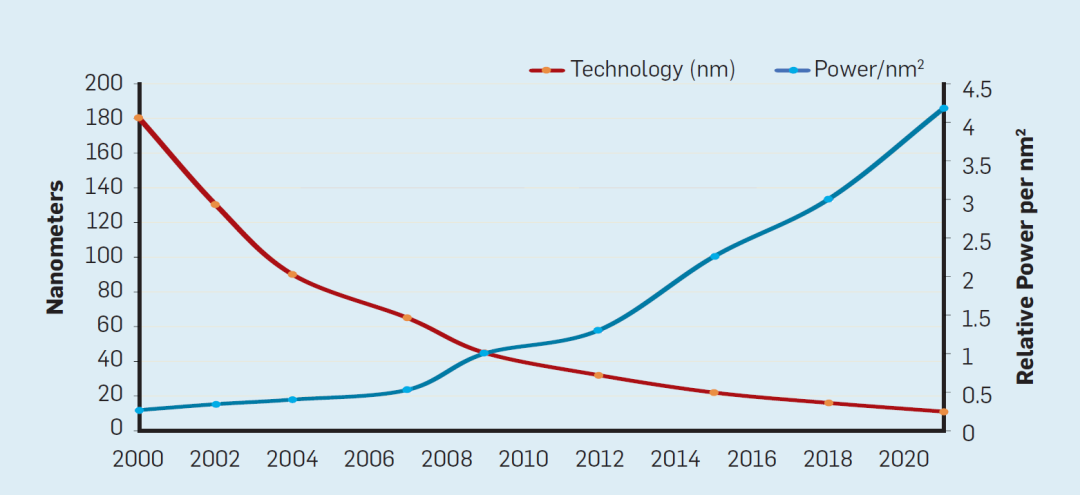
2、芯片体系架构上:指令集并行和单核性能优化已经成为瓶颈;阿姆达尔定律失效导致多核优化达到瓶颈;当前指令集和体系结构不能处理芯片安全问题;
根据“Iron law”可知,处理器的算力性能直接相关的参数就是:
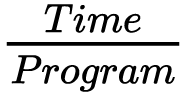
这个参数是指执行一个程序所花费的时间。该参数由以下的公式来决定:
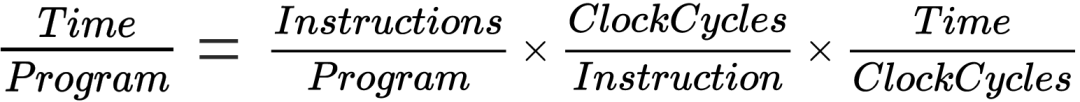
在以上的公式中,右侧式子的前两项由指令集来影响,第三项由芯片制程和工艺来决定。在微架构中增加指令的乱序执行和指令级并行技术来提升算力的性能,也就是上述公式的前两个因素。
3、应用场景上,海量的算力需求从PC和服务器时代,进化到物联网、云计算和移动互联网时代,海量的、多样的计算形式被催生出来;当前的算力基础设施及技术发展已经严重落后需求侧的算力要求。
在这样的环境下,数据流架构思想和技术由于更适合海量连续数据的处理、缓解内存墙问题的优势,在当前的人工智能领域更加受到关注。融合了数据流架构的深度学习处理器也不断地被设计和研发出来,用来解决不同场景下海量数据的算力“不足”问题。这些变化都是由于软硬件融合的设计与系统更适合于当前应用场景下对算力资源的需求。
人工智能在大数据的环境下得到了爆发式的增长,为高级编程语言python和tensorflow等特定领域语言通过增加软件重用、提高抽象级别,显著地提高了生产力。在此应用环境下,编译器与DSA体系结构更要进一步协同设计,专门解决该领域下的特殊特征。
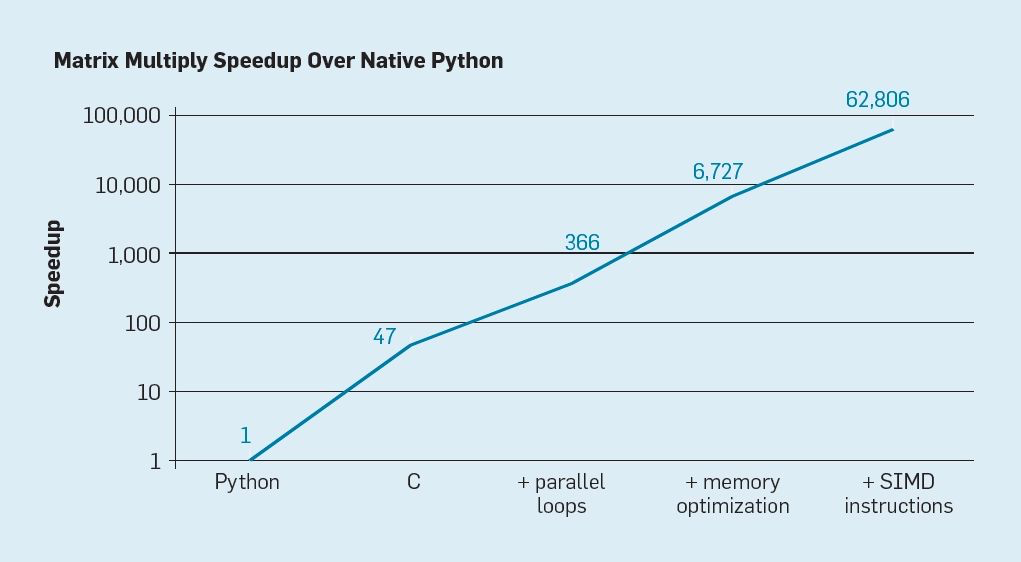
特定领域的体系结构。一种以硬件为中心的设计思路是设计面向特定问题和领域的架构,并给予它们强大且高效的性能,因此它们是特定领域的体系结构(DSA),这是一种特定领域的可编程处理器,通常是图灵完备的,但针对特定类别的应用进行了定制。DSA通常被称为加速器,因为与在通用CPU上执行整个应用程序相比,它们可以加速某些应用程序。此外,DSA可以实现更好的性能,因为它们更贴近应用的实际需求,比如图形加速单元(GPU),用于深度学习的神经网络处理器(NPU),以及软件定义网络处理器(SDNs)。DSA效率更高、能耗更低是因为以下四个原因:
首先,DSA为特定领域的计算使用了更加有效的并行形式。例如单指令多数据并行(SIMD),因为它在一个时钟步长内只需处理一个指令流和处理单元。DSA也可以使用VLIW方法来实现ILP(指令级并行),而不是推测性的乱序机制,当前AI处理器普遍采用in-order的流水线形势。如前文所述,VLIW处理器与通用性代码不匹配,但对于特定领域更加有效,因为它的控制机制更加简单。与之相对的是,VLIW在编译时执行必要的分析和调度,这对于显式并行程序来说可以很好地工作。
其次,DSA可以更有效地利用内存层次结构。通用处理器的运行代码,其中的存储器访问通常表现出空间和时间局部性,但在编译时不是非常可预测的。因此,CPU使用多级高速缓存来增加带宽,并掩盖相对较慢的芯片外DRAM延迟。在那些编译时可以很好地定义和发现内存访问模式的应用程序中(这对于典型的DSL来说是常见的),程序员和编译器可以比动态分配的缓存更好地优化内存的使用。
再次,DSA可以使用较低的精度。适用于通用任务的CPU通常支持32和64位整型数和浮点数数据。对于很多机器学习和图像应用来说,并不需要如此高的精确度。例如在深度神经网络中(DNN),推理通常使用4、8或16位整型数,从而提高数据和计算吞吐量。同样,对于DNN训练程序,浮点数很有意义,但FP32位就够了。当前移动端的推理过程以INT8精度为主;数据中心应用端的推理过程以更广泛的精度来满足要求。
最后,DSA受益于以特定领域语言(DSL)编写的目标程序,这些程序可以实现更高的并行性,更好的内存访问的结构和表示,并使应用程序更有效地映射到特定域的处理器,这也需要面向DSA的编译器的支持。
因此,体系结构领域的大佬(John Hennessy、David Patterson)、AI领域大佬(Jeff Dean、Cliff Young)在近几年内连续发文或分享说明,当下是领域专用架构DSA的黄金时代(Golden Age)。
统一的 AI 基础软件设施
2019 年Chris Lattner(LLVM 发明者)提出来有关DSA架构下的编译器的黄金时代:
在肯定了John Hennessy和David Patterson有关当下是DSA的黄金时代的判断之后,Chris也随之对适应于DSA架构的编译器提出了新的方向:
随着应用的爆发式发展、专用领域架构DSA的繁荣,比如AI和结构化计算技术发展领域,出现了标量加速和向量加速等多种层面的加速,当然现在还有多核CPU。这样一来就会出现多种硬件组合,这些硬件就必须相互通信。但软件还是很难充分利用它们来提高性能,而且如果软硬件协同不到位,性能就会受到巨大影响。
我们需要下一代编译器和编程语言来帮助解决这种碎片化。首先,计算机行业需要更好的硬件抽象,硬件抽象是允许软件创新的方式,不需要让每种不同设备变得过于专用化。
其次,我们需要支持异构计算,因为要在一个混合计算矩阵里做矩阵乘法、解码JPEG、非结构化计算等等。然后,还需要适用专门领域的语言,以及普通人也可以用的编程模型。
最后,我们也需要具备高质量、高可靠性和高延展性的架构。
在经历了科研范式的AI算法和场景落地之后,专业的工程化落地才是人工智能技术能力变现的唯一途径。为了解决AI系统和工具的单一化和碎片化的问题,我们提出来建立统一开放的人工智能软件基础设施的目标:建设面向工程化的人工智能软件基础设施,包括编译器、运行时,异构计算、边缘到数据中心并重,并专注于可用性,提升开发人员的效率。
算法网络的统一化与多样化
下图从深度学习算法的发展历程来看,总结了自人工智能伊始到现在的主要的算法与网络结构:
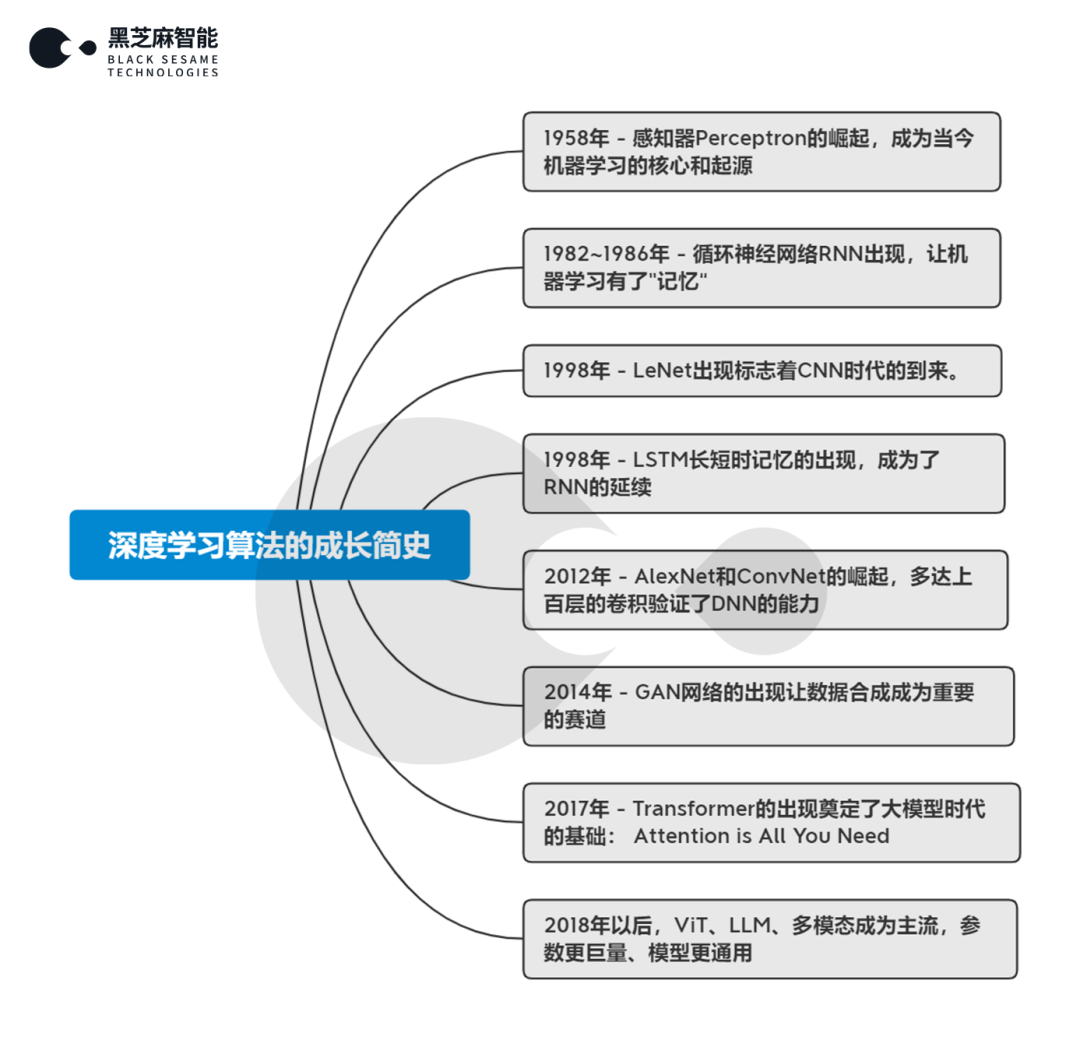
自2012年以后,以深度学习为基础的算法和网络带来了空前的繁荣。
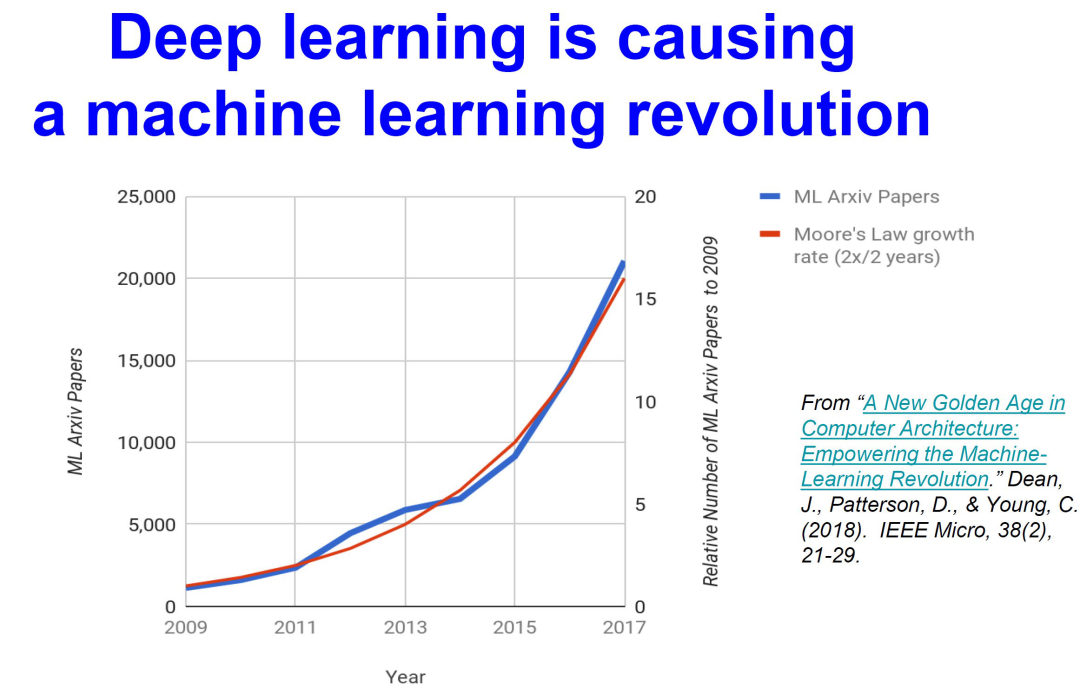
从过去几年的商业化落地情况来看,算法的碎片化、场景个性化等等严重的问题导致了人工智能解决方案在工程化落地和市场化推广方面的局限性。但是,2017年以来,特别是2020年以后,以 Transformer为基础的各类大模型“霸占”各主要AI榜单的榜首,成为了名副其实的基础模型。基础大模型加上场景的小定制化越来越成为人工智能技术在商业化推广中的使用范式。
当然,也有很多人质疑Transformer的可解释性,也有人通过借鉴Transformer的思想反哺给CNN来进一步加速和提升,我们认为这都没有问题,用户更多地希望从准确率和效果上能有质的提升。CNN与Transformer在网络架构方面的竞争追根溯源是卷积操作与通用矩阵乘积操作这两种操作之争。处理CNN卷积操作时,专用硬件架构有发挥空间,这也就是之前大家所熟知的为算法和应用而定制的AI加速器出现的原因;而随着以GEMM为特征的Transformer网络架构的推广和规模化应用场景的挖掘,处理GEMM操作的较通用处理器可能更适合。当然两种方向会长期存在,但最终以能效和成本为目标的客户应用来说,通用硬件架构更有可能带来降本增效的效果。
对于Transformer的出现,我们认为其意义重大的原因更多地在于,Transformer为算法工作者提供了一种新的思想和思路方式,在大数据训练的情况下采用分布式的架构更适合当下人工智能算法的发展。
黑芝麻智能华山系列芯片采用多核异构架构
我们从以下三个维度进行阐述我们认为的下一代人工智能基础设施的发展方向:
Heterogeneous DSA是未来异构计算的主流。
当前的计算架构正在由单一的体系架构往异构的架构发展、由单一芯片模式往融合异构多芯片模式发展。软硬件融合、异构是当前体系结构发展的关键技术。
软硬件融合是必然带来以DSA为基础的异构计算的繁荣。除了芯片和体系结构之外,编译器、运行系统、编程语言等软件系统也面临着DSA带来的技术迭代周期。
随着应用场景的复杂性和异构计算技术的发展,我们需要解决以下四类问题:
1、 海量数据的高效处理:
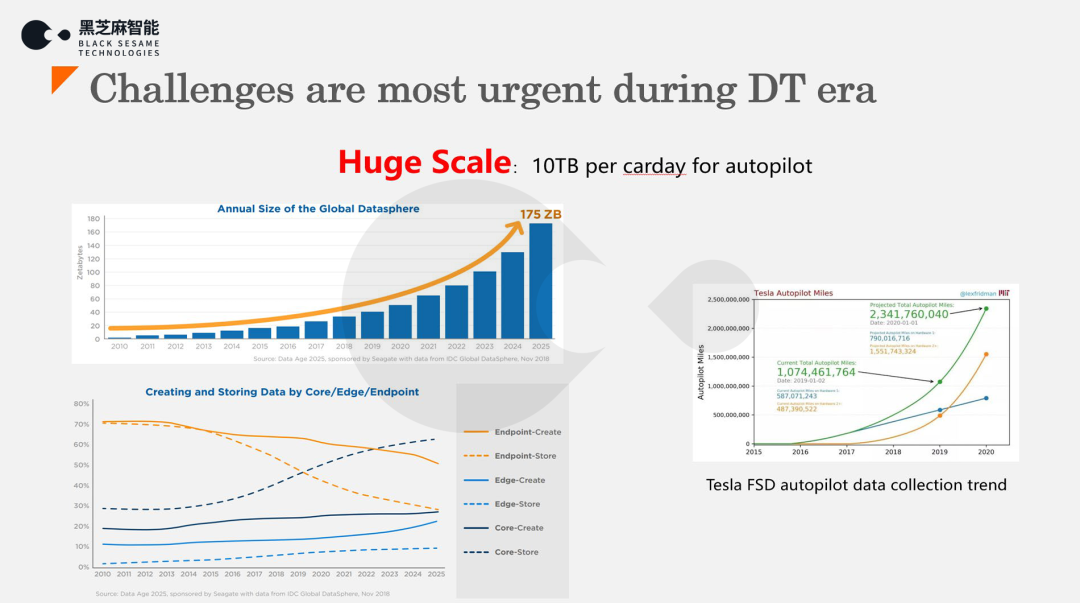
2、 复杂数据的有效处理:

3、 海量计算的范式创新和提升:
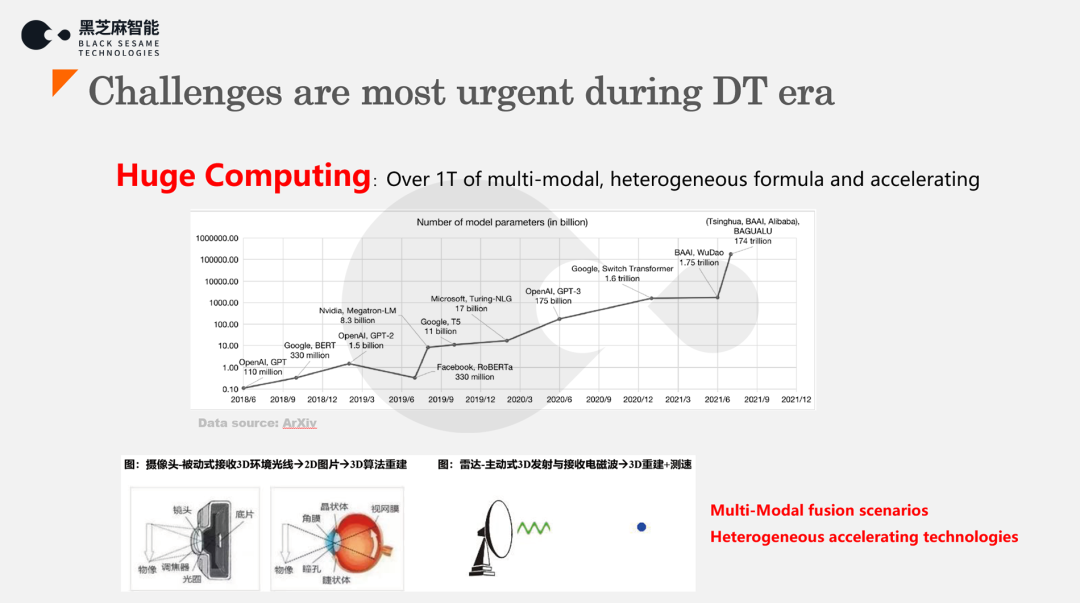
4、 高价值数据的识别与价值变现:

黑芝麻智能两大核心自研IP——车规级图像处理器NeuralIQ ISP以及DynamAI NN车规级低功耗神经网络加速引擎,赋能汽车看得更清、更远、更懂。其中,NeuralIQ ISP可支持多达12路高清相机接入。每秒处理36亿3曝光像素,12亿单曝光像素的高处理率管道,并且每个管道可并行在线处理两路视频,支持在线、离线和混合处理模式。支持HDR处理,符合高动态曝光、低光降噪、LED闪烁抑制等高质量车规图像处理要求,适用于智能驾驶环视感知、前视感知、驾驶监控等应用场景;DynamAI NN引擎具备大算力的架构,支持多形态、多精度运算。通过可适配量化、结构化剪裁压缩、硬件可执行软件的子图规划实现软硬件同步优化。支持稀疏加速和配备自动化开发工具等优势。
黑芝麻智能自动驾驶计算芯片SoC集成了多个加速器,有ARM、ARM Neon、GPU、NPU、DSP、ISP、VPU 等多个IP。NPU是主要用来处理AI相关workload的加速器,衡量一个NPU芯片的设计是否优化,业界有三个认可的设计原则:
1) 存储层次化
2) 数据复用
3) 片上互联
黑芝麻智能A1000芯片在设计层面已经充分地将以上三点融合并实现在SoC芯片内,包含多级缓存和数据存储结构、高效的数据复用逻辑、统一片上NoC互联结构将主要的IP进行并联等。
我们坚定地认为DSA架构和软件系统是更适合当前应用的思想和方法。充分融合DSA的思想、结合具体的领域场景,才可以构建出面向该领域的通用计算架构、高性能计算模型、高效的数据处理方式,才真正地让用户摆脱算力瓶颈、增强用户体验。
建设易用的以CXE为基础的人工智能软件基础设施是AI落地的关键
软件系统和工具链体系是量产化芯片走向成功的两个极为重要的因素。而AI工具集体系和人工智能平台是AI芯片最重要的软件系统。能否充分发挥AI芯片的性能和能效是判断AI工具集体系优劣的很重要的指标。黑芝麻智能构建了面向AI芯片的工具集系统和人工智能平台:山海人工智能开发平台,如下图所示:
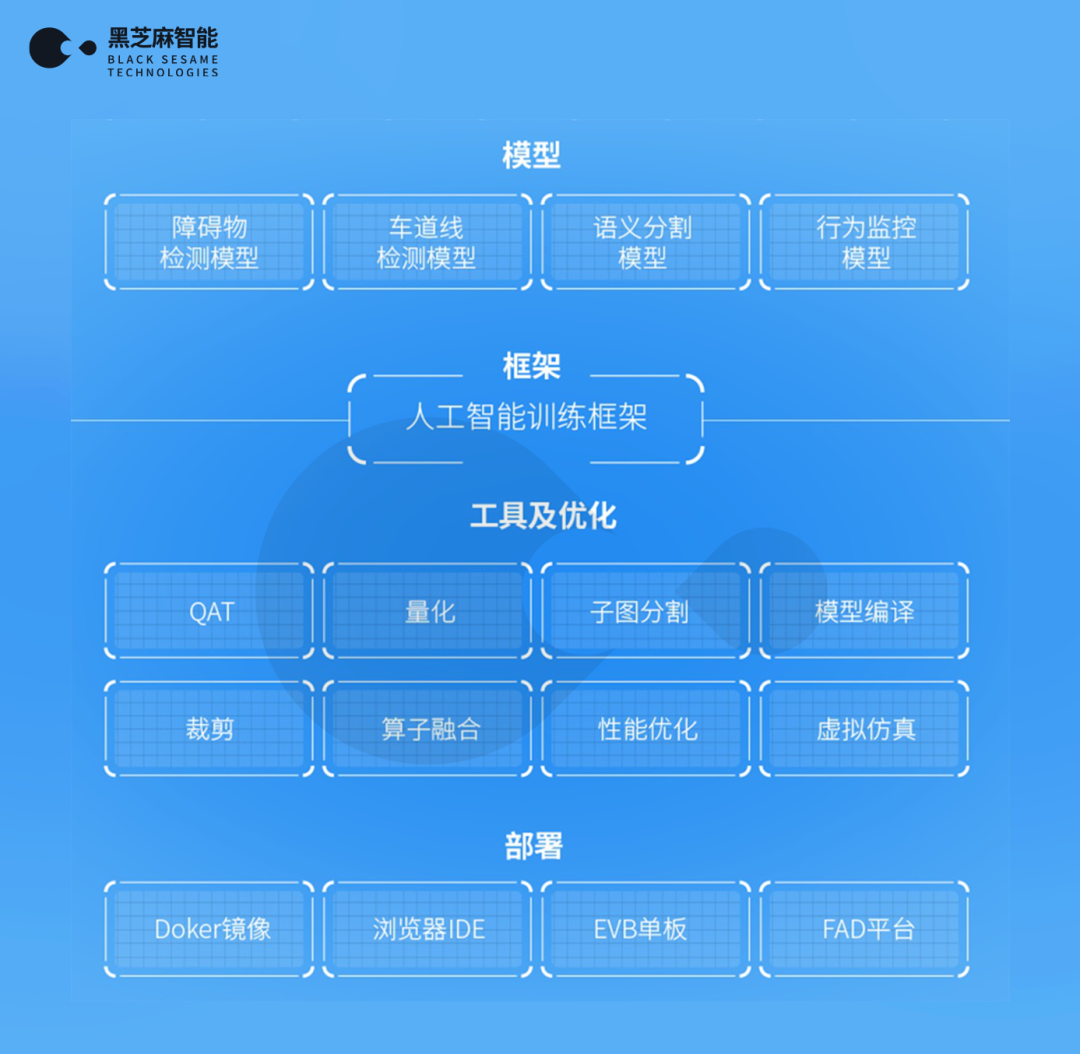
基于我们对行业knowhow的理解、对技术创新的信心,我们构建了面向异构加速计算平台的软件基础设施:CXE(Compiler and eXecution Environment)。这解决了三个问题:
1. 数据处理需求与算力能力之间的不平衡
2. 数据处理格式与异构计算体系架构的不一致
3. 融合计算在模型正确性和数学一致性方面的统一,如人工智能计算、工程计算等
CXE 系统升级了AI工具链和优化系统、人工智能训练系统等基础软件。
以自动驾驶应用场景为例:
我们基于底层的硬件平台,可能是CPU(如 ARM、X86、RISC-V等)、GPU、DSP、NPU、ISP等等处理器或异构加速器,构建了面向人工智能和技术领域的以MLIR为基础的人工智能编译器系统、分布式调度机制为基础的实时推理系统和运行时系统、融合了可解释性为条件的分布式训练和构建系统、可观测可验证可调试的辅助工具集合,这构成了以DSA为基础的下一代人工智能基础架构和平台。
打造非欧数据形式的融合算法模型是自动驾驶技术稳定产业化的基础
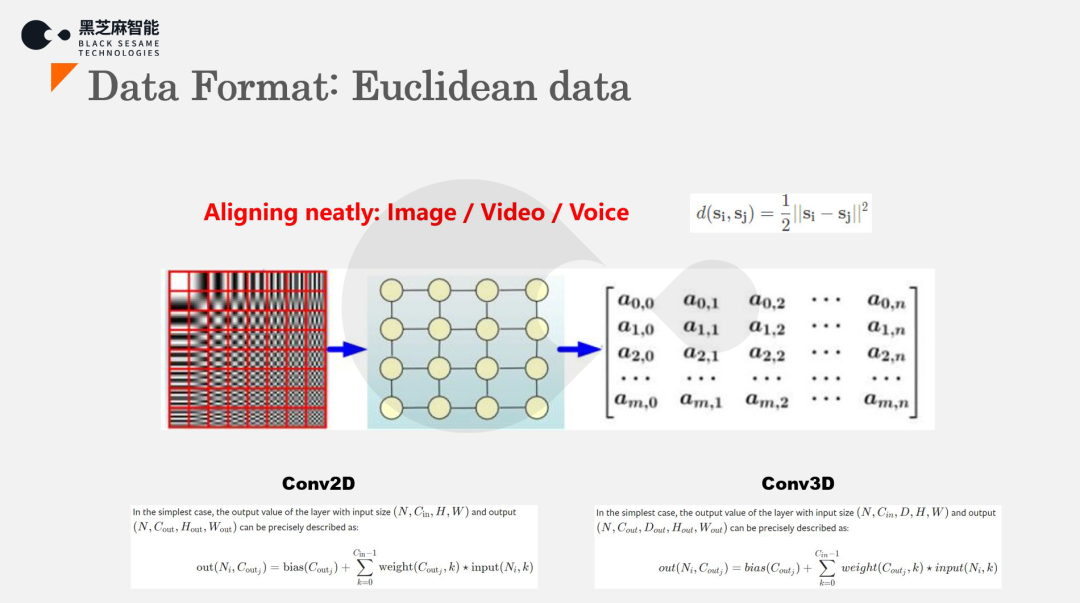
在过去几十年的发展历程中,人工智能技术主要解决的是以欧几里得空间的数据形式的处理问题:
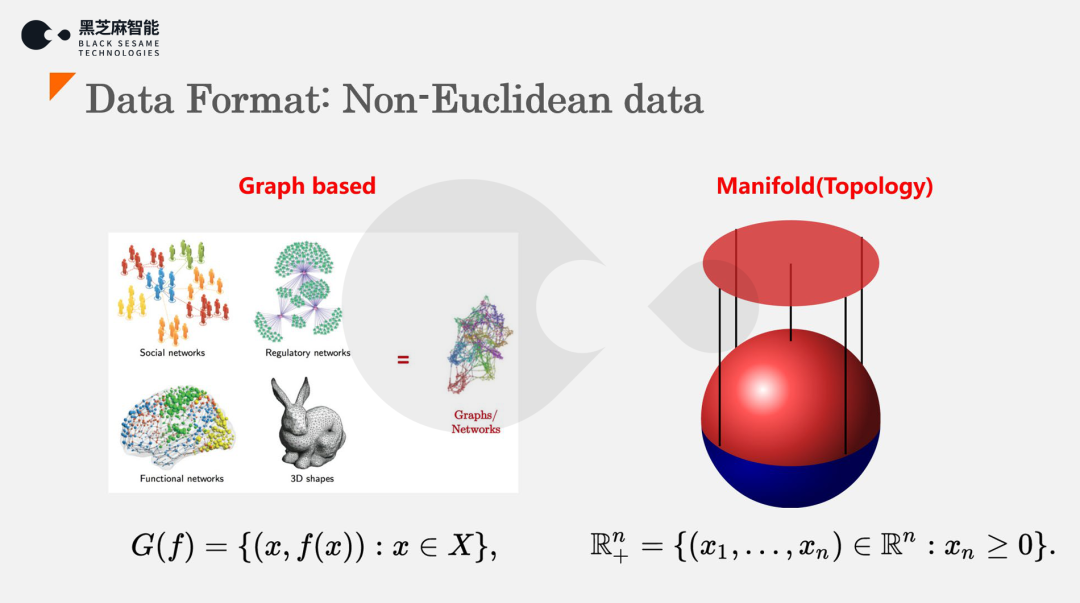
而物理世界和更广泛的数据处理是非欧空间的数据处理问题:
为了更好地解决自动驾驶、机器智能的工程化问题和领域知识的智能化泛化问题,我们还需要解决计算密集型的工程数学和以强化学习为方向的Simulation的技术闭环问题。


由此可见,我们基于MLIR等框架构建了我们自控的编译器/优化器和运行时系统,不仅支持AI workload相关的内存密集型的计算场景,而且支持如OpenCV、Halide等面向工业场景的计算密集型场景,还在图优化领域支持静态图的编译和高效转换,正在对动态图的处理进一步优化。未来在多复杂度数据处理场景、分布式计算场景、人工智能场景、边缘计算领域等多个交叉和融合的领域内,将会产生更大的价值和现实意义。
“工欲善其事、必先利其器”。我们坚信,好的工具是构建基础理论、验证现实问题的至关重要的手段。通过构建先进的人工智能基础设施和软件系统,技术人员不仅可以高效完成人工智能场景化解决方案,而且还可以产生创新的灵感,创造性地完成新的场景、新的算法等,又可以解决有限时间下的工程交付需求。
开发工具链是否完善是体现黑芝麻智能芯片易用性的重要指标。配合华山系列自动驾驶计算芯片,黑芝麻智能发布的山海人工智能开发平台。它拥有50多种AI参考模型库转换用例,降低客户的算法开发门槛;能够实现QAT和训练后量化的综合优化,保障算法模型精度;支持动态异构多核任务分配,同时还支持客户自定义算子开发,完善的工具链开发包及应用支持,能够助力客户快速移植模型和部署落地的一体化流程。
审核编辑:汤梓红











 工商网监
工商网监
评论